 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroscience-inspired perception-action in robotics: applying active inference for state estimation, control and self-perception
May 10, 2021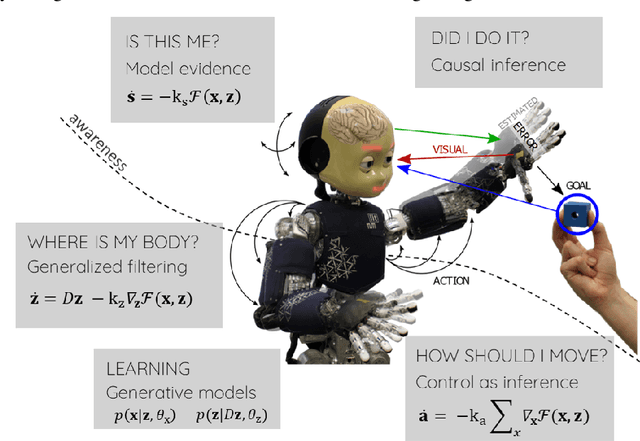
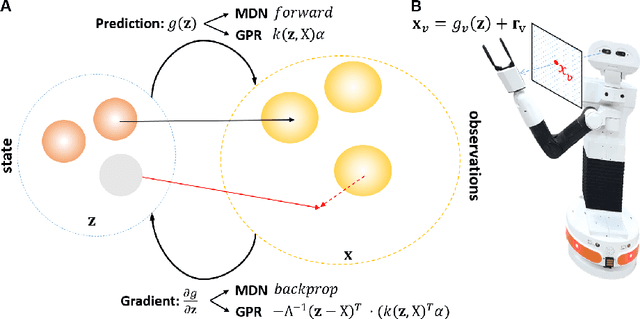
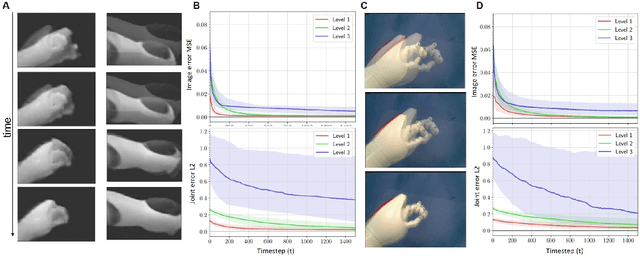
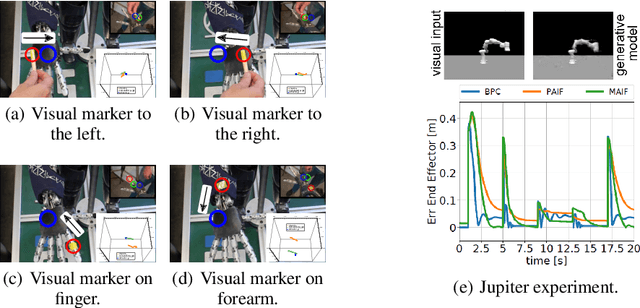
Unlike robots, humans learn, adapt and perceive their bodies by interacting with the world. Discovering how the brain represents the body and generates actions is of major importance for robotics and artificial intelligence. Here we discuss how neuroscience findings open up opportunities to improve current estimation and control algorithms in robotics. In particular, how active inference, a mathematical formulation of how the brain resists a natural tendency to disorder, provides a unified recipe to potentially solve some of the major challenges in robotics, such as adaptation, robustness, flexibility, generalization and safe interaction. This paper summarizes some experiments and lessons learned from developing such a computational model on real embodied platforms, i.e., humanoid and industrial robots. Finally, we showcase the limitations and challenges that we are still facing to give robots human-like perception
Scaling up learning with GAIT-prop
Feb 23, 2021
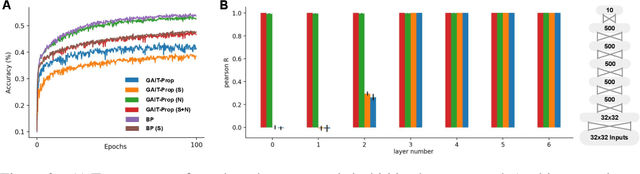
Backpropagation of error (BP) is a widely used and highly successful learning algorithm. However, its reliance on non-local information in propagating error gradients makes it seem an unlikely candidate for learning in the brain. In the last decade, a number of investigations have been carried out focused upon determining whether alternative more biologically plausible computations can be used to approximate BP. This work builds on such a local learning algorithm - Gradient Adjusted Incremental Target Propagation (GAIT-prop) - which has recently been shown to approximate BP in a manner which appears biologically plausible. This method constructs local, layer-wise weight update targets in order to enable plausible credit assignment. However, in deep networks, the local weight updates computed by GAIT-prop can deviate from BP for a number of reasons. Here, we provide and test methods to overcome such sources of error. In particular, we adaptively rescale the locally-computed errors and show that this significantly increases the performance and stability of the GAIT-prop algorithm when applied to the CIFAR-10 dataset.
