 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Visual Question Answering Models through Robustness Analysis and In-Context Learning with a Chain of Basic Questions
Apr 06, 2023



Deep neural networks have been critical in the task of Visual Question Answering (VQA), with research traditionally focused on improving model accuracy. Recently, however, there has been a trend towards evaluating the robustness of these models against adversarial attacks. This involves assessing the accuracy of VQA models under increasing levels of noise in the input, which can target either the image or the proposed query question, dubbed the main question. However, there is currently a lack of proper analysis of this aspect of VQA. This work proposes a new method that utilizes semantically related questions, referred to as basic questions, acting as noise to evaluate the robustness of VQA models. It is hypothesized that as the similarity of a basic question to the main question decreases, the level of noise increases. To generate a reasonable noise level for a given main question, a pool of basic questions is ranked based on their similarity to the main question, and this ranking problem is cast as a LASSO optimization problem. Additionally, this work proposes a novel robustness measure, R_score, and two basic question datasets to standardize the analysis of VQA model robustness. The experimental results demonstrate that the proposed evaluation method effectively analyzes the robustness of VQA models. Moreover, the experiments show that in-context learning with a chain of basic questions can enhance model accuracy.
Open-Ended Medical Visual Question Answering Through Prefix Tuning of Language Models
Mar 10, 2023



Medical Visual Question Answering (VQA) is an important challenge, as it would lead to faster and more accurate diagnoses and treatment decisions. Most existing methods approach it as a multi-class classification problem, which restricts the outcome to a predefined closed-set of curated answers. We focus on open-ended VQA and motivated by the recent advances in language models consider it as a generative task. Leveraging pre-trained language models, we introduce a novel method particularly suited for small, domain-specific, medical datasets. To properly communicate the medical images to the language model, we develop a network that maps the extracted visual features to a set of learnable tokens. Then, alongside the question, these learnable tokens directly prompt the language model. We explore recent parameter-efficient fine-tuning strategies for language models, which allow for resource- and data-efficient fine-tuning. We evaluate our approach on the prime medical VQA benchmarks, namely, Slake, OVQA and PathVQA. The results demonstrate that our approach outperforms existing methods across various training settings while also being computationally efficient.
Meta Learning to Bridge Vision and Language Models for Multimodal Few-Shot Learning
Feb 28, 2023



Multimodal few-shot learning is challenging due to the large domain gap between vision and language modalities. Existing methods are trying to communicate visual concepts as prompts to frozen language models, but rely on hand-engineered task induction to reduce the hypothesis space. To make the whole process learnable, we introduce a multimodal meta-learning approach. Specifically, our approach decomposes the training of the model into a set of related multimodal few-shot tasks. We define a meta-mapper network, acting as a meta-learner, to efficiently bridge frozen large-scale vision and language models and leverage their already learned capacity. By updating the learnable parameters only of the meta-mapper, it learns to accrue shared meta-knowledge among these tasks. Thus, it can rapidly adapt to newly presented samples with only a few gradient updates. Importantly, it induces the task in a completely data-driven manner, with no need for a hand-engineered task induction. We evaluate our approach on recently proposed multimodal few-shot benchmarks, measuring how rapidly the model can bind novel visual concepts to words and answer visual questions by observing only a limited set of labeled examples. The experimental results show that our meta-learning approach outperforms the baseline across multiple datasets and various training settings while being computationally more efficient.
X-TRA: Improving Chest X-ray Tasks with Cross-Modal Retrieval Augmentation
Feb 22, 2023



An important component of human analysis of medical images and their context is the ability to relate newly seen things to related instances in our memory. In this paper we mimic this ability by using multi-modal retrieval augmentation and apply it to several tasks in chest X-ray analysis. By retrieving similar images and/or radiology reports we expand and regularize the case at hand with additional knowledge, while maintaining factual knowledge consistency. The method consists of two components. First, vision and language modalities are aligned using a pre-trained CLIP model. To enforce that the retrieval focus will be on detailed disease-related content instead of global visual appearance it is fine-tuned using disease class information. Subsequently, we construct a non-parametric retrieval index, which reaches state-of-the-art retrieval levels. We use this index in our downstream tasks to augment image representations through multi-head attention for disease classification and report retrieval. We show that retrieval augmentation gives considerable improvements on these tasks. Our downstream report retrieval even shows to be competitive with dedicated report generation methods, paving the path for this method in medical imaging.
