 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Class Orderings for Incremental Learning
Jul 07, 2020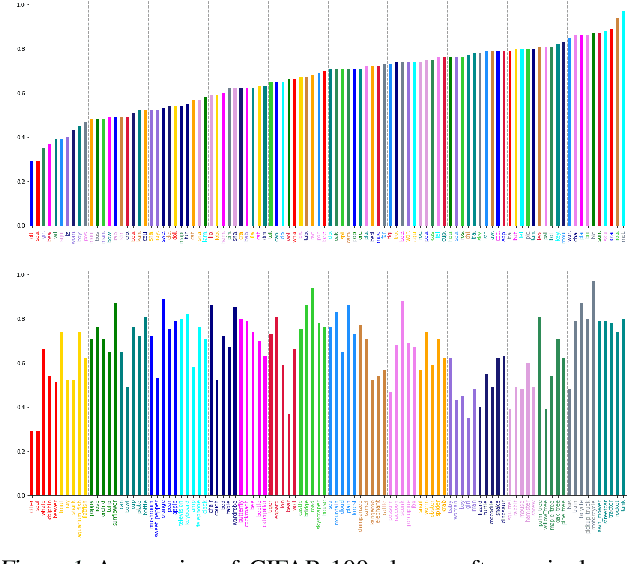
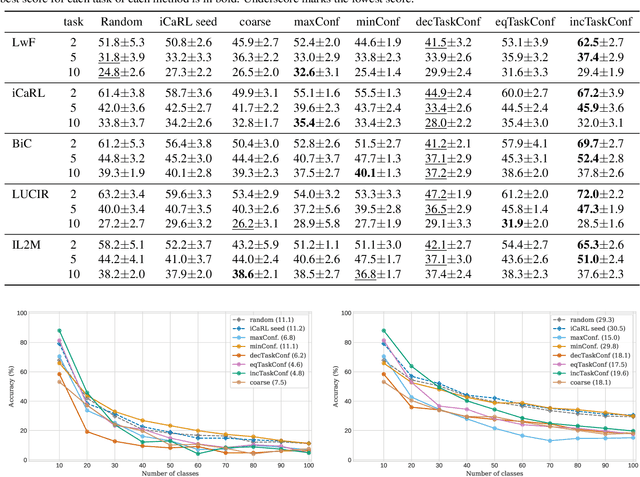
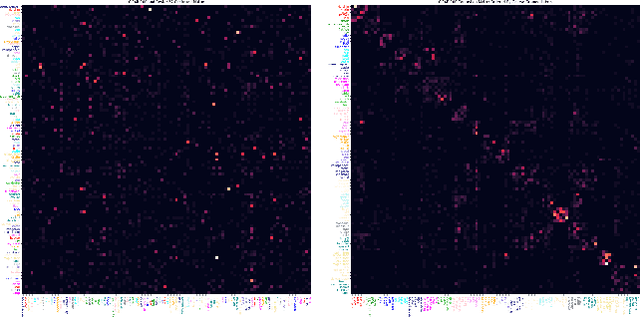
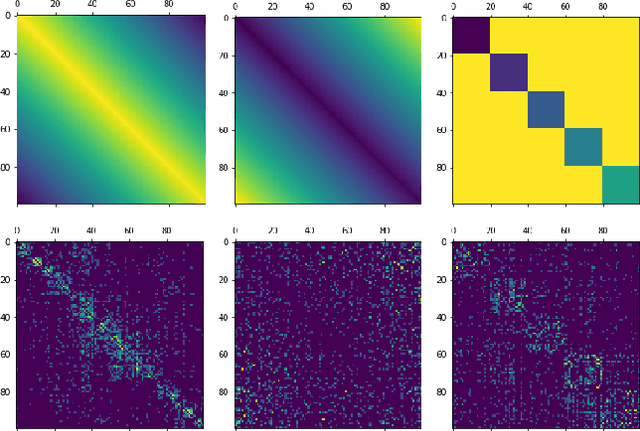
The influence of class orderings in the evaluation of incremental learning has received very little attention. In this paper, we investigate the impact of class orderings for incrementally learned classifiers. We propose a method to compute various orderings for a dataset. The orderings are derived by simulated annealing optimization from the confusion matrix and reflect different incremental learning scenarios, including maximally and minimally confusing tasks. We evaluate a wide range of state-of-the-art incremental learning methods on the proposed orderings. Results show that orderings can have a significant impact on performance and the ranking of the methods.