Automatic variational inference with cascading flows
Feb 09, 2021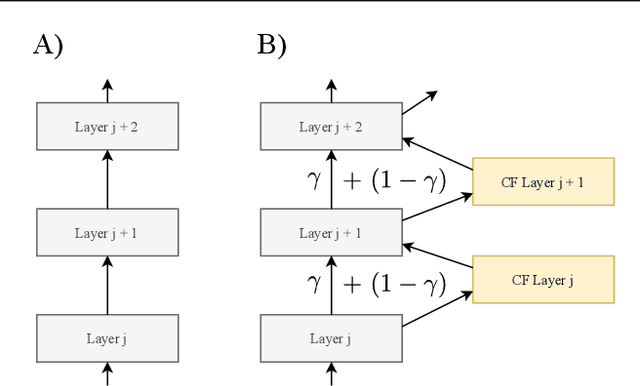
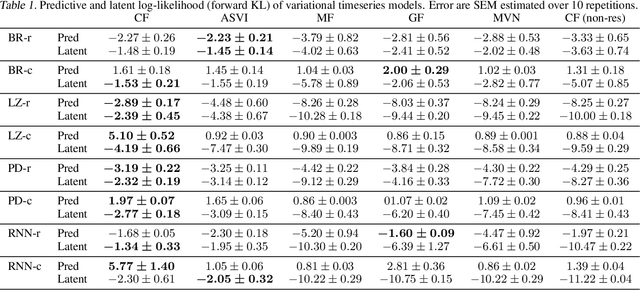
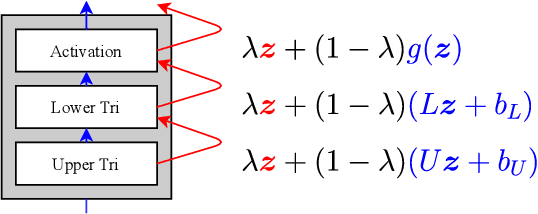

The automation of probabilistic reasoning is one of the primary aims of machine learning. Recently, the confluence of variational inference and deep learning has led to powerful and flexible automatic inference methods that can be trained by stochastic gradient descent. In particular, normalizing flows are highly parameterized deep models that can fit arbitrarily complex posterior densities. However, normalizing flows struggle in highly structured probabilistic programs as they need to relearn the forward-pass of the program. Automatic structured variational inference (ASVI) remedies this problem by constructing variational programs that embed the forward-pass. Here, we combine the flexibility of normalizing flows and the prior-embedding property of ASVI in a new family of variational programs, which we named cascading flows. A cascading flows program interposes a newly designed highway flow architecture in between the conditional distributions of the prior program such as to steer it toward the observed data. These programs can be constructed automatically from an input probabilistic program and can also be amortized automatically. We evaluate the performance of the new variational programs in a series of structured inference problems. We find that cascading flows have much higher performance than both normalizing flows and ASVI in a large set of structured inference problems.