An Analytics of Culture: Modeling Subjectivity, Scalability, Contextuality, and Temporality
Nov 14, 2022There is a bidirectional relationship between culture and AI; AI models are increasingly used to analyse culture, thereby shaping our understanding of culture. On the other hand, the models are trained on collections of cultural artifacts thereby implicitly, and not always correctly, encoding expressions of culture. This creates a tension that both limits the use of AI for analysing culture and leads to problems in AI with respect to cultural complex issues such as bias. One approach to overcome this tension is to more extensively take into account the intricacies and complexities of culture. We structure our discussion using four concepts that guide humanistic inquiry into culture: subjectivity, scalability, contextuality, and temporality. We focus on these concepts because they have not yet been sufficiently represented in AI research. We believe that possible implementations of these aspects into AI research leads to AI that better captures the complexities of culture. In what follows, we briefly describe these four concepts and their absence in AI research. For each concept, we define possible research challenges.
Probabilistic Integration of Object Level Annotations in Chest X-ray Classification
Oct 13, 2022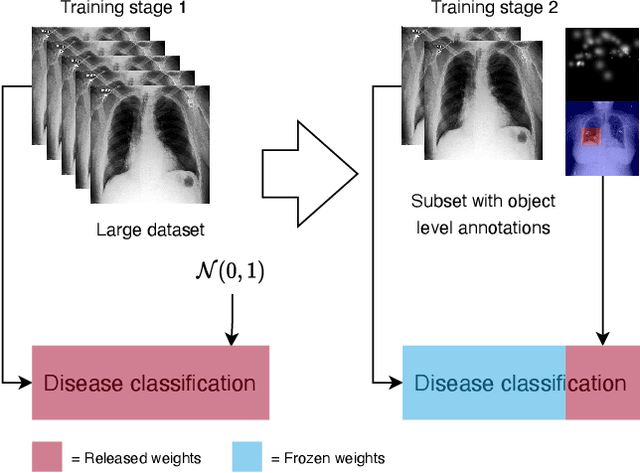
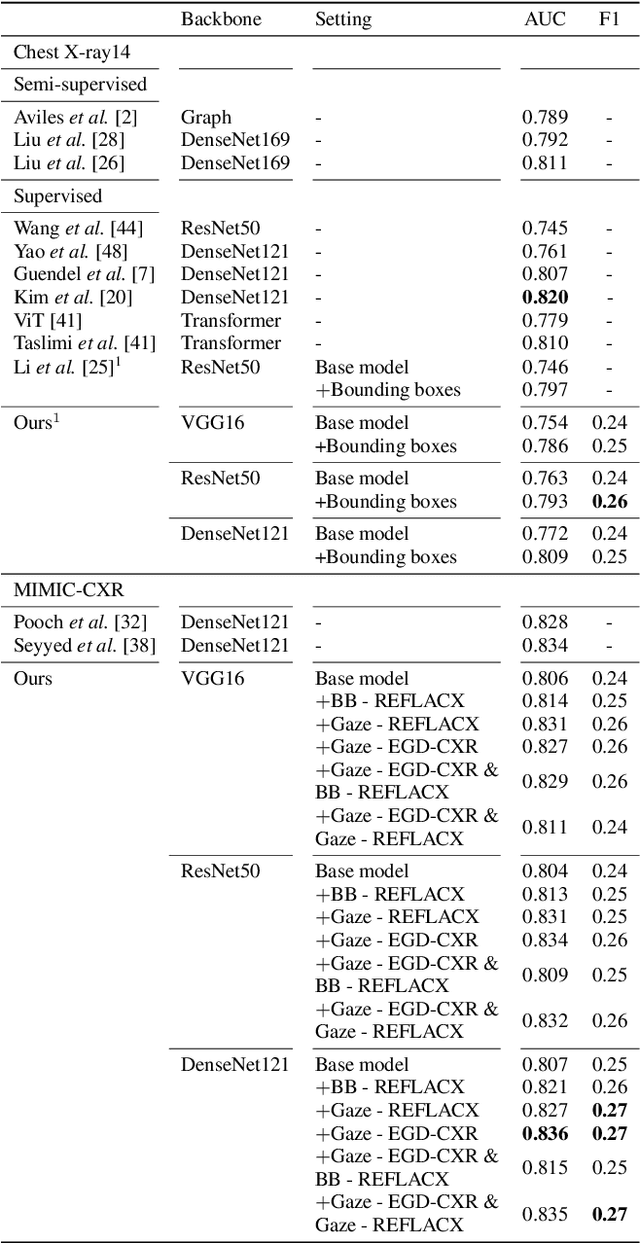
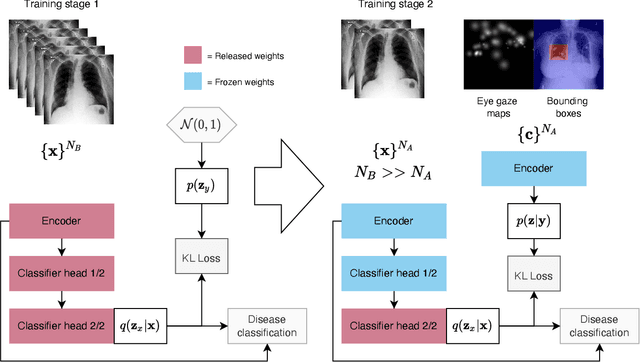
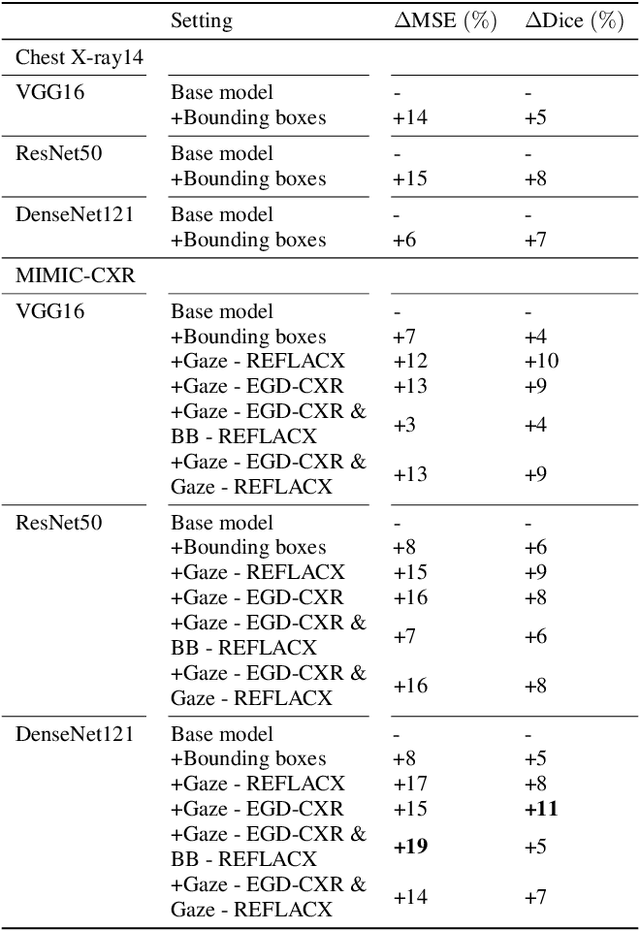
Medical image datasets and their annotations are not growing as fast as their equivalents in the general domain. This makes translation from the newest, more data-intensive methods that have made a large impact on the vision field increasingly more difficult and less efficient. In this paper, we propose a new probabilistic latent variable model for disease classification in chest X-ray images. Specifically we consider chest X-ray datasets that contain global disease labels, and for a smaller subset contain object level expert annotations in the form of eye gaze patterns and disease bounding boxes. We propose a two-stage optimization algorithm which is able to handle these different label granularities through a single training pipeline in a two-stage manner. In our pipeline global dataset features are learned in the lower level layers of the model. The specific details and nuances in the fine-grained expert object-level annotations are learned in the final layers of the model using a knowledge distillation method inspired by conditional variational inference. Subsequently, model weights are frozen to guide this learning process and prevent overfitting on the smaller richly annotated data subsets. The proposed method yields consistent classification improvement across different backbones on the common benchmark datasets Chest X-ray14 and MIMIC-CXR. This shows how two-stage learning of labels from coarse to fine-grained, in particular with object level annotations, is an effective method for more optimal annotation usage.
