 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe SIGMORPHON 2019 Shared Task: Morphological Analysis in Context and Cross-Lingual Transfer for Inflection
Oct 25, 2019
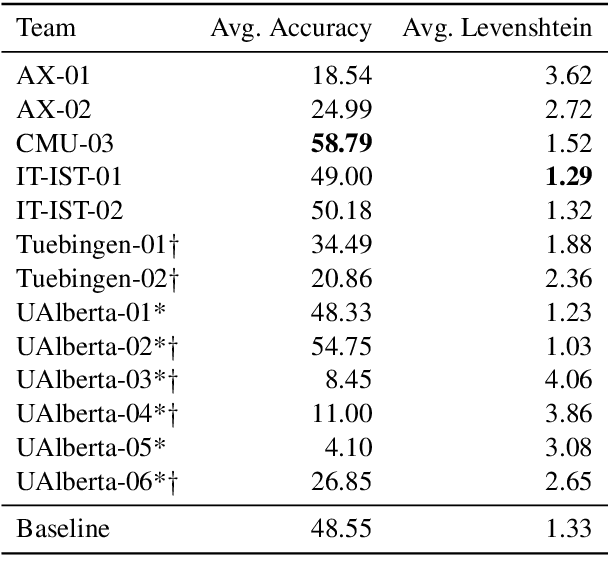
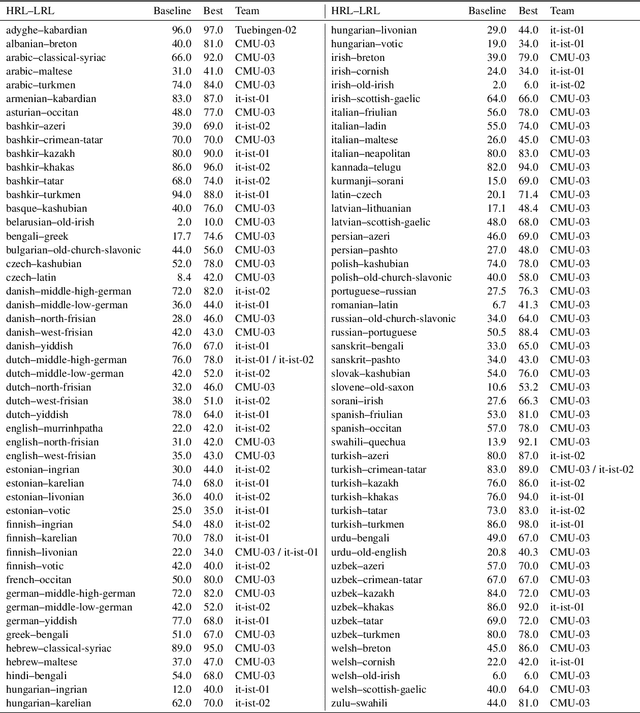
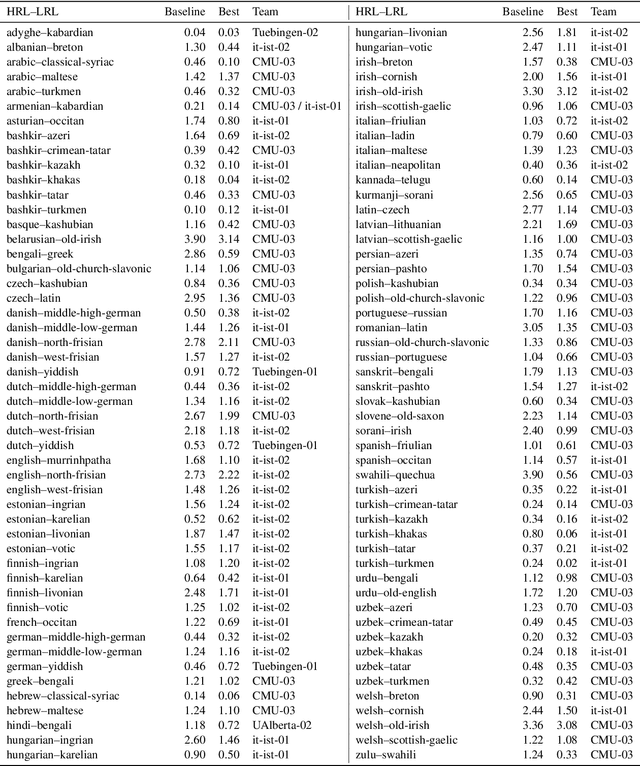
The SIGMORPHON 2019 shared task on cross-lingual transfer and contextual analysis in morphology examined transfer learning of inflection between 100 language pairs, as well as contextual lemmatization and morphosyntactic description in 66 languages. The first task evolves past years' inflection tasks by examining transfer of morphological inflection knowledge from a high-resource language to a low-resource language. This year also presents a new second challenge on lemmatization and morphological feature analysis in context. All submissions featured a neural component and built on either this year's strong baselines or highly ranked systems from previous years' shared tasks. Every participating team improved in accuracy over the baselines for the inflection task (though not Levenshtein distance), and every team in the contextual analysis task improved on both state-of-the-art neural and non-neural baselines.