A deep active inference model of the rubber-hand illusion
Aug 17, 2020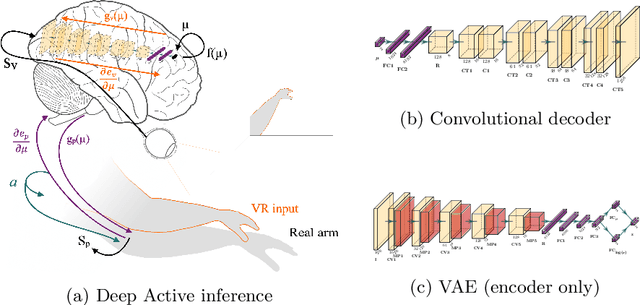
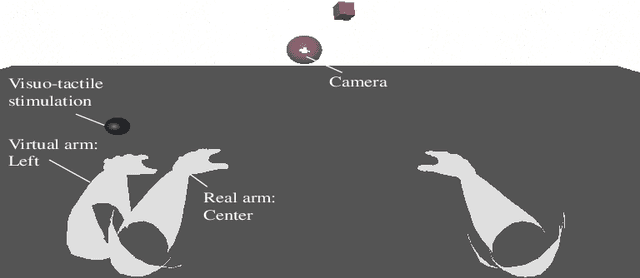
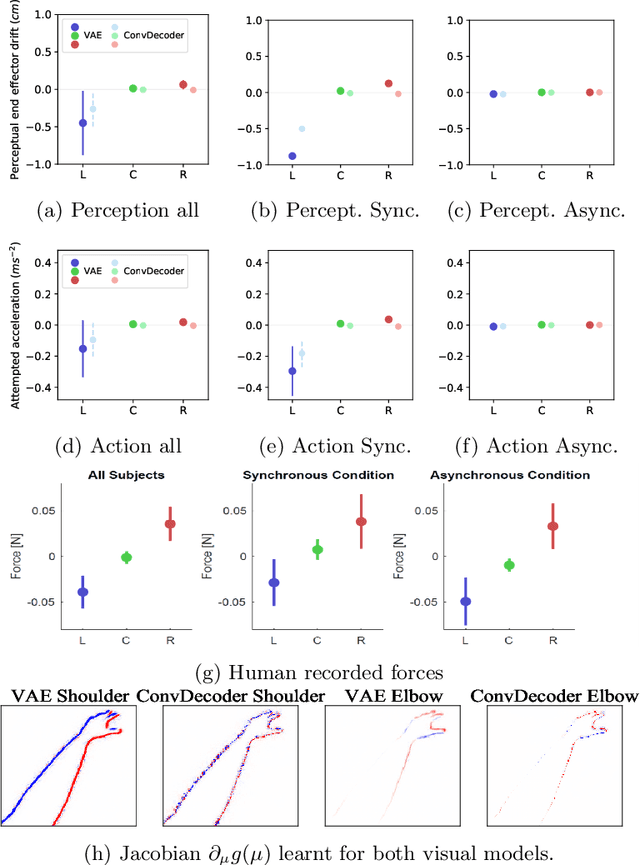
Understanding how perception and action deal with sensorimotor conflicts, such as the rubber-hand illusion (RHI), is essential to understand how the body adapts to uncertain situations. Recent results in humans have shown that the RHI not only produces a change in the perceived arm location, but also causes involuntary forces. Here, we describe a deep active inference agent in a virtual environment, which we subjected to the RHI, that is able to account for these results. We show that our model, which deals with visual high-dimensional inputs, produces similar perceptual and force patterns to those found in humans.
