 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmoothness-Based Derandomization of PAC-Bayes Bounds
Jun 17, 2026We study PAC-Bayes derandomization for smooth loss functions. Our goal is to obtain generalization bounds that hold with high probability for deterministic predictors by exploiting smoothness properties of both the loss and the predictor class. We show that passing from the Gibbs predictor to the deterministic predictor at the posterior mean has a precise cost, given by the generalization gap of the Jensen gap class. We control this class through its Rademacher complexity, leading to bounds for deterministic predictors that involve flatness quantities expressed in terms of parameter Jacobians and Hessians of the score map. The framework applies to both bounded and unbounded smooth loss functions, and we specialize the results to linear predictors and smooth neural networks. Finally, the Jacobian and Hessian quantities appearing in the theory motivate a practical regularizer. For BatchNorm networks, we compute this regularizer with respect to effective BatchNorm weights obtained by folding the BatchNorm transformation into the adjacent affine weights. Experiments on CIFAR-10 illustrate the behavior of this regularizer under different batch sizes.
Symmetrization of Loss Functions for Robust Training of Neural Networks in the Presence of Noisy Labels
May 19, 2026Labeling a training set is often expensive and susceptible to errors, making the design of robust loss functions for label noise an important problem. The symmetry condition provides theoretical guarantees for robustness to such noise. In this work, we study a symmetrization method arising from the unique decomposition of any multi-class loss function into a symmetric component and a class-insensitive term. In particular, symmetrizing the cross-entropy loss leads to a linear multi-class extension of the unhinged loss. Unlike in the binary case, the multi-class version must have specific coefficients in order to satisfy the symmetry condition. Under suitable assumptions, we show that this multi-class unhinged loss is the unique convex multi-class symmetric loss. We also show that it has a fundamental local role: the linear approximation of any symmetric loss around score vectors with equal components is equivalent to the multi-class unhinged loss. We then introduce SGCE and alpha-MAE, two loss functions that interpolate between the multi-class unhinged loss and the Mean Absolute Error while allowing control of the beta-smoothness of the loss. Experiments on standard noisy-label benchmarks show competitive performance compared with existing robust loss functions.
The Indian Chefs Process
Jan 29, 2020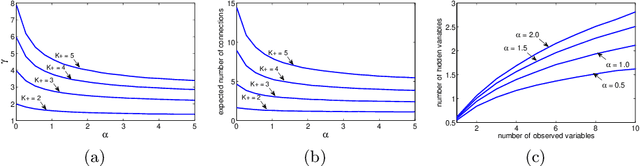


This paper introduces the Indian Chefs Process (ICP), a Bayesian nonparametric prior on the joint space of infinite directed acyclic graphs (DAGs) and orders that generalizes Indian Buffet Processes. As our construction shows, the proposed distribution relies on a latent Beta Process controlling both the orders and outgoing connection probabilities of the nodes, and yields a probability distribution on sparse infinite graphs. The main advantage of the ICP over previously proposed Bayesian nonparametric priors for DAG structures is its greater flexibility. To the best of our knowledge, the ICP is the first Bayesian nonparametric model supporting every possible DAG. We demonstrate the usefulness of the ICP on learning the structure of deep generative sigmoid networks as well as convolutional neural networks.