Ternary Feature Masks: continual learning without any forgetting
Jan 23, 2020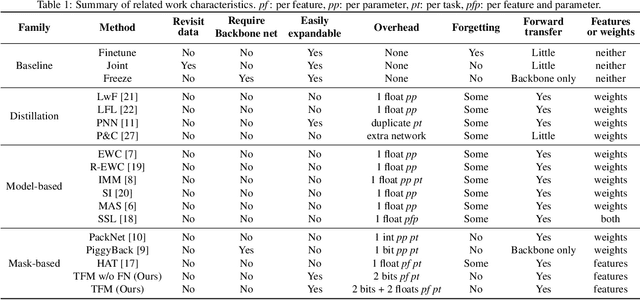
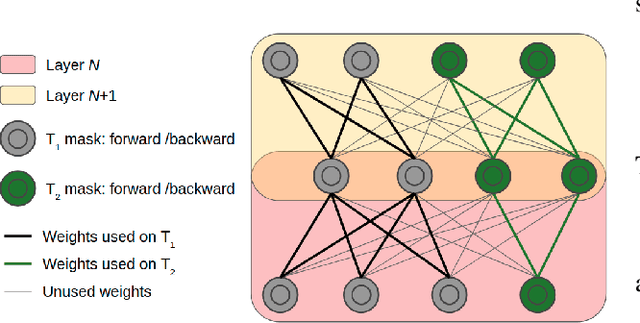
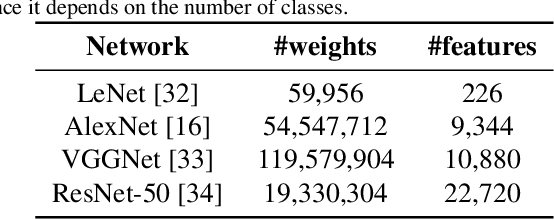
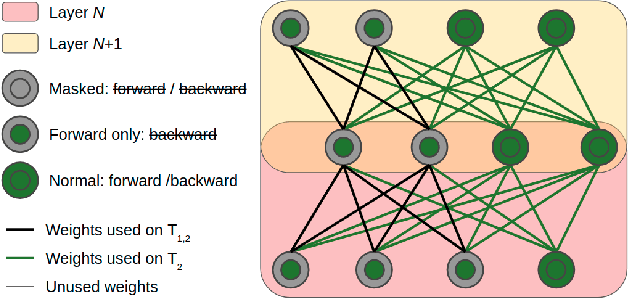
In this paper, we propose an approach without any forgetting to continual learning for the task-aware regime, where at inference the task-label is known. By using ternary masks we can upgrade a model to new tasks, reusing knowledge from previous tasks while not forgetting anything about them. Using masks prevents both catastrophic forgetting and backward transfer. We argue -- and show experimentally -- that avoiding the former largely compensates for the lack of the latter, which is rarely observed in practice. In contrast to earlier works, our masks are applied to the features (activations) of each layer instead of the weights. This considerably reduces the number of mask parameters to be added for each new task; with more than three orders of magnitude for most networks. The encoding of the ternary masks into two bits per feature creates very little overhead to the network, avoiding scalability issues. Our masks do not permit any changes to features which are used by previous tasks. As this may be too restrictive to allow learning of new tasks, we add task-specific feature normalization. This way, already learned features can adapt to the current task without changing the behavior of these features for previous tasks. Extensive experiments on several finegrained datasets and ImageNet show that our method outperforms current state-of-the-art while reducing memory overhead in comparison to weight-based approaches.
