 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-too: A language-model-first approach for AMR-to-text generation
May 27, 2020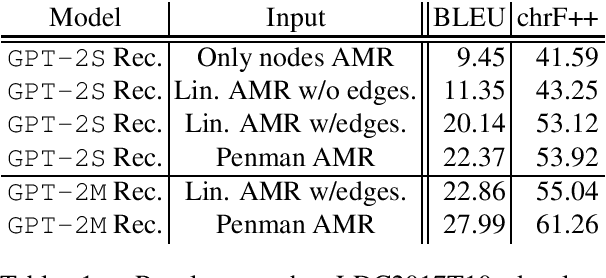

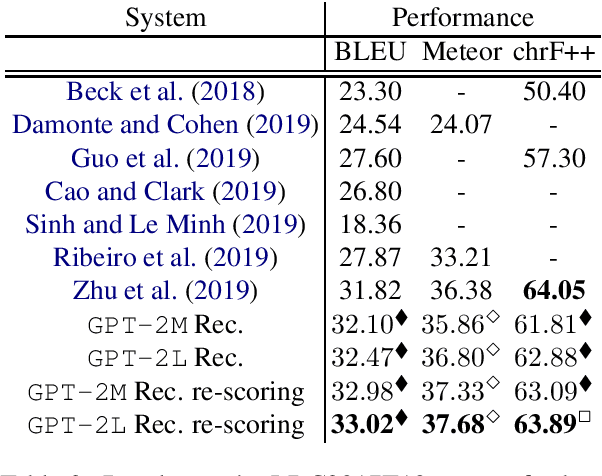
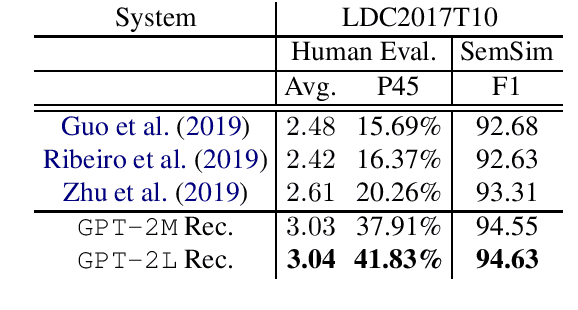
Meaning Representations (AMRs) are broad-coverage sentence-level semantic graphs. Existing approaches to generating text from AMR have focused on training sequence-to-sequence or graph-to-sequence models on AMR annotated data only. In this paper, we propose an alternative approach that combines a strong pre-trained language model with cycle consistency-based re-scoring. Despite the simplicity of the approach, our experimental results show these models outperform all previous techniques on the English LDC2017T10dataset, including the recent use of transformer architectures. In addition to the standard evaluation metrics, we provide human evaluation experiments that further substantiate the strength of our approach.
The IMS-CUBoulder System for the SIGMORPHON 2020 Shared Task on Unsupervised Morphological Paradigm Completion
May 25, 2020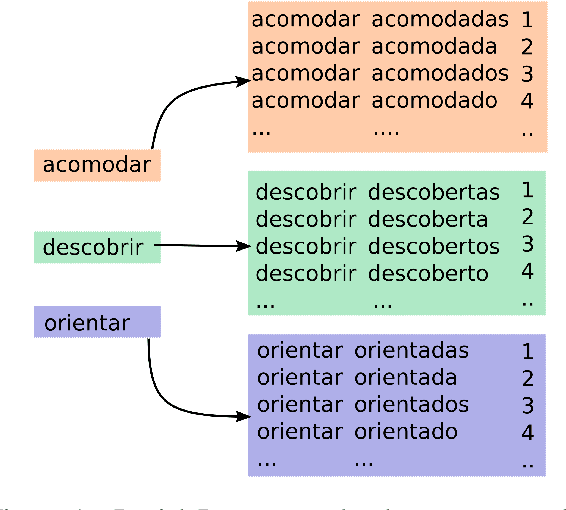
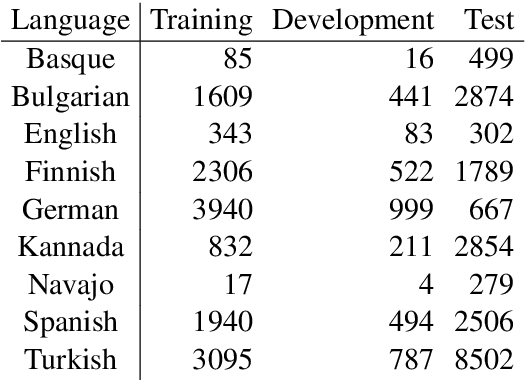
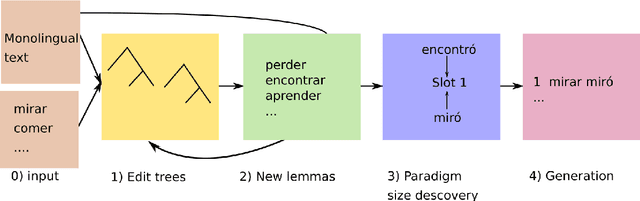
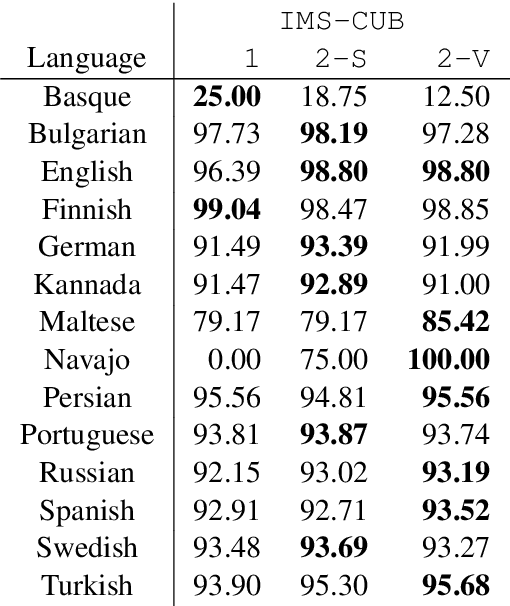
