 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecialized Document Embeddings for Aspect-based Similarity of Research Papers
Mar 28, 2022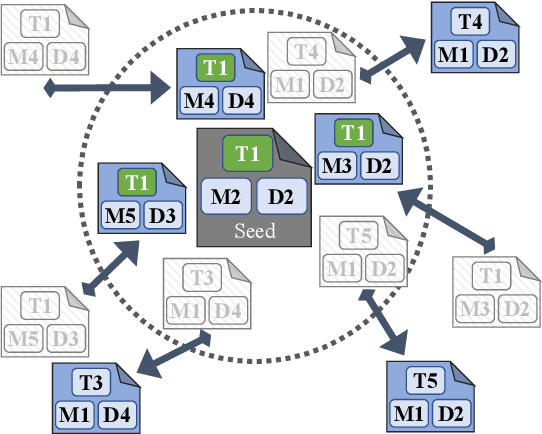
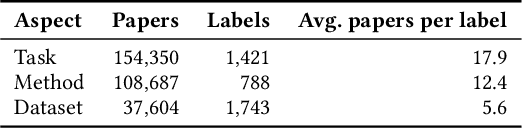
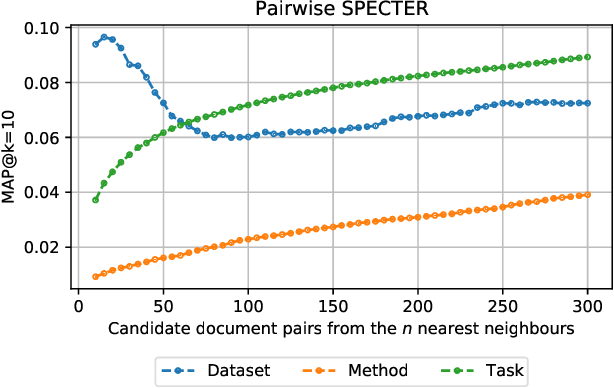
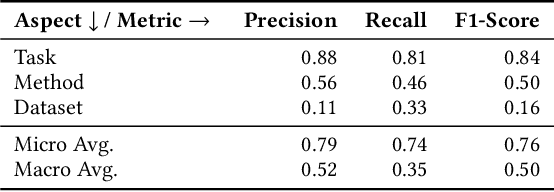
Document embeddings and similarity measures underpin content-based recommender systems, whereby a document is commonly represented as a single generic embedding. However, similarity computed on single vector representations provides only one perspective on document similarity that ignores which aspects make two documents alike. To address this limitation, aspect-based similarity measures have been developed using document segmentation or pairwise multi-class document classification. While segmentation harms the document coherence, the pairwise classification approach scales poorly to large scale corpora. In this paper, we treat aspect-based similarity as a classical vector similarity problem in aspect-specific embedding spaces. We represent a document not as a single generic embedding but as multiple specialized embeddings. Our approach avoids document segmentation and scales linearly w.r.t.the corpus size. In an empirical study, we use the Papers with Code corpus containing 157,606 research papers and consider the task, method, and dataset of the respective research papers as their aspects. We compare and analyze three generic document embeddings, six specialized document embeddings and a pairwise classification baseline in the context of research paper recommendations. As generic document embeddings, we consider FastText, SciBERT, and SPECTER. To compute the specialized document embeddings, we compare three alternative methods inspired by retrofitting, fine-tuning, and Siamese networks. In our experiments, Siamese SciBERT achieved the highest scores. Additional analyses indicate an implicit bias of the generic document embeddings towards the dataset aspect and against the method aspect of each research paper. Our approach of aspect-based document embeddings mitigates potential risks arising from implicit biases by making them explicit.
HiStruct+: Improving Extractive Text Summarization with Hierarchical Structure Information
Mar 17, 2022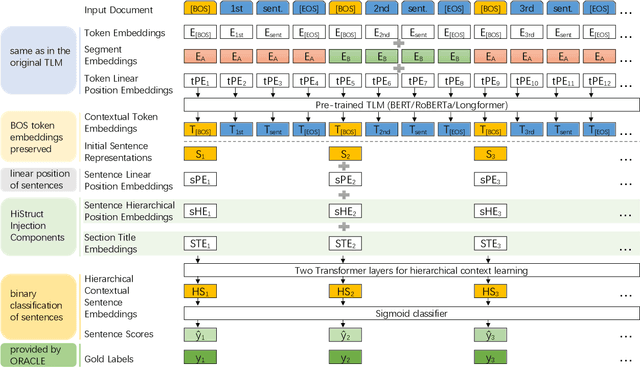
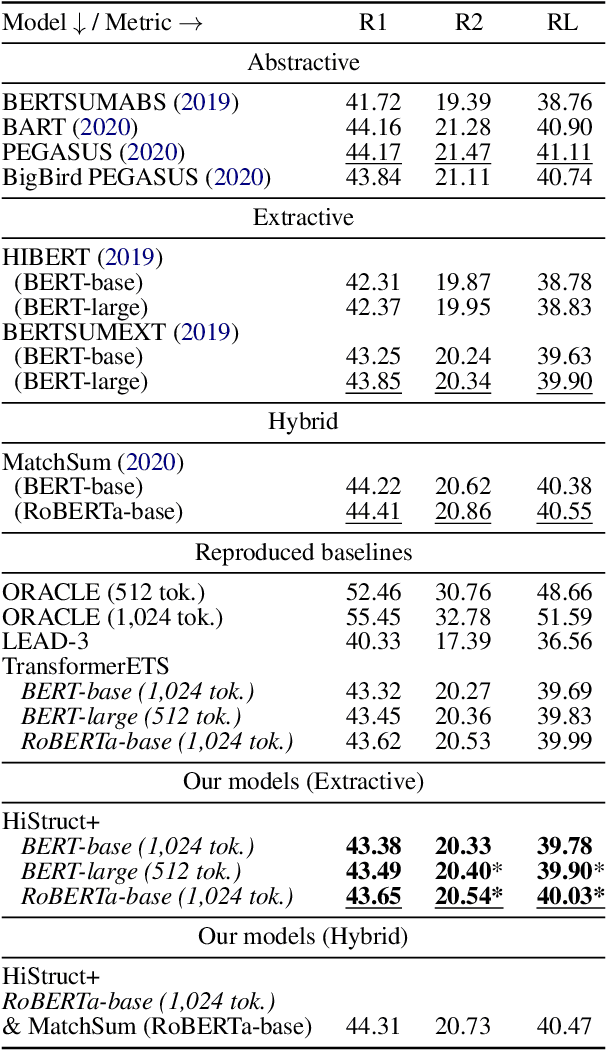