Continual learning: A comparative study on how to defy forgetting in classification tasks
Sep 18, 2019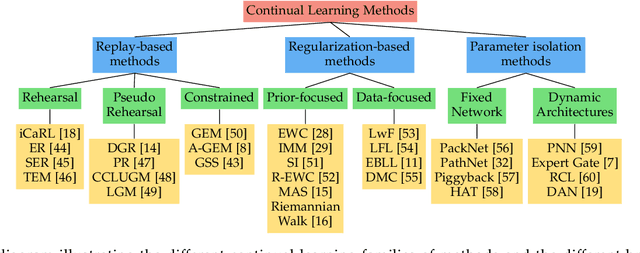


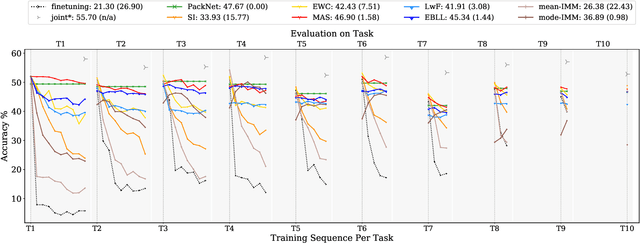
Artificial neural networks thrive in solving the classification problem for a particular rigid task, where the network resembles a static entity of knowledge, acquired through generalized learning behaviour from a distinct training phase. However, endeavours to extend this knowledge without targeting the original task usually result in a catastrophic forgetting of this task. Continual learning shifts this paradigm towards a network that can continually accumulate knowledge over different tasks without the need for retraining from scratch, with methods in particular aiming to alleviate forgetting. We focus on task-incremental classification, where tasks arrive in a batch-like fashion, and are delineated by clear boundaries. Our main contributions concern 1) a taxonomy and extensive overview of the state-of-the-art, 2) a novel framework to continually determine stability-plasticity trade-off of the continual learner, 3) a comprehensive experimental comparison of 10 state-of-the-art continual learning methods and 4 baselines. We empirically scrutinize which method performs best, both on balanced Tiny Imagenet and a large-scale unbalanced iNaturalist datasets. We study the influence of model capacity, weight decay and dropout regularization, and the order in which the tasks are presented, and qualitatively compare methods in terms of required memory, computation time and storage.
LIUM-CVC Submissions for WMT18 Multimodal Translation Task
Sep 01, 2018
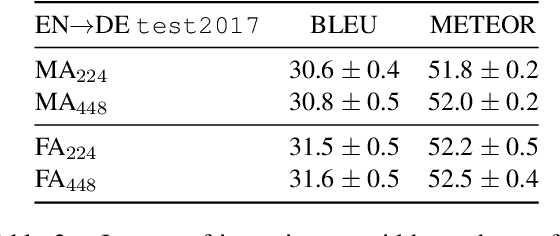
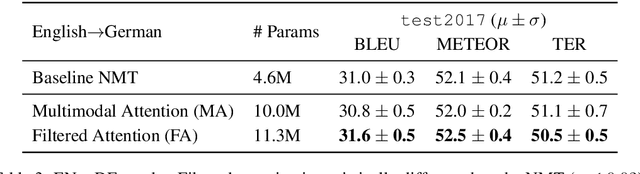
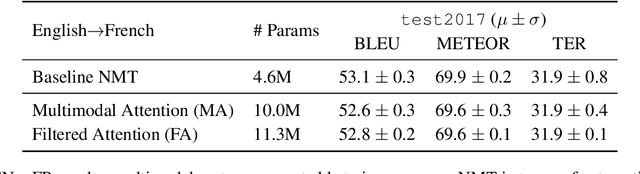
This paper describes the multimodal Neural Machine Translation systems developed by LIUM and CVC for WMT18 Shared Task on Multimodal Translation. This year we propose several modifications to our previous multimodal attention architecture in order to better integrate convolutional features and refine them using encoder-side information. Our final constrained submissions ranked first for English-French and second for English-German language pairs among the constrained submissions according to the automatic evaluation metric METEOR.