Explainable Deep Learning: A Field Guide for the Uninitiated
Apr 30, 2020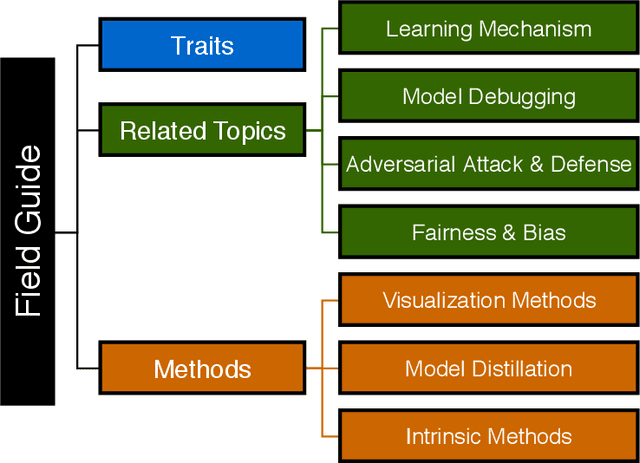

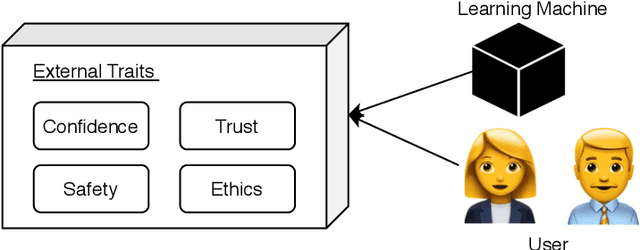

Deep neural network (DNN) is an indispensable machine learning tool for achieving human-level performance on many learning tasks. Yet, due to its black-box nature, it is inherently difficult to understand which aspects of the input data drive the decisions of the network. There are various real-world scenarios in which humans need to make actionable decisions based on the output DNNs. Such decision support systems can be found in critical domains, such as legislation, law enforcement, etc. It is important that the humans making high-level decisions can be sure that the DNN decisions are driven by combinations of data features that are appropriate in the context of the deployment of the decision support system and that the decisions made are legally or ethically defensible. Due to the incredible pace at which DNN technology is being developed, the development of new methods and studies on explaining the decision-making process of DNNs has blossomed into an active research field. A practitioner beginning to study explainable deep learning may be intimidated by the plethora of orthogonal directions the field is taking. This complexity is further exacerbated by the general confusion that exists in defining what it means to be able to explain the actions of a deep learning system and to evaluate a system's "ability to explain". To alleviate this problem, this article offers a "field guide" to deep learning explainability for those uninitiated in the field. The field guide: i) Discusses the traits of a deep learning system that researchers enhance in explainability research, ii) places explainability in the context of other related deep learning research areas, and iii) introduces three simple dimensions defining the space of foundational methods that contribute to explainable deep learning. The guide is designed as an easy-to-digest starting point for those just embarking in the field.
Virtual staining for mitosis detection in Breast Histopathology