Association Graph Learning for Multi-Task Classification with Category Shifts
Oct 10, 2022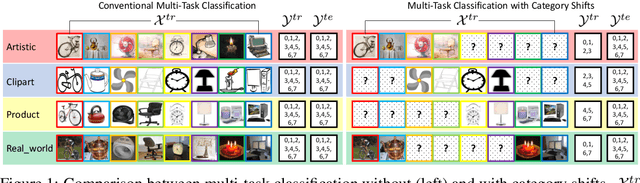

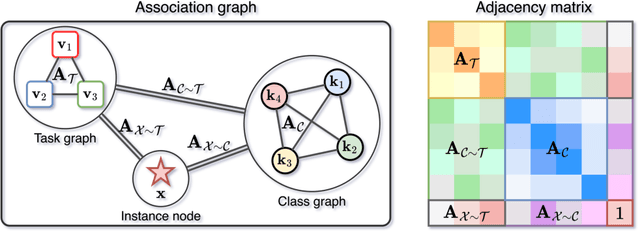
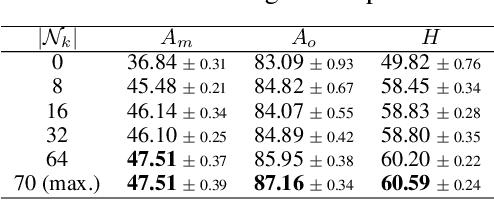
In this paper, we focus on multi-task classification, where related classification tasks share the same label space and are learned simultaneously. In particular, we tackle a new setting, which is more realistic than currently addressed in the literature, where categories shift from training to test data. Hence, individual tasks do not contain complete training data for the categories in the test set. To generalize to such test data, it is crucial for individual tasks to leverage knowledge from related tasks. To this end, we propose learning an association graph to transfer knowledge among tasks for missing classes. We construct the association graph with nodes representing tasks, classes and instances, and encode the relationships among the nodes in the edges to guide their mutual knowledge transfer. By message passing on the association graph, our model enhances the categorical information of each instance, making it more discriminative. To avoid spurious correlations between task and class nodes in the graph, we introduce an assignment entropy maximization that encourages each class node to balance its edge weights. This enables all tasks to fully utilize the categorical information from related tasks. An extensive evaluation on three general benchmarks and a medical dataset for skin lesion classification reveals that our method consistently performs better than representative baselines.
PanorAMS: Automatic Annotation for Detecting Objects in Urban Context
Aug 31, 2022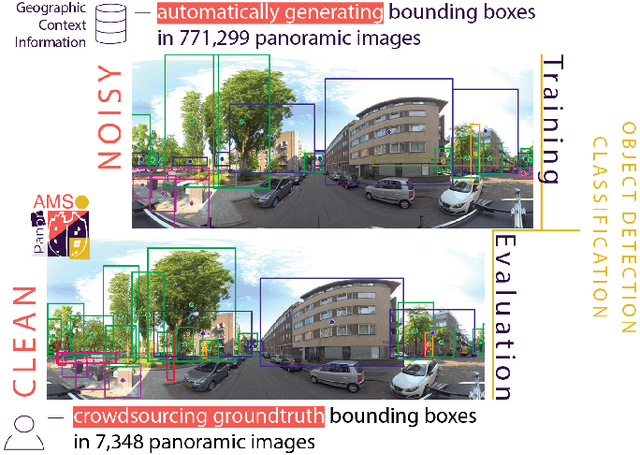

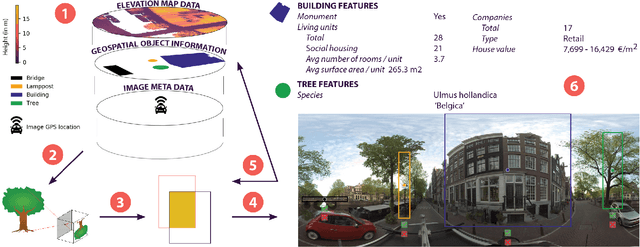
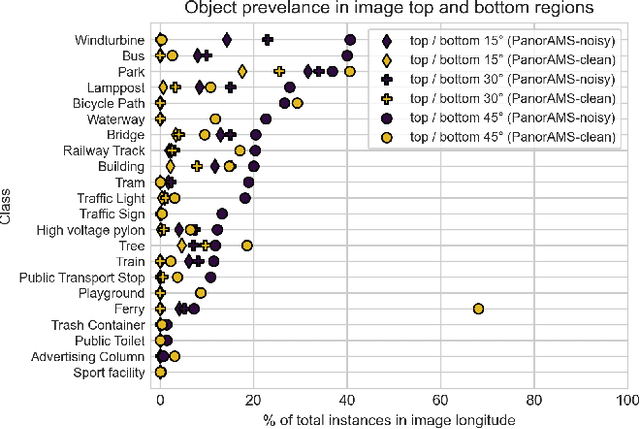
Large collections of geo-referenced panoramic images are freely available for cities across the globe, as well as detailed maps with location and meta-data on a great variety of urban objects. They provide a potentially rich source of information on urban objects, but manual annotation for object detection is costly, laborious and difficult. Can we utilize such multimedia sources to automatically annotate street level images as an inexpensive alternative to manual labeling? With the PanorAMS framework we introduce a method to automatically generate bounding box annotations for panoramic images based on urban context information. Following this method, we acquire large-scale, albeit noisy, annotations for an urban dataset solely from open data sources in a fast and automatic manner. The dataset covers the City of Amsterdam and includes over 14 million noisy bounding