 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Universality in Multilingual Text Rewriting
Jul 30, 2021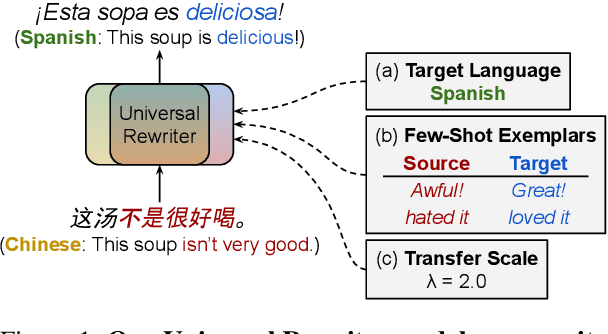
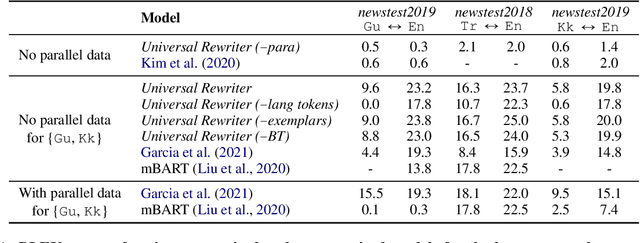
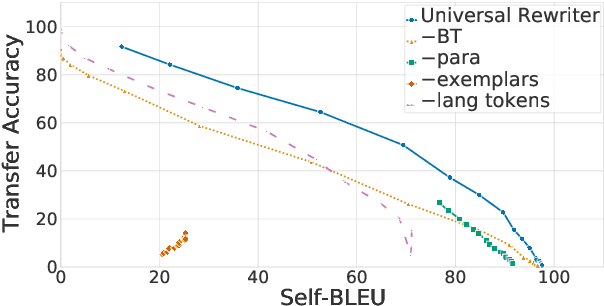

In this work, we take the first steps towards building a universal rewriter: a model capable of rewriting text in any language to exhibit a wide variety of attributes, including styles and languages, while preserving as much of the original semantics as possible. In addition to obtaining state-of-the-art results on unsupervised translation, we also demonstrate the ability to do zero-shot sentiment transfer in non-English languages using only English exemplars for sentiment. We then show that our model is able to modify multiple attributes at once, for example adjusting both language and sentiment jointly. Finally, we show that our model is capable of performing zero-shot formality-sensitive translation.
TextSETTR: Label-Free Text Style Extraction and Tunable Targeted Restyling
Oct 08, 2020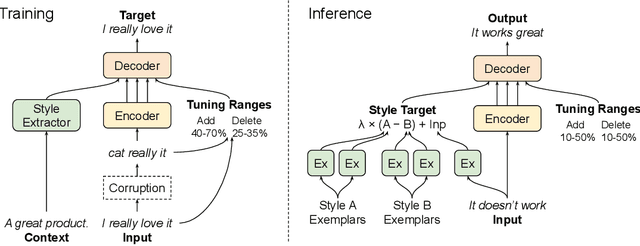
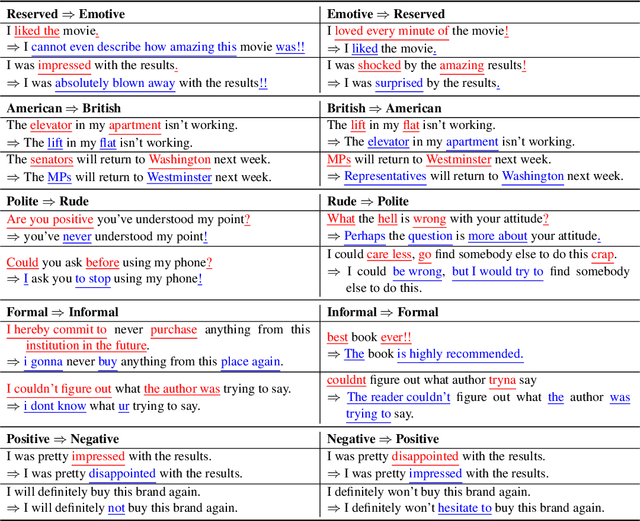
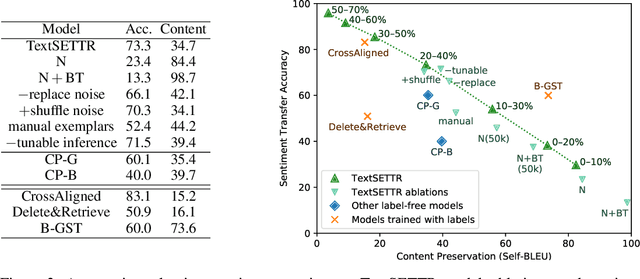

We present a novel approach to the problem of text style transfer. Unlike previous approaches that use parallel or non-parallel labeled data, our technique removes the need for labels entirely, relying instead on the implicit connection in style between adjacent sentences in unlabeled text. We show that T5 (Raffel et al., 2019), a strong pretrained text-to-text model, can be adapted to extract a style vector from arbitrary text and use this vector to condition the decoder to perform style transfer. As the resulting learned style vector space encodes many facets of textual style, we recast transfers as "targeted restyling" vector operations