Mar 17, 2020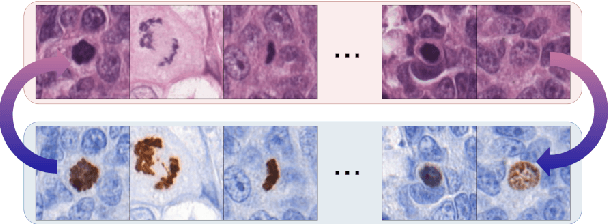
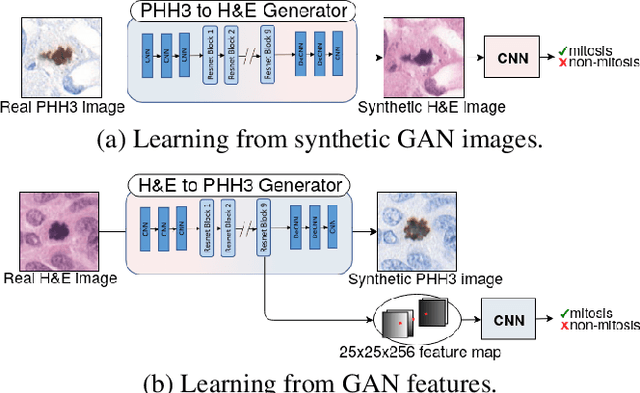
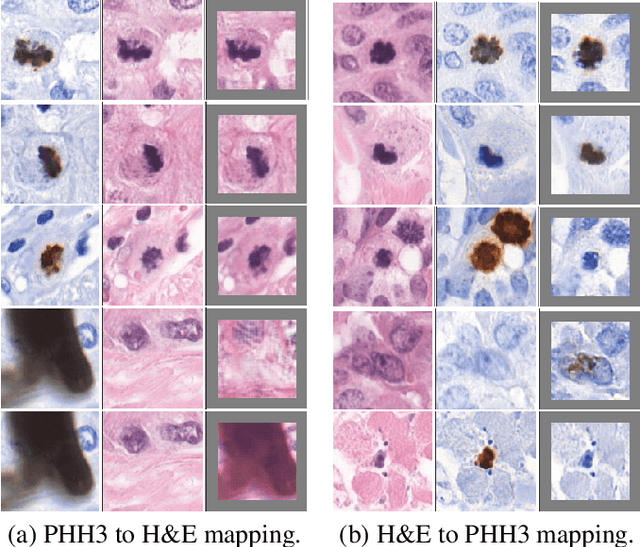
We propose a virtual staining methodology based on Generative Adversarial Networks to map histopathology images of breast cancer tissue from H&E stain to PHH3 and vice versa. We use the resulting synthetic images to build Convolutional Neural Networks (CNN) for automatic detection of mitotic figures, a strong prognostic biomarker used in routine breast cancer diagnosis and grading. We propose several scenarios, in which CNN trained with synthetically generated histopathology images perform on par with or even better than the same baseline model trained with real images. We discuss the potential of this application to scale the number of training samples without the need for manual annotations.
Automatic structured variational inference
Feb 03, 2020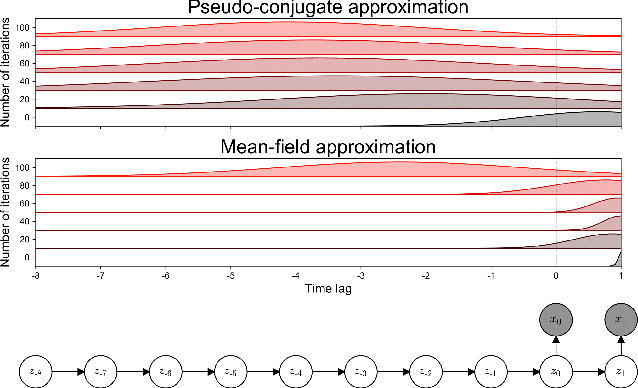

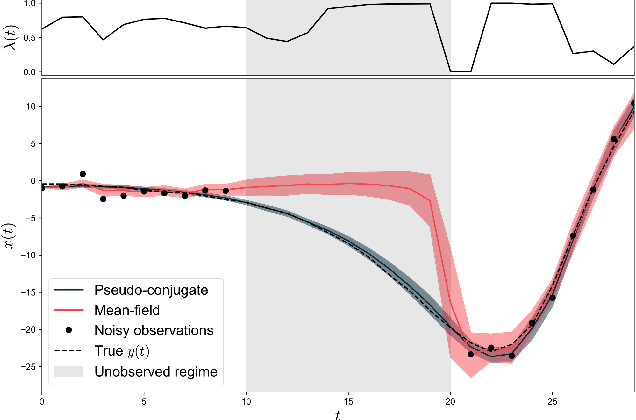
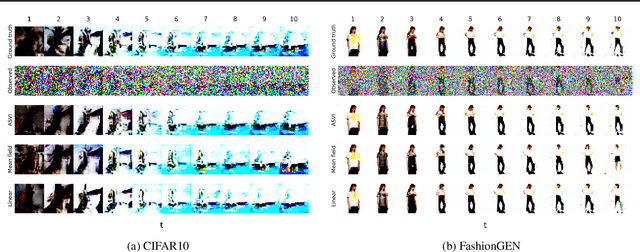
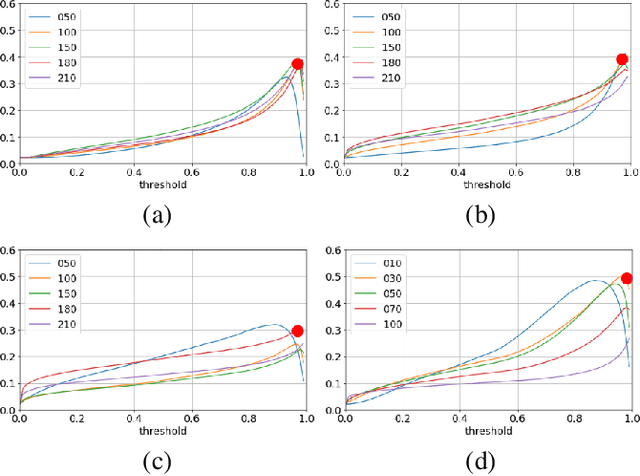
The aim of probabilistic programming is to automatize every aspect of probabilistic inference in arbitrary probabilistic models (programs) so that the user can focus her attention on modeling, without dealing with ad-hoc inference methods. Gradient based automatic differentiation stochastic variational inference offers an attractive option as the default method for (differentiable) probabilistic programming as it combines high performance with high computational efficiency. However, the performance of any (parametric) variational approach depends on the choice of an appropriate variational family. Here, we introduced a fully automatic method for constructing structured variational families inspired to the closed-form update in conjugate models. These pseudo-conjugate families incorporate the forward pass of the input probabilistic program and can capture complex statistical dependencies. Pseudo-conjugate families have the same space and time complexity of the input probabilistic program and are therefore tractable in a very large class of models. We validate our automatic variational method on a wide range of high dimensional inference problems including deep learning components.