Metric Learning for Novelty and Anomaly Detection
Aug 16, 2018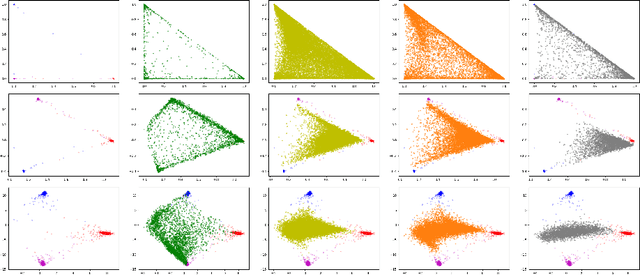
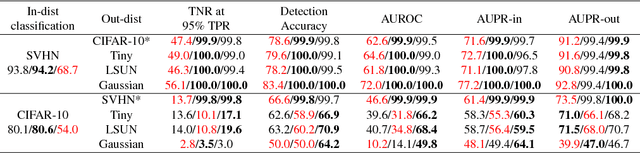

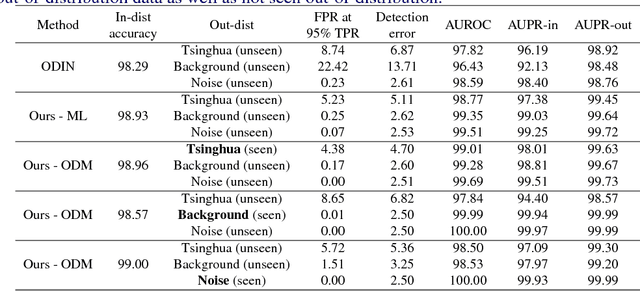
When neural networks process images which do not resemble the distribution seen during training, so called out-of-distribution images, they often make wrong predictions, and do so too confidently. The capability to detect out-of-distribution images is therefore crucial for many real-world applications. We divide out-of-distribution detection between novelty detection ---images of classes which are not in the training set but are related to those---, and anomaly detection ---images with classes which are unrelated to the training set. By related we mean they contain the same type of objects, like digits in MNIST and SVHN. Most existing work has focused on anomaly detection, and has addressed this problem considering networks trained with the cross-entropy loss. Differently from them, we propose to use metric learning which does not have the drawback of the softmax layer (inherent to cross-entropy methods), which forces the network to divide its prediction power over the learned classes. We perform extensive experiments and evaluate both novelty and anomaly detection, even in a relevant application such as traffic sign recognition, obtaining comparable or better results than previous works.