that adjust specific attributes of the input text while preserving others. When trained over unlabeled Amazon reviews data, our resulting TextSETTR model is competitive on sentiment transfer, even when given only four exemplars of each class. Furthermore, we demonstrate that a single model trained on unlabeled Common Crawl data is capable of transferring along multiple dimensions including dialect, emotiveness, formality, politeness, and sentiment.
Neural Retrieval for Question Answering with Cross-Attention Supervised Data Augmentation
Sep 29, 2020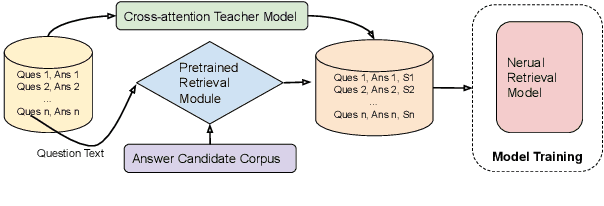
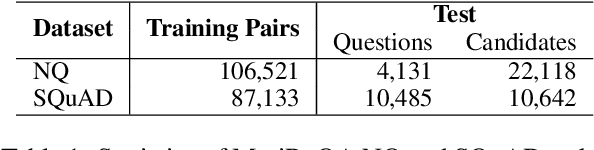
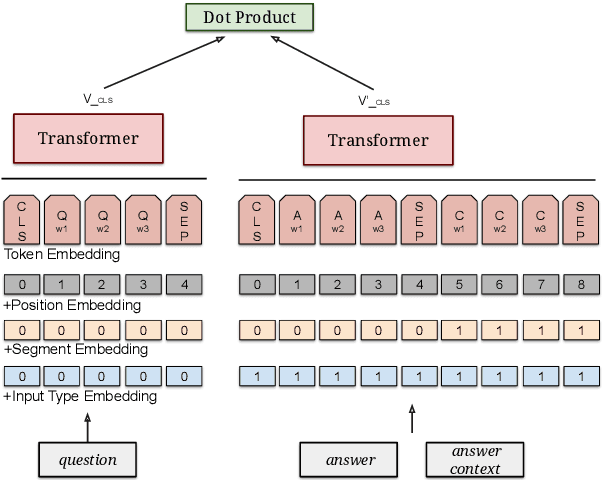
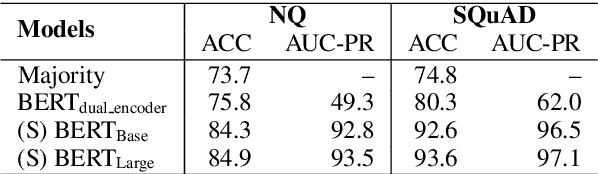
Neural models that independently project questions and answers into a shared embedding space allow for efficient continuous space retrieval from large corpora. Independently computing embeddings for questions and answers results in late fusion of information related to matching questions to their answers. While critical for efficient retrieval, late fusion underperforms models that make use of early fusion (e.g., a BERT based classifier with cross-attention between question-answer pairs). We present a supervised data mining method using an accurate early fusion model to improve the training of an efficient late fusion retrieval model. We first train an accurate classification model with cross-attention between questions and answers. The accurate cross-attention model is then used to annotate additional passages in order to generate weighted training examples for a neural retrieval model. The resulting retrieval model with additional data significantly outperforms retrieval models directly trained with gold annotations on Precision at $N$ (P@N) and Mean Reciprocal Rank (MRR).