In this paper, we present the systems of the University of Stuttgart IMS and the University of Colorado Boulder (IMS-CUBoulder) for SIGMORPHON 2020 Task 2 on unsupervised morphological paradigm completion (Kann et al., 2020). The task consists of generating the morphological paradigms of a set of lemmas, given only the lemmas themselves and unlabeled text. Our proposed system is a modified version of the baseline introduced together with the task. In particular, we experiment with substituting the inflection generation component with an LSTM sequence-to-sequence model and an LSTM pointer-generator network. Our pointer-generator system obtains the best score of all seven submitted systems on average over all languages, and outperforms the official baseline, which was best overall, on Bulgarian and Kannada.
Subword-Level Language Identification for Intra-Word Code-Switching
Apr 03, 2019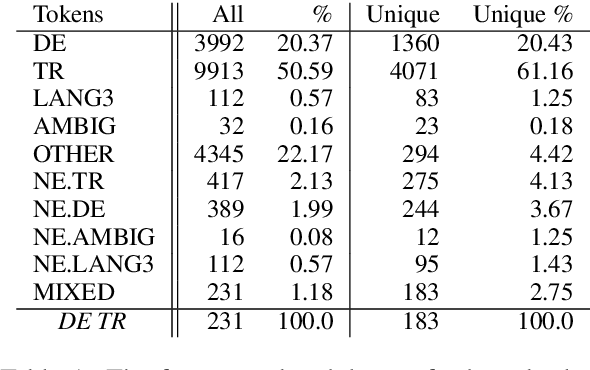

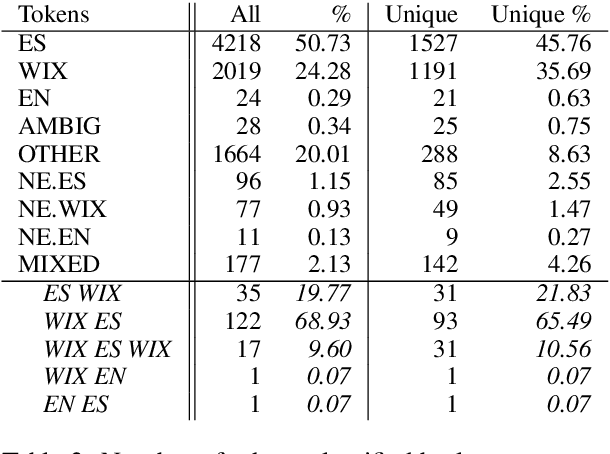
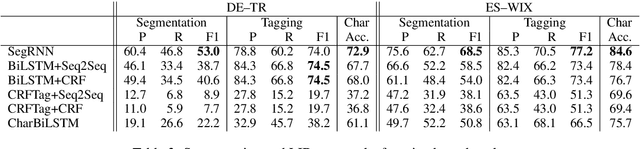
Language identification for code-switching (CS), the phenomenon of alternating between two or more languages in conversations, has traditionally been approached under the assumption of a single language per token. However, if at least one language is morphologically rich, a large number of words can be composed of morphemes from more than one language (intra-word CS). In this paper, we extend the language identification task to the subword-level, such that it includes splitting mixed words while tagging each part with a language ID. We further