Rotate your Networks: Better Weight Consolidation and Less Catastrophic Forgetting
Jul 12, 2018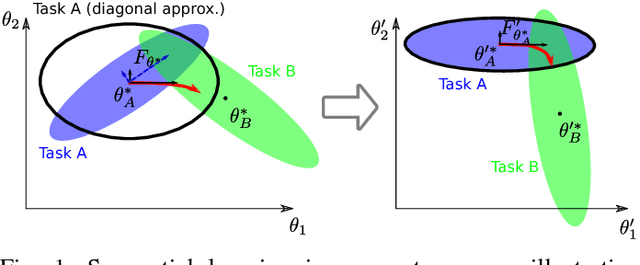
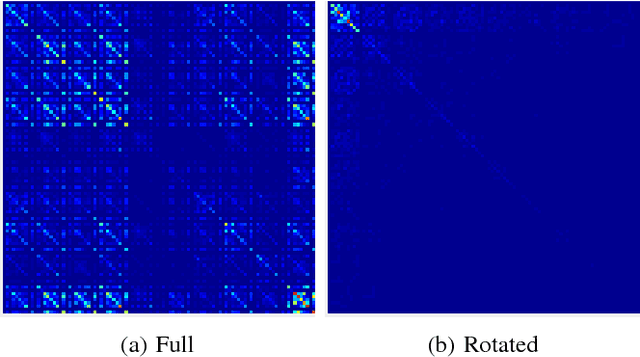
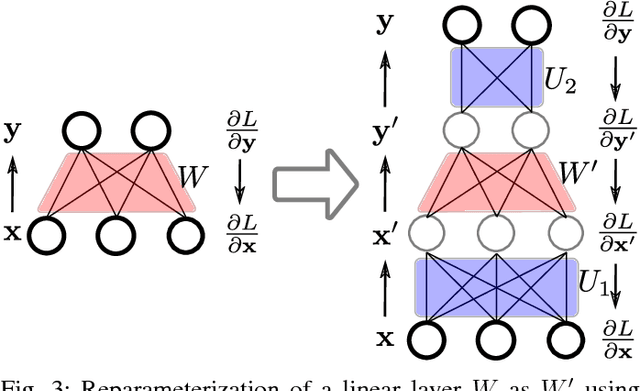
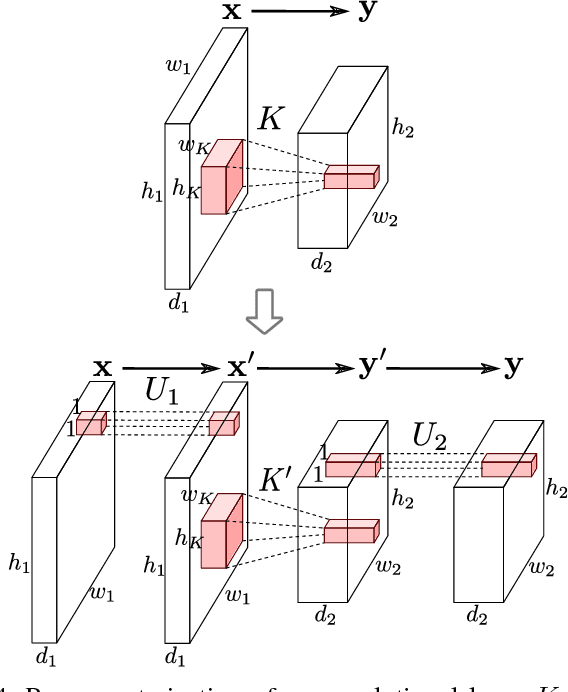
In this paper we propose an approach to avoiding catastrophic forgetting in sequential task learning scenarios. Our technique is based on a network reparameterization that approximately diagonalizes the Fisher Information Matrix of the network parameters. This reparameterization takes the form of a factorized rotation of parameter space which, when used in conjunction with Elastic Weight Consolidation (which assumes a diagonal Fisher Information Matrix), leads to significantly better performance on lifelong learning of sequential tasks. Experimental results on the MNIST, CIFAR-100, CUB-200 and Stanford-40 datasets demonstrate that we significantly improve the results of standard elastic weight consolidation, and that we obtain competitive results when compared to other state-of-the-art in lifelong learning without forgetting.