MultiReQA: A Cross-Domain Evaluation for Retrieval Question Answering Models
May 05, 2020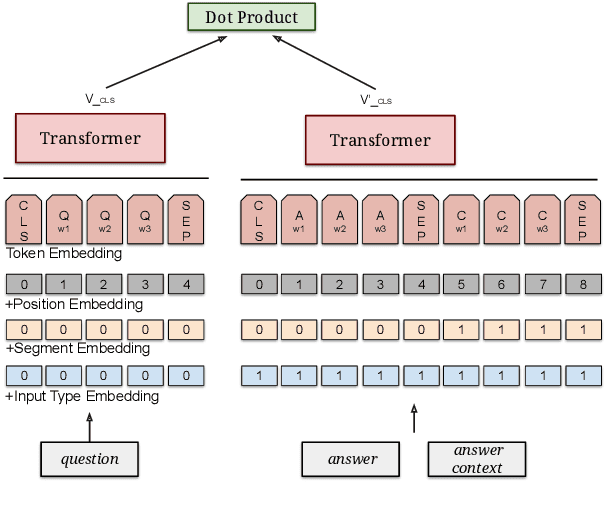

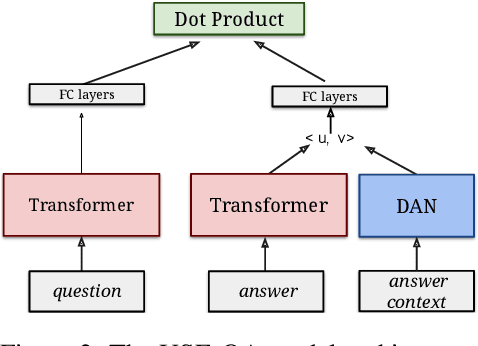
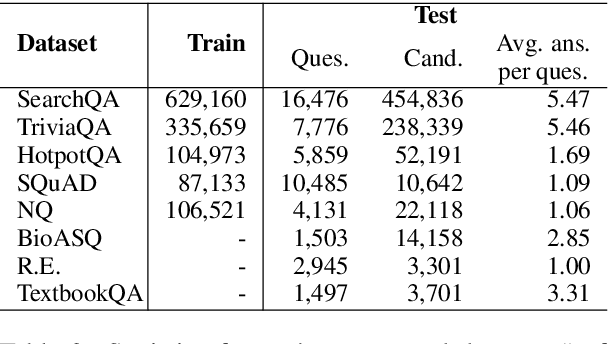
Retrieval question answering (ReQA) is the task of retrieving a sentence-level answer to a question from an open corpus (Ahmad et al.,2019).This paper presents MultiReQA, anew multi-domain ReQA evaluation suite com-posed of eight retrieval QA tasks drawn from publicly available QA datasets. We provide the first systematic retrieval based evaluation over these datasets using two supervised neural models, based on fine-tuning BERT andUSE-QA models respectively, as well as a surprisingly strong information retrieval baseline,BM25. Five of these tasks contain both train-ing and test data, while three contain test data only. Performance on the five tasks with train-ing data shows that while a general model covering all domains is achievable, the best performance is often obtained by training exclusively on in-domain data.