propose a model for this task, which is based on a segmental recurrent neural network. In experiments on a new Spanish--Wixarika dataset and on an adapted German--Turkish dataset, our proposed model performs slightly better than or roughly on par with our best baseline, respectively. Considering only mixed words, however, it strongly outperforms all baselines.
Lost in Translation: Analysis of Information Loss During Machine Translation Between Polysynthetic and Fusional Languages
Jul 01, 2018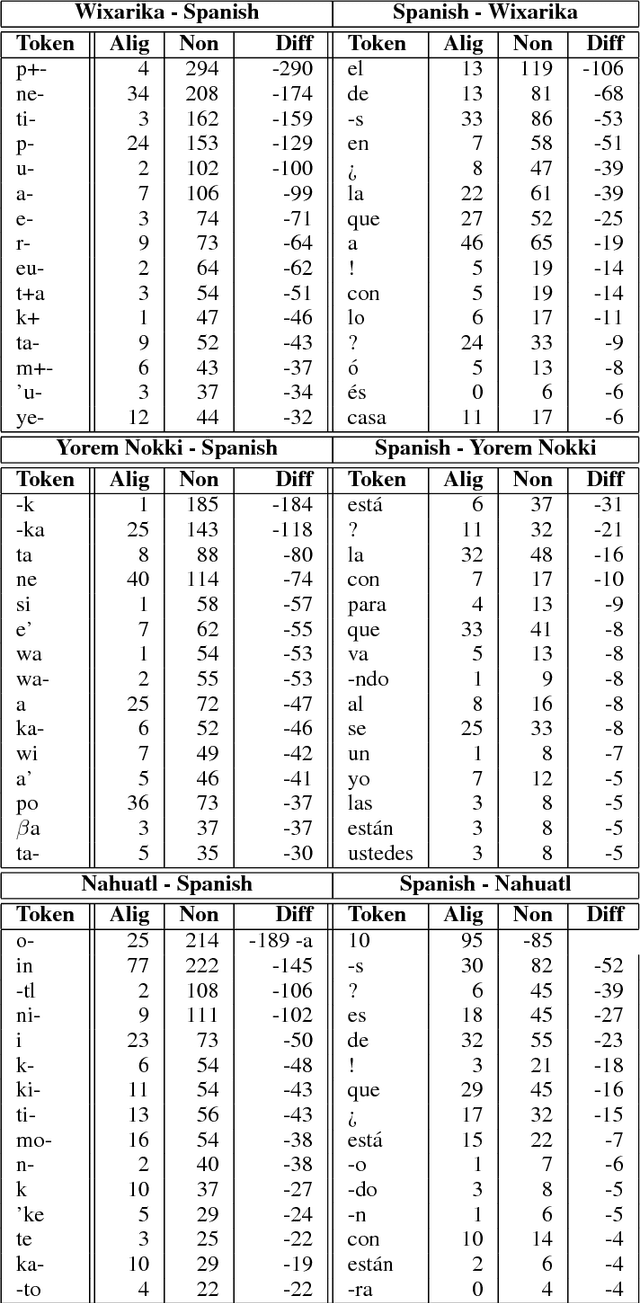

Machine translation from polysynthetic to fusional languages is a challenging task, which gets further complicated by the limited amount of parallel text available. Thus, translation performance is far from the state of the art for high-resource and more intensively studied language pairs. To shed light on the phenomena which hamper automatic translation to and from polysynthetic languages, we study translations from three low-resource, polysynthetic languages (Nahuatl, Wixarika and Yorem Nokki) into Spanish and vice versa. Doing so, we find that in a morpheme-to-morpheme alignment an important amount of information contained in polysynthetic morphemes has no Spanish counterpart, and its translation is often omitted. We further conduct a qualitative analysis and, thus, identify morpheme types that are commonly hard to align or ignored in the translation process.