Context Proposals for Saliency Detection
Jun 27, 2018
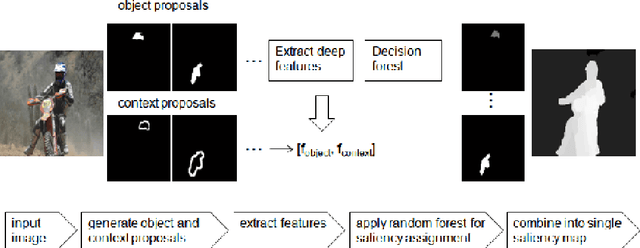
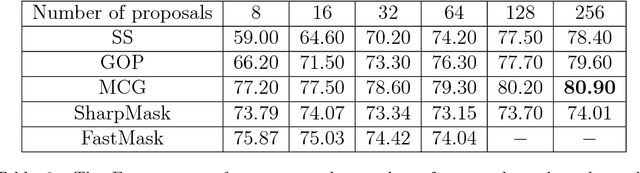
One of the fundamental properties of a salient object region is its contrast with the immediate context. The problem is that numerous object regions exist which potentially can all be salient. One way to prevent an exhaustive search over all object regions is by using object proposal algorithms. These return a limited set of regions which are most likely to contain an object. Several saliency estimation methods have used object proposals. However, they focus on the saliency of the proposal only, and the importance of its immediate context has not been evaluated. In this paper, we aim to improve salient object detection. Therefore, we extend object proposal methods with context proposals, which allow to incorporate the immediate context in the saliency computation. We propose several saliency features which are computed from the context proposals. In the experiments, we evaluate five object proposal methods for the task of saliency segmentation, and find that Multiscale Combinatorial Grouping outperforms the others. Furthermore, experiments show that the proposed context features improve performance, and that our method matches results on the FT datasets and obtains competitive results on three other datasets (PASCAL-S, MSRA-B and ECSSD).
Domain-adaptive deep network compression
Sep 06, 2017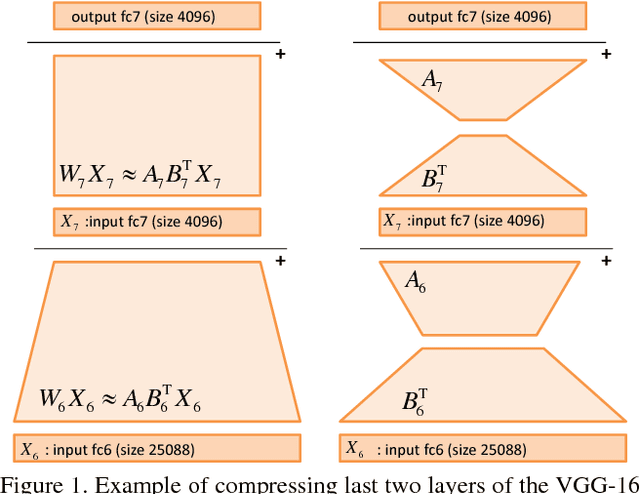
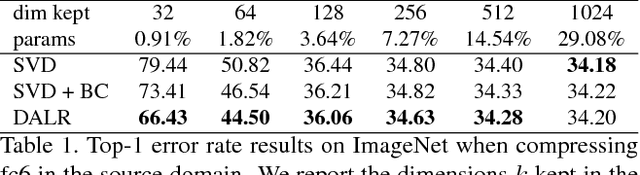
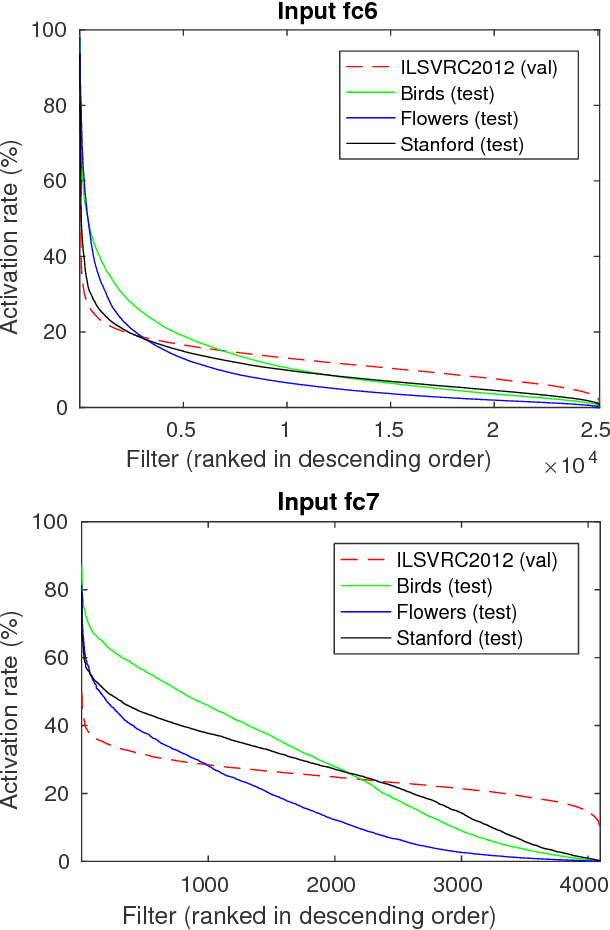
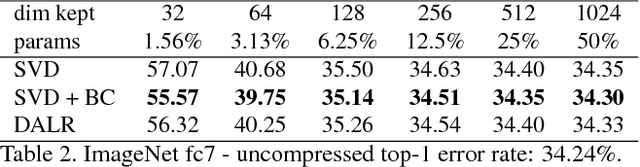
Deep Neural Networks trained on large datasets can be easily transferred to new domains with far fewer labeled examples by a process called fine-tuning. This has the advantage that representations learned in the large source domain can be exploited on smaller target domains. However, networks designed to be optimal for the source task are often prohibitively large for the target task. In this work we address the compression of networks after domain transfer. We focus on compression algorithms based on low-rank matrix decomposition. Existing methods base compression solely on