Bridging the Gap for Tokenizer-Free Language Models
Aug 27, 2019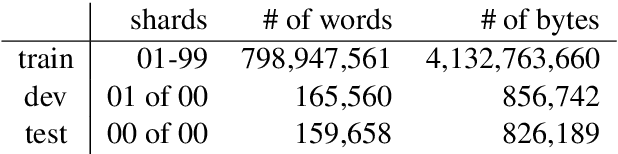
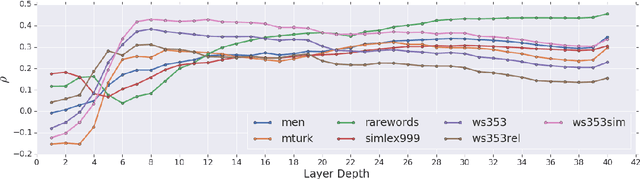
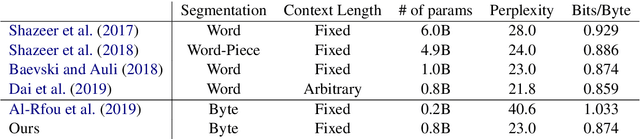
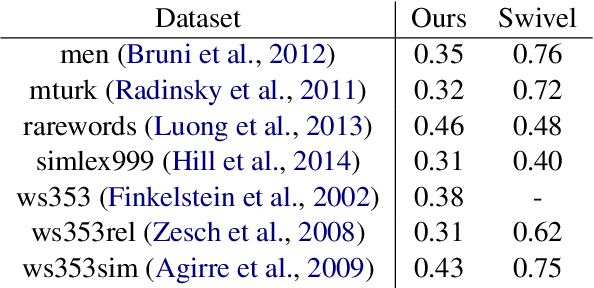
Purely character-based language models (LMs) have been lagging in quality on large scale datasets, and current state-of-the-art LMs rely on word tokenization. It has been assumed that injecting the prior knowledge of a tokenizer into the model is essential to achieving competitive results. In this paper, we show that contrary to this conventional wisdom, tokenizer-free LMs with sufficient capacity can achieve competitive performance on a large scale dataset. We train a vanilla transformer network with 40 self-attention layers on the One Billion Word (lm1b) benchmark and achieve a new state of the art for tokenizer-free LMs, pushing these models to be on par with their word-based counterparts.
Multilingual Universal Sentence Encoder for Semantic Retrieval
Jul 09, 2019We introduce two pre-trained retrieval focused multilingual sentence encoding models, respectively based on the Transformer and CNN model architectures. The models embed text from 16 languages into a single semantic space using a multi-task trained dual-encoder that learns tied representations using translation based bridge tasks (Chidambaram al., 2018). The models provide performance that is competitive with the state-of-the-art on: semantic retrieval (SR), translation pair bitext retrieval (BR) and retrieval question answering (ReQA). On English transfer learning tasks, our sentence-level embeddings approach, and in some cases exceed, the performance of monolingual, English only, sentence embedding models. Our models are made available for download on TensorFlow Hub.
Hierarchical Document Encoder for Parallel Corpus Mining
Jun 30, 2019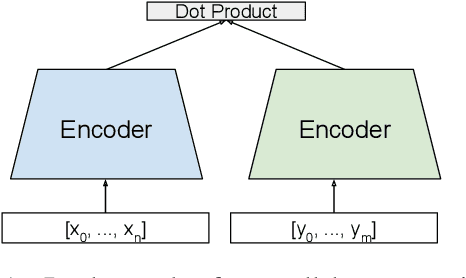
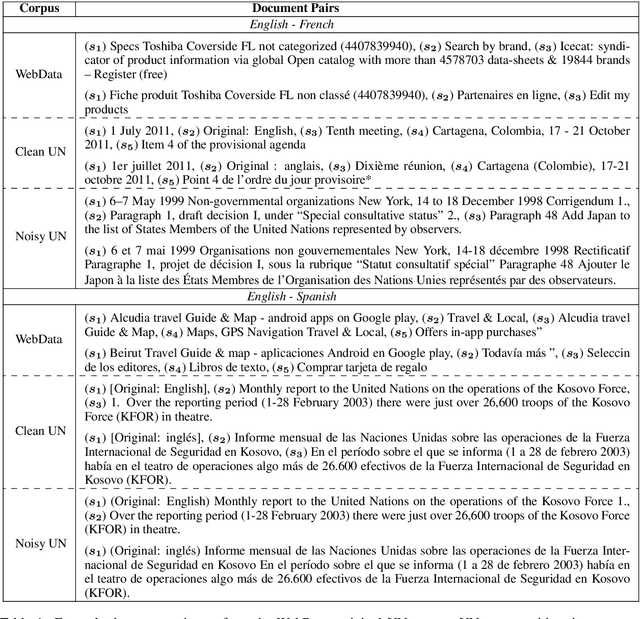
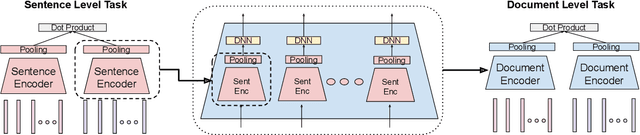
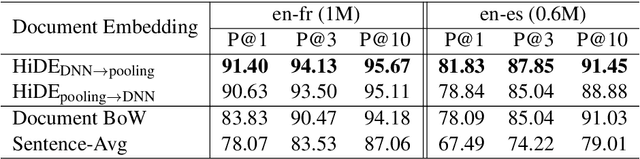
We explore using multilingual document embeddings for nearest neighbor mining of parallel data. Three document-level representations are investigated: (i) document embeddings generated by simply averaging multilingual sentence embeddings; (ii) a neural bag-of-words (BoW) document encoding model; (iii) a hierarchical multilingual document encoder (HiDE) that builds on our sentence-level model. The results show document embeddings derived from sentence-level averaging are surprisingly effective for clean datasets, but suggest models trained hierarchically at the document-level are more effective on noisy data. Analysis experiments demonstrate our hierarchical models are very robust to variations in the underlying sentence embedding quality. Using document embeddings trained with HiDE achieves state-of-the-art performance on United Nations (UN) parallel document mining, 94.9% P@1 for en-fr and 97.3% P@1 for en-es.