The Indian Chefs Process
Jan 29, 2020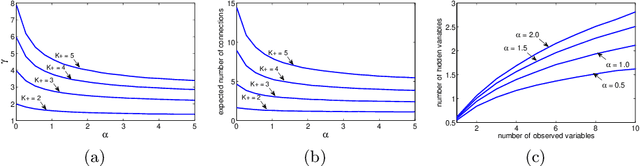


This paper introduces the Indian Chefs Process (ICP), a Bayesian nonparametric prior on the joint space of infinite directed acyclic graphs (DAGs) and orders that generalizes Indian Buffet Processes. As our construction shows, the proposed distribution relies on a latent Beta Process controlling both the orders and outgoing connection probabilities of the nodes, and yields a probability distribution on sparse infinite graphs. The main advantage of the ICP over previously proposed Bayesian nonparametric priors for DAG structures is its greater flexibility. To the best of our knowledge, the ICP is the first Bayesian nonparametric model supporting every possible DAG. We demonstrate the usefulness of the ICP on learning the structure of deep generative sigmoid networks as well as convolutional neural networks.
k-GANs: Ensemble of Generative Models with Semi-Discrete Optimal Transport
Jul 09, 2019
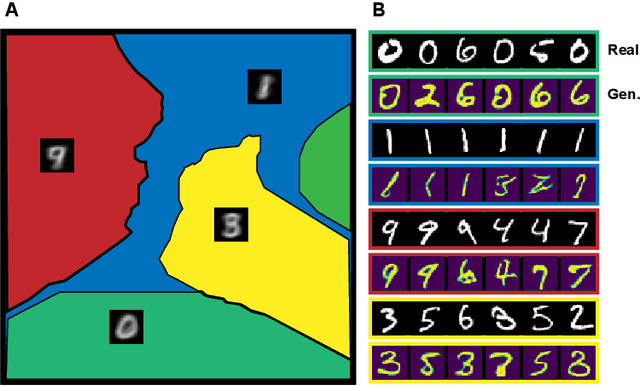

Generative adversarial networks (GANs) are the state of the art in generative modeling. Unfortunately, most GAN methods are susceptible to mode collapse, meaning that they tend to capture only a subset of the modes of the true distribution. A possible way of dealing with this problem is to use an ensemble of GANs, where (ideally) each network models a single mode. In this paper, we introduce a principled method for training an ensemble of GANs using semi-discrete optimal transport theory. In our approach, each generative network models the transportation map between a point mass (Dirac measure) and the restriction of the data distribution on a tile of a Voronoi tessellation that is defined by the location of the point masses. We iteratively train the generative networks and the point masses until convergence. The resulting k-GANs algorithm has strong theoretical connection with the k-medoids algorithm. In our experiments, we show that our ensemble method consistently outperforms baseline GANs.