learned network weights and ignore the statistics of network activations. We show that domain transfer leads to large shifts in network activations and that it is desirable to take this into account when compressing. We demonstrate that considering activation statistics when compressing weights leads to a rank-constrained regression problem with a closed-form solution. Because our method takes into account the target domain, it can more optimally remove the redundancy in the weights. Experiments show that our Domain Adaptive Low Rank (DALR) method significantly outperforms existing low-rank compression techniques. With our approach, the fc6 layer of VGG19 can be compressed more than 4x more than using truncated SVD alone -- with only a minor or no loss in accuracy. When applied to domain-transferred networks it allows for compression down to only 5-20% of the original number of parameters with only a minor drop in performance.
LIUM-CVC Submissions for WMT17 Multimodal Translation Task
Jul 14, 2017This paper describes the monomodal and multimodal Neural Machine Translation systems developed by LIUM and CVC for WMT17 Shared Task on Multimodal Translation. We mainly explored two multimodal architectures where either global visual features or convolutional feature maps are integrated in order to benefit from visual context. Our final systems ranked first for both En-De and En-Fr language pairs according to the automatic evaluation metrics METEOR and BLEU.
Does Multimodality Help Human and Machine for Translation and Image Captioning?
Aug 16, 2016

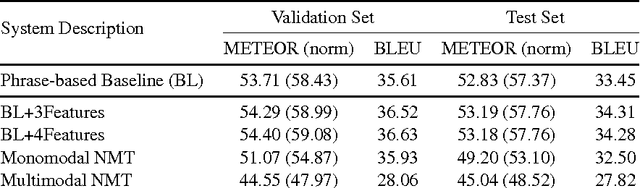
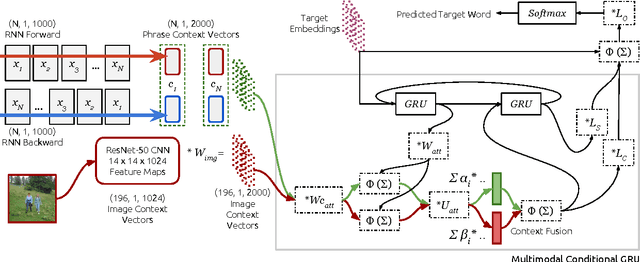
This paper presents the systems developed by LIUM and CVC for the WMT16 Multimodal Machine Translation challenge. We explored various comparative methods, namely phrase-based systems and attentional recurrent neural networks models trained using monomodal or multimodal data. We also performed a human evaluation in order to estimate the usefulness of multimodal data for human machine translation and image description generation. Our systems obtained the best results for both tasks according to the automatic evaluation metrics BLEU and METEOR.