* Presented at SIGMORPHON 2019
UniMorph 2.0: Universal Morphology
Oct 25, 2018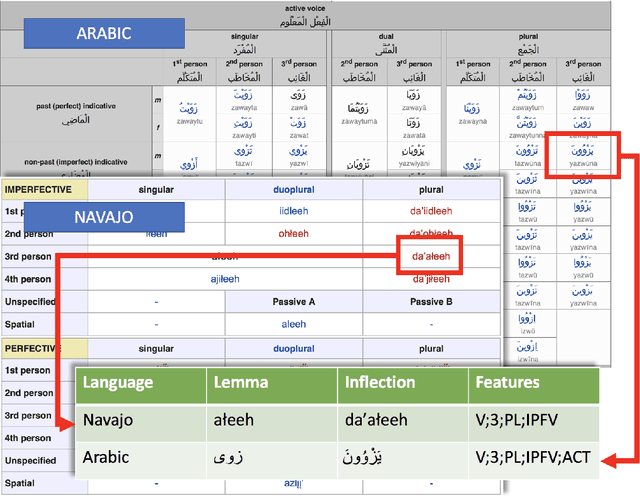
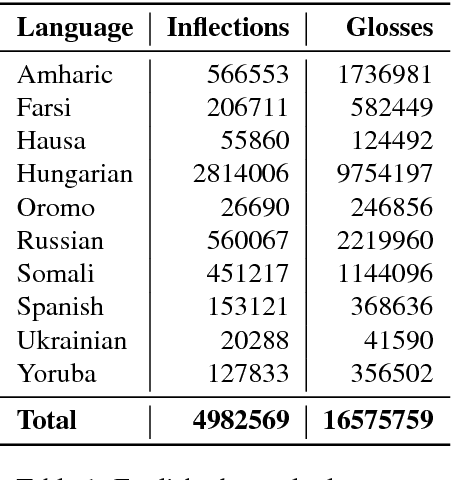

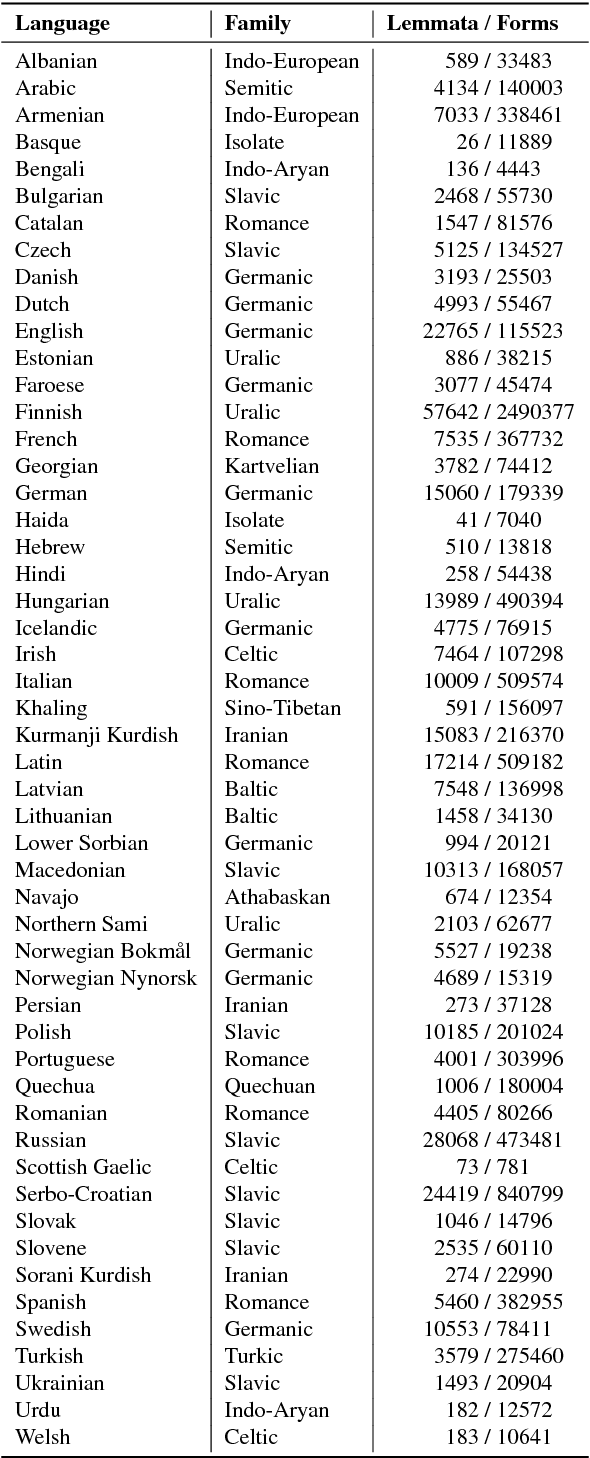
The Universal Morphology UniMorph project is a collaborative effort to improve how NLP handles complex morphology across the world's languages. The project releases annotated morphological data using a universal tagset, the UniMorph schema. Each inflected form is associated with a lemma, which typically carries its underlying lexical meaning, and a bundle of morphological features from our schema. Additional supporting data and tools are also released on a per-language basis when available. UniMorph is based at the Center for Language and Speech Processing (CLSP) at Johns Hopkins University in Baltimore, Maryland and is sponsored by the DARPA LORELEI program. This paper details advances made to the collection, annotation, and dissemination of project resources since the initial UniMorph release described at LREC 2016. lexical resources} }
The CoNLL--SIGMORPHON 2018 Shared Task: Universal Morphological Reinflection
Oct 18, 2018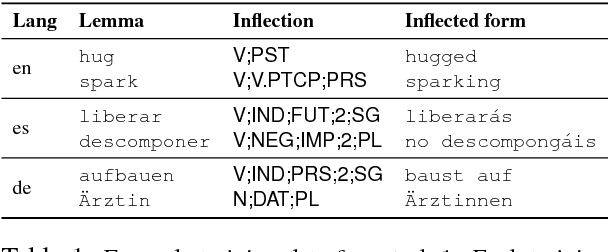