The functional role of cue-driven feature-based feedback in object recognition
Mar 25, 2019
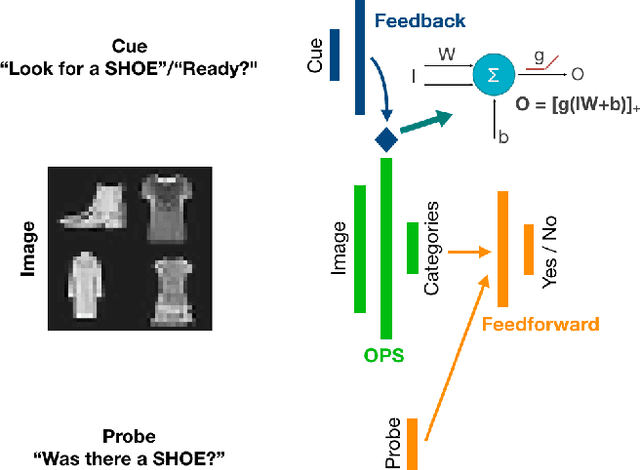
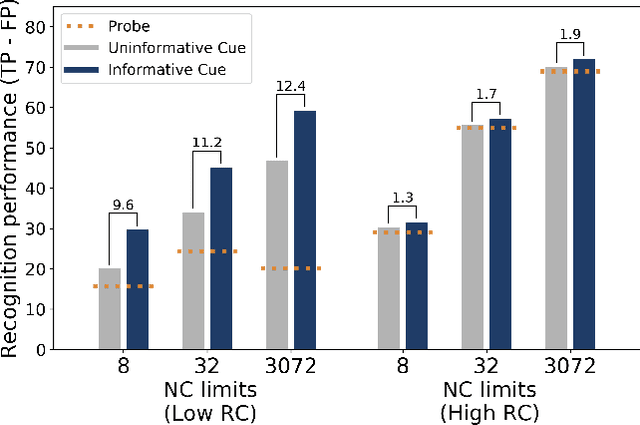
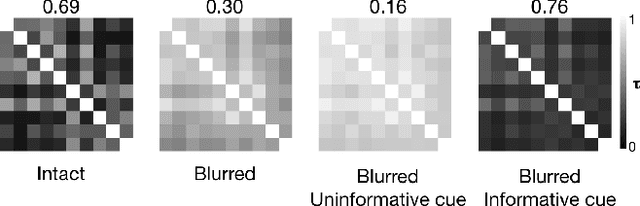
Visual object recognition is not a trivial task, especially when the objects are degraded or surrounded by clutter or presented briefly. External cues (such as verbal cues or visual context) can boost recognition performance in such conditions. In this work, we build an artificial neural network to model the interaction between the object processing stream (OPS) and the cue. We study the effects of varying neural and representational capacities of the OPS on the performance boost provided by cue-driven feature-based feedback in the OPS. We observe that the feedback provides performance boosts only if the category-specific features about the objects cannot be fully represented in the OPS. This representational limit is more dependent on task demands than neural capacity. We also observe that the feedback scheme trained to maximise recognition performance boost is not the same as tuning-based feedback, and actually performs better than tuning-based feedback.