box annotations of 22 object categories present in 771,299 panoramic images. For many objects further fine-grained information is available, obtained from geospatial meta-data, such as building value, function and average surface area. Such information would have been difficult, if not impossible, to acquire via manual labeling based on the image alone. For detailed evaluation, we introduce an efficient crowdsourcing protocol for bounding box annotations in panoramic images, which we deploy to acquire 147,075 ground-truth object annotations for a subset of 7,348 images, the PanorAMS-clean dataset. For our PanorAMS-noisy dataset, we provide an extensive analysis of the noise and how different types of noise affect image classification and object detection performance. We make both datasets, PanorAMS-noisy and PanorAMS-clean, benchmarks and tools presented in this paper openly available.
LifeLonger: A Benchmark for Continual Disease Classification
Apr 12, 2022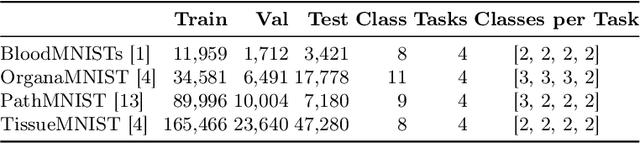
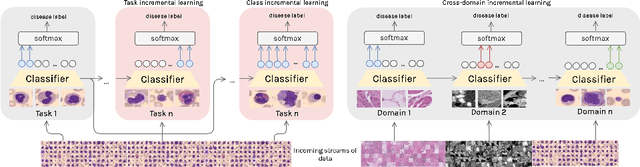
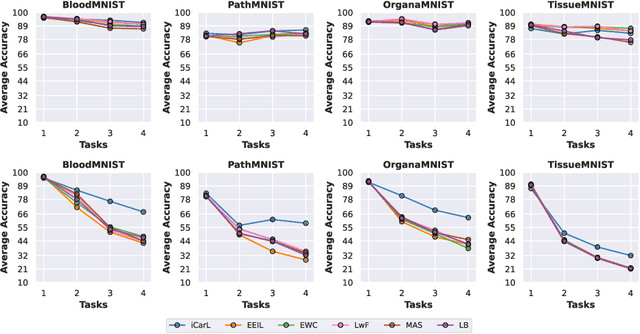
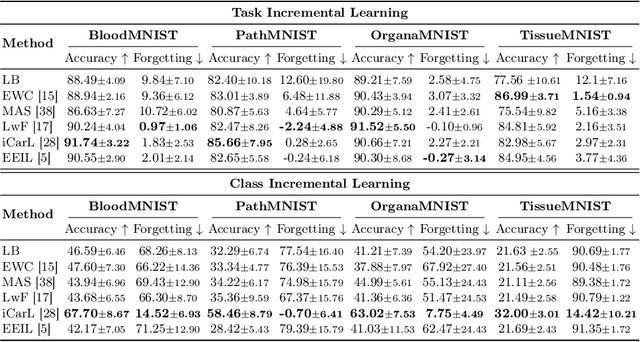
Deep learning models have shown a great effectiveness in recognition of findings in medical images. However, they cannot handle the ever-changing clinical environment, bringing newly annotated medical data from different sources. To exploit the incoming streams of data, these models would benefit largely from sequentially learning from new samples, without forgetting the previously obtained knowledge. In this paper we introduce LifeLonger, a benchmark for continual disease classification on the MedMNIST collection, by applying existing state-of-the-art continual learning methods. In particular, we consider three continual learning scenarios, namely, task and class incremental learning and the newly defined cross-domain incremental learning. Task and class incremental learning of diseases address the issue of classifying new samples without re-training the models from scratch, while cross-domain incremental learning addresses the issue of dealing with datasets originating from different institutions while retaining the previously obtained knowledge. We perform a thorough analysis of the performance and examine how the well-known challenges of continual learning, such as the catastrophic forgetting exhibit themselves in this setting. The encouraging results demonstrate that continual learning has a major potential to advance disease classification and to produce a more robust and efficient learning framework for clinical settings. The code repository, data partitions and baseline results for the complete benchmark will be made publicly available.