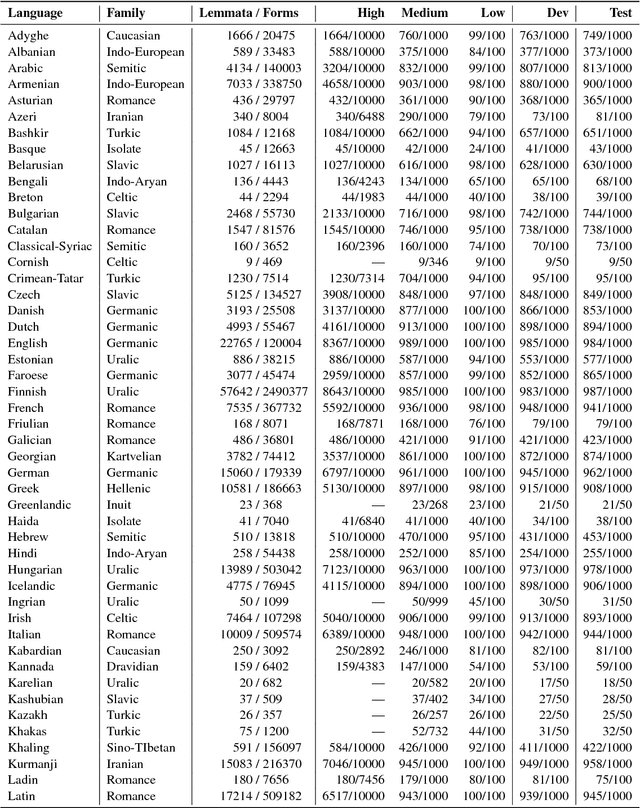
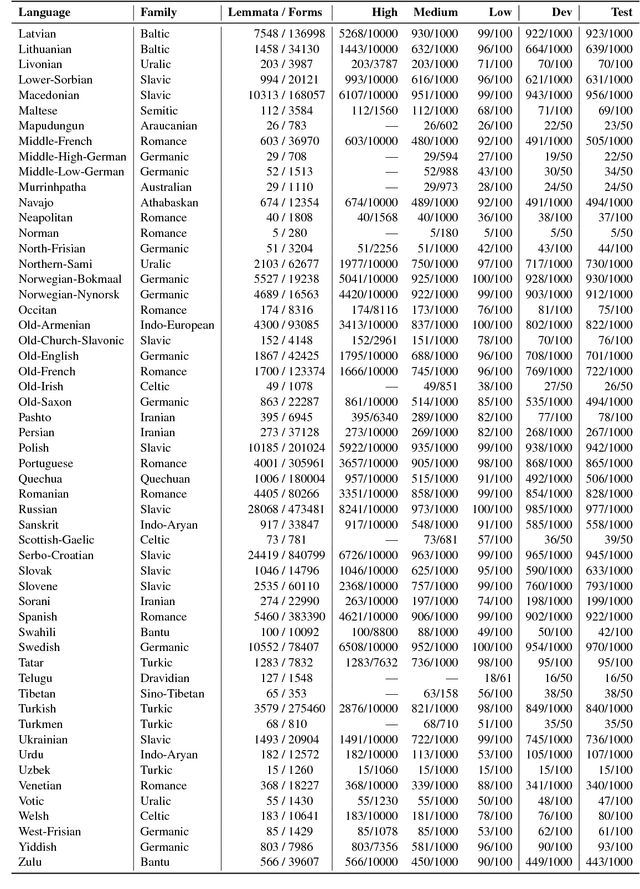

The CoNLL--SIGMORPHON 2018 shared task on supervised learning of morphological generation featured data sets from 103 typologically diverse languages. Apart from extending the number of languages involved in earlier supervised tasks of generating inflected forms, this year the shared task also featured a new second task which asked participants to inflect words in sentential context, similar to a cloze task. This second task featured seven languages. Task 1 received 27 submissions and task 2 received 6 submissions. Both tasks featured a low, medium, and high data condition. Nearly all submissions featured a neural component and built on highly-ranked systems from the earlier 2017 shared task. In the inflection task (task 1), 41 of the 52 languages present in last year's inflection task showed improvement by the best systems in the low-resource setting. The cloze task (task 2) proved to be difficult, and few submissions managed to consistently improve upon both a simple neural baseline system and a lemma-repeating baseline.
Marrying Universal Dependencies and Universal Morphology