Challenges of language technologies for the indigenous languages of the Americas
Jun 12, 2018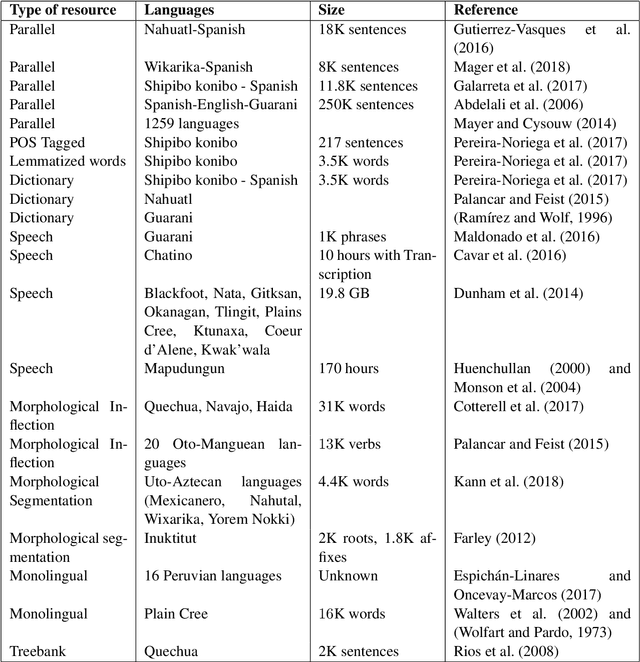
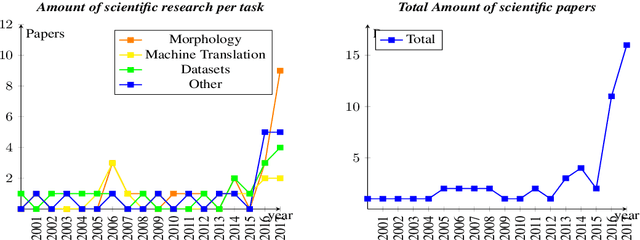
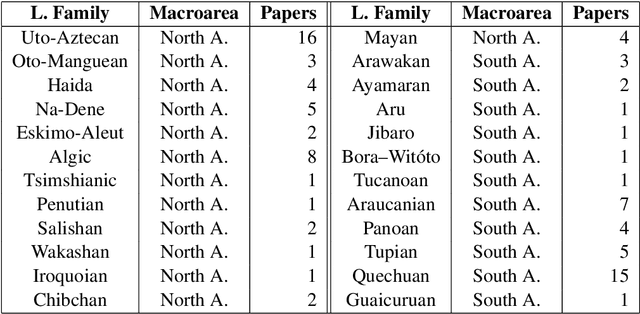
Indigenous languages of the American continent are highly diverse. However, they have received little attention from the technological perspective. In this paper, we review the research, the digital resources and the available NLP systems that focus on these languages. We present the main challenges and research questions that arise when distant languages and low-resource scenarios are faced. We would like to encourage NLP research in linguistically rich and diverse areas like the Americas.