Multi-Task Neural Processes
Dec 02, 2021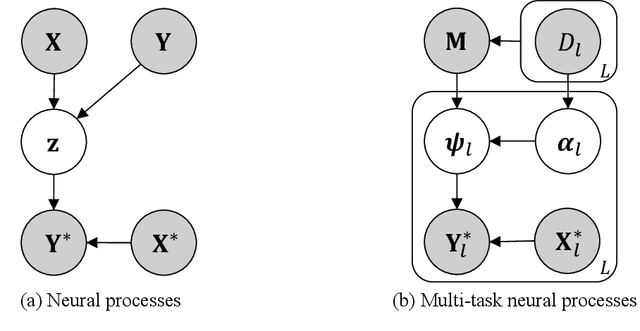
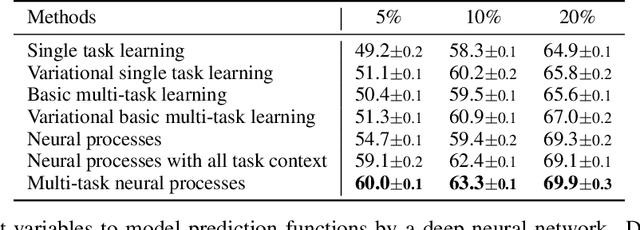
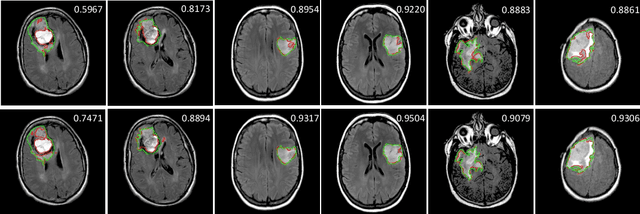
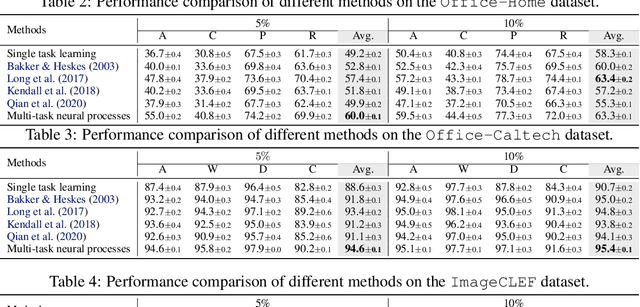
Neural processes have recently emerged as a class of powerful neural latent variable models that combine the strengths of neural networks and stochastic processes. As they can encode contextual data in the network's function space, they offer a new way to model task relatedness in multi-task learning. To study its potential, we develop multi-task neural processes, a new variant of neural processes for multi-task learning. In particular, we propose to explore transferable knowledge from related tasks in the function space to provide inductive bias for improving each individual task. To do so, we derive the function priors in a hierarchical Bayesian inference framework, which enables each task to incorporate the shared knowledge provided by related tasks into its context of the prediction function. Our multi-task neural processes methodologically expand the scope of vanilla neural processes and provide a new way of exploring task relatedness in function spaces for multi-task learning. The proposed multi-task neural processes are capable of learning multiple tasks with limited labeled data and in the presence of domain shift. We perform extensive experimental evaluations on several benchmarks for the multi-task regression and classification tasks. The results demonstrate the effectiveness of multi-task neural processes in transferring useful knowledge among tasks for multi-task learning and superior performance in multi-task classification and brain image segmentation.