Oct 15, 2018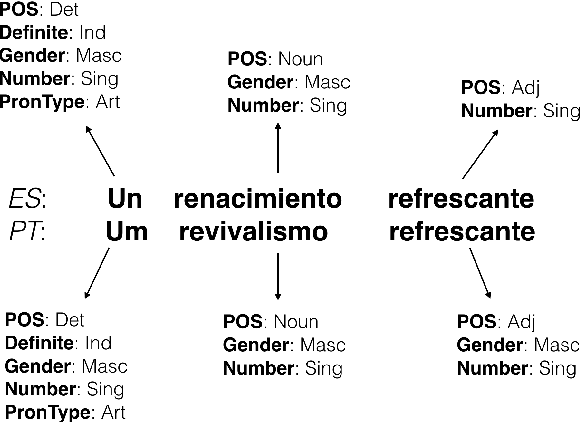
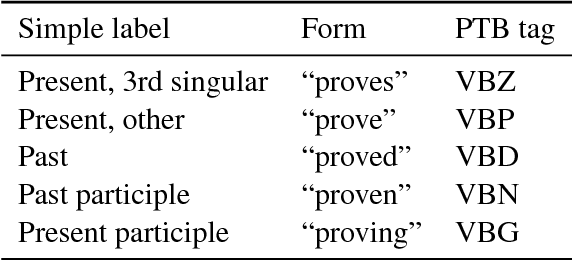


The Universal Dependencies (UD) and Universal Morphology (UniMorph) projects each present schemata for annotating the morphosyntactic details of language. Each project also provides corpora of annotated text in many languages - UD at the token level and UniMorph at the type level. As each corpus is built by different annotators, language-specific decisions hinder the goal of universal schemata. With compatibility of tags, each project's annotations could be used to validate the other's. Additionally, the availability of both type- and token-level resources would be a boon to tasks such as parsing and homograph disambiguation. To ease this interoperability, we present a deterministic mapping from Universal Dependencies v2 features into the UniMorph schema. We validate our approach by lookup in the UniMorph corpora and find a macro-average of 64.13% recall. We also note incompatibilities due to paucity of data on either side. Finally, we present a critical evaluation of the foundations, strengths, and weaknesses of the two annotation projects.