Improving Multilingual Sentence Embedding using Bi-directional Dual Encoder with Additive Margin Softmax
Feb 22, 2019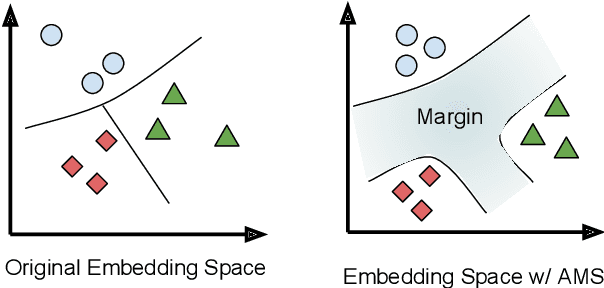


In this paper, we present an approach to learn multilingual sentence embeddings using a bi-directional dual-encoder with additive margin softmax. The embeddings are able to achieve state-of-the-art results on the United Nations (UN) parallel corpus retrieval task. In all the languages tested, the system achieves P@1 of 86% or higher. We use pairs retrieved by our approach to train NMT models that achieve similar performance to models trained on gold pairs. We explore simple document-level embeddings constructed by averaging our sentence embeddings. On the UN document-level retrieval task, document embeddings achieve around 97% on P@1 for all experimented language pairs. Lastly, we evaluate the proposed model on the BUCC mining task. The learned embeddings with raw cosine similarity scores achieve competitive results compared to current state-of-the-art models, and with a second-stage scorer we achieve a new state-of-the-art level on this task.
Character-Level Language Modeling with Deeper Self-Attention
Aug 09, 2018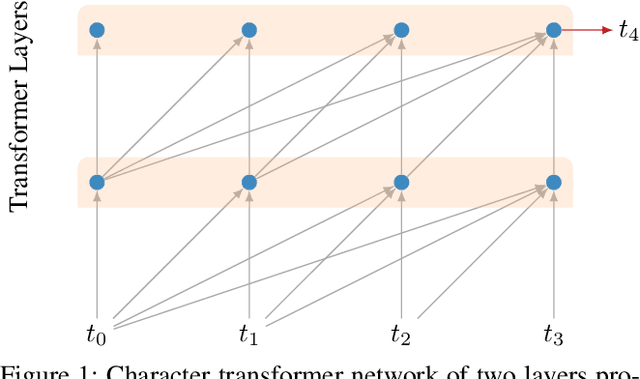
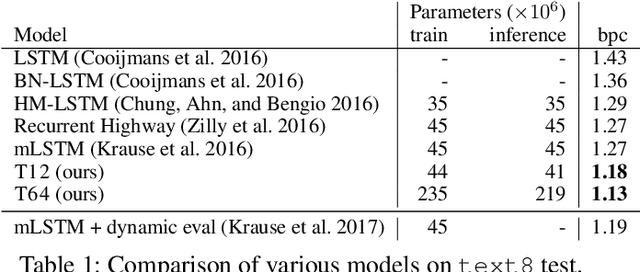
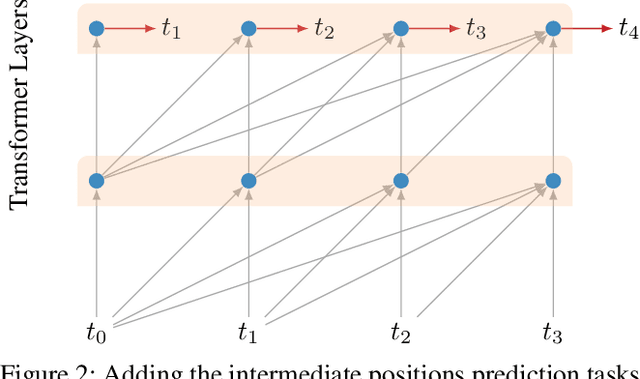
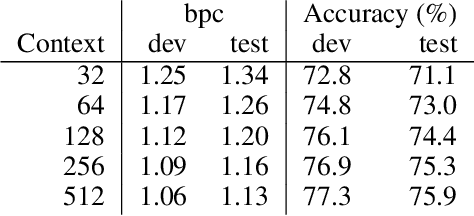
LSTMs and other RNN variants have shown strong performance on character-level language modeling. These models are typically trained using truncated backpropagation through time, and it is common to assume that their success stems from their ability to remember long-term contexts. In this paper, we show that a deep (64-layer) transformer model with fixed context outperforms RNN variants by a large margin, achieving state of the art on two popular benchmarks- 1.13 bits per character on text8 and 1.06 on enwik8. To get good results at this depth, we show that it is important to add auxiliary losses, both at intermediate network layers and intermediate sequence positions.
Effective Parallel Corpus Mining using Bilingual Sentence Embeddings
Aug 02, 2018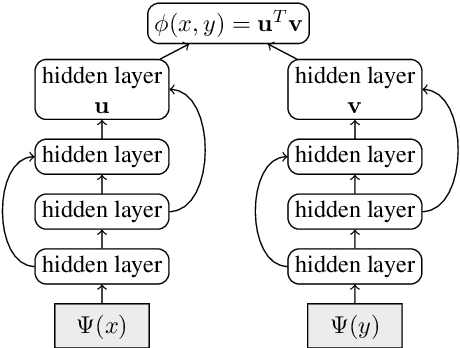

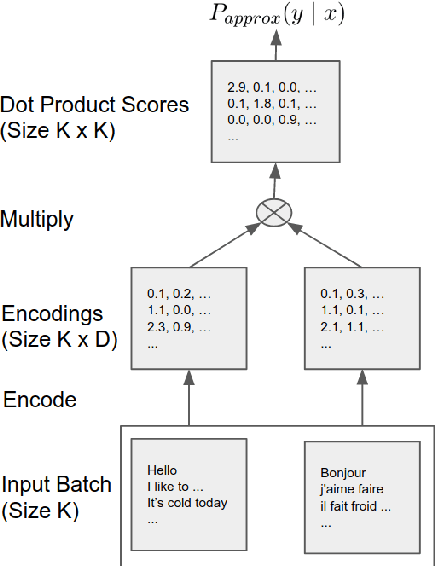
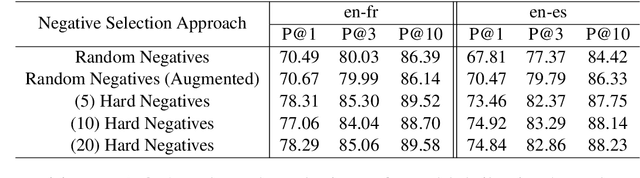
This paper presents an effective approach for parallel corpus mining using bilingual sentence embeddings. Our embedding models are trained to produce similar representations exclusively for bilingual sentence pairs that are translations of each other. This is achieved using a novel training method that introduces hard negatives consisting of sentences that are not translations but that have some degree of semantic similarity. The quality of the resulting embeddings are evaluated on parallel corpus reconstruction and by assessing machine translation systems trained on gold vs. mined sentence pairs. We find that the sentence embeddings can be used to reconstruct the United Nations Parallel Corpus at the sentence level with a precision of 48.9% for en-fr and 54.9% for en-es. When adapted to document level matching, we achieve a parallel document matching accuracy that is comparable to the significantly more computationally intensive approach of [Jakob 2010]. Using reconstructed parallel data, we are able to train NMT models that perform nearly as well as models trained on the original data (within 1-2 BLEU).