Fortification of Neural Morphological Segmentation Models for Polysynthetic Minimal-Resource Languages
Apr 17, 2018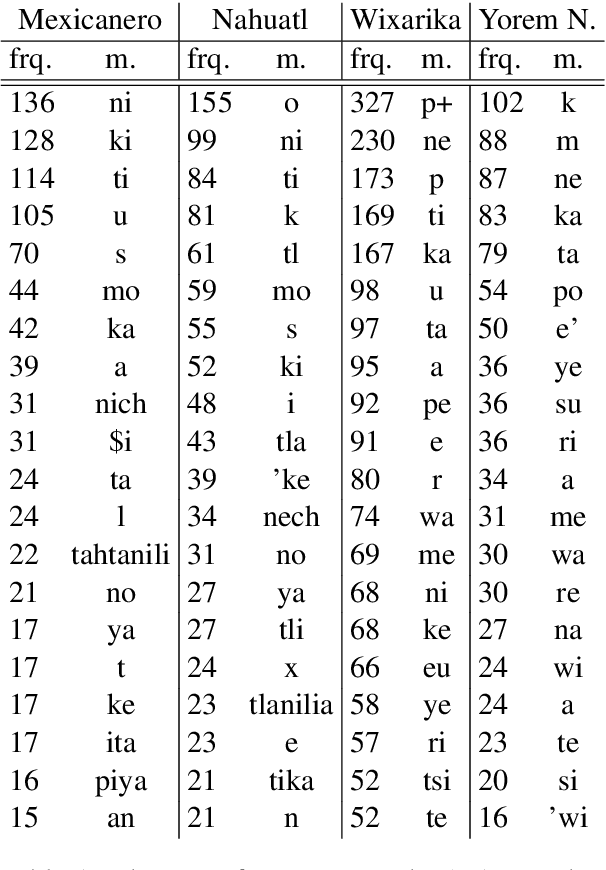
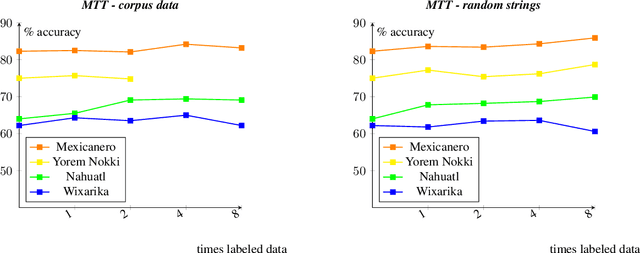
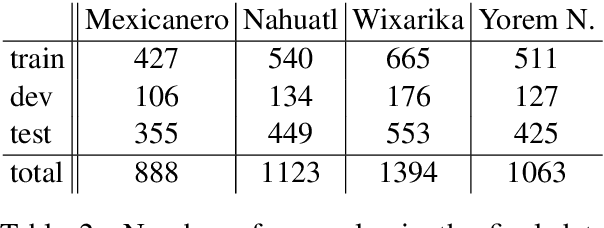
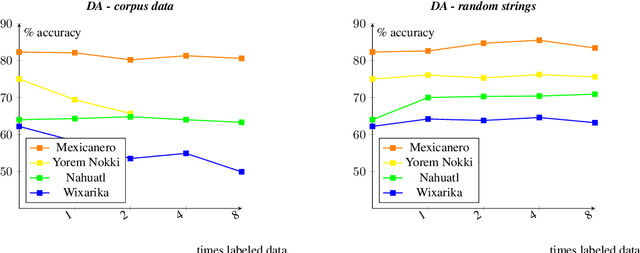
Morphological segmentation for polysynthetic languages is challenging, because a word may consist of many individual morphemes and training data can be extremely scarce. Since neural sequence-to-sequence (seq2seq) models define the state of the art for morphological segmentation in high-resource settings and for (mostly) European languages, we first show that they also obtain competitive performance for Mexican polysynthetic languages in minimal-resource settings. We then propose two novel multi-task training approaches -one with, one without need for external unlabeled resources-, and two corresponding data augmentation methods, improving over the neural baseline for all languages. Finally, we explore cross-lingual transfer as a third way to fortify our neural model and show that we can train one single multi-lingual model for related languages while maintaining comparable or even improved performance, thus reducing the amount of parameters by close to 75%. We provide our morphological segmentation datasets for Mexicanero, Nahuatl, Wixarika and Yorem Nokki for future research.