On the Complexity and Typology of Inflectional Morphological Systems
Jul 08, 2018We quantify the linguistic complexity of different languages' morphological systems. We verify that there is an empirical trade-off between paradigm size and irregularity: a language's inflectional paradigms may be either large in size or highly irregular, but never both. Our methodology measures paradigm irregularity as the entropy of the surface realization of a paradigm -- how hard it is to jointly predict all the surface forms of a paradigm. We estimate this by a variational approximation. Our measurements are taken on large morphological paradigms from 31 typologically diverse languages.
On the Diachronic Stability of Irregularity in Inflectional Morphology
Apr 23, 2018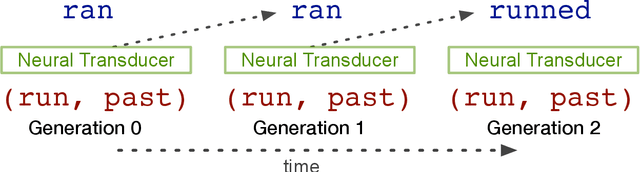
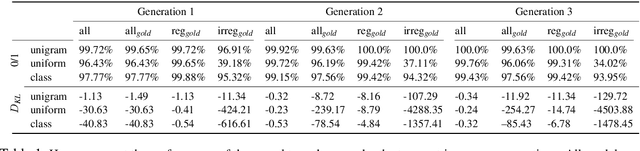
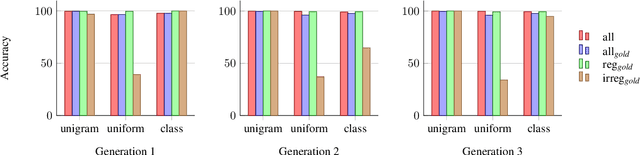
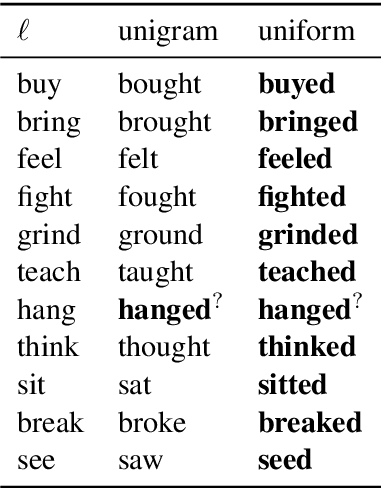
Many languages' inflectional morphological systems are replete with irregulars, i.e., words that do not seem to follow standard inflectional rules. In this work, we quantitatively investigate the conditions under which irregulars can survive in a language over the course of time. Using recurrent neural networks to simulate language learners, we test the diachronic relation between frequency of words and their irregularity.
A Comparison of Feature-Based and Neural Scansion of Poetry
Nov 02, 2017Automatic analysis of poetic rhythm is a challenging task that involves linguistics, literature, and computer science. When the language to be analyzed is known, rule-based systems or data-driven methods can be used. In this paper, we analyze poetic rhythm in English and Spanish. We show that the representations of data learned from character-based neural models are more informative than the ones from hand-crafted features, and that a Bi-LSTM+CRF-model produces state-of-the art accuracy on scansion of poetry in two languages. Results also show that the information about whole word structure, and not just independent syllables, is highly informative for performing scansion.
CoNLL-SIGMORPHON 2017 Shared Task: Universal Morphological Reinflection in 52 Languages
Jul 04, 2017
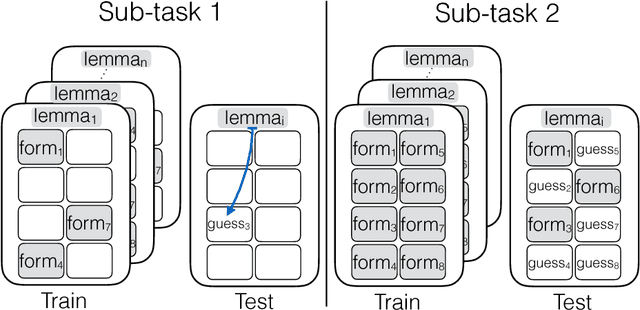
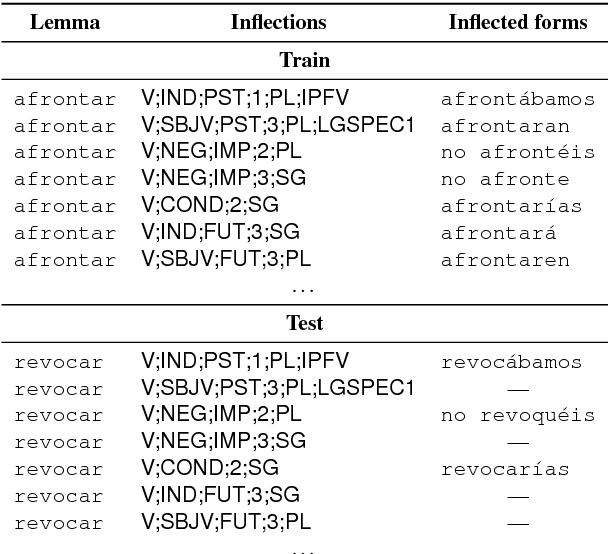
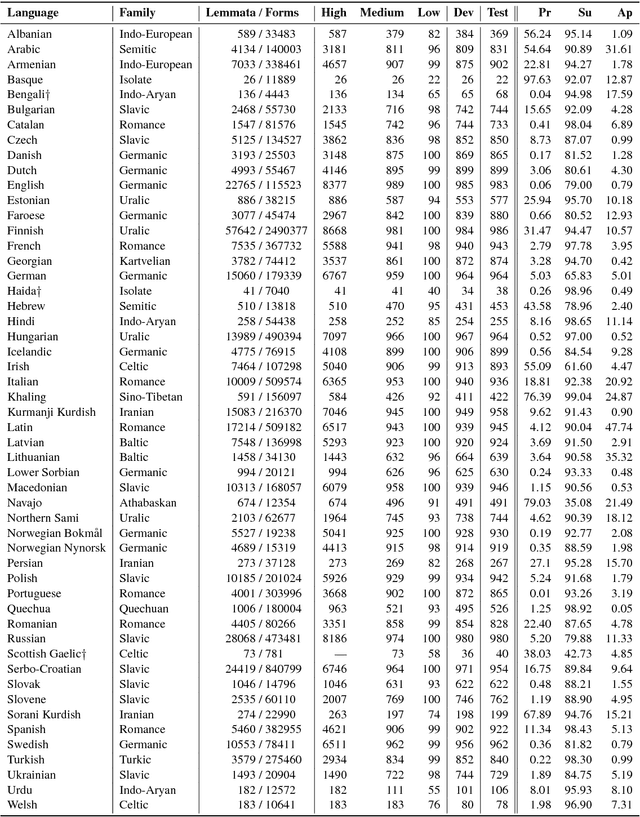
The CoNLL-SIGMORPHON 2017 shared task on supervised morphological generation required systems to be trained and tested in each of 52 typologically diverse languages. In sub-task 1, submitted systems were asked to predict a specific inflected form of a given lemma. In sub-task 2, systems were given a lemma and some of its specific inflected forms, and asked to complete the inflectional paradigm by predicting all of the remaining inflected forms. Both sub-tasks included high, medium, and low-resource conditions. Sub-task 1 received 24 system submissions, while sub-task 2 received 3 system submissions. Following the success of neural sequence-to-sequence models in the SIGMORPHON 2016 shared task, all but one of the submissions included a neural component. The results show that high performance can be achieved with small training datasets, so long as models have appropriate inductive bias or make use of additional unlabeled data or synthetic data. However, different biasing and data augmentation resulted in disjoint sets of inflected forms being predicted correctly, suggesting that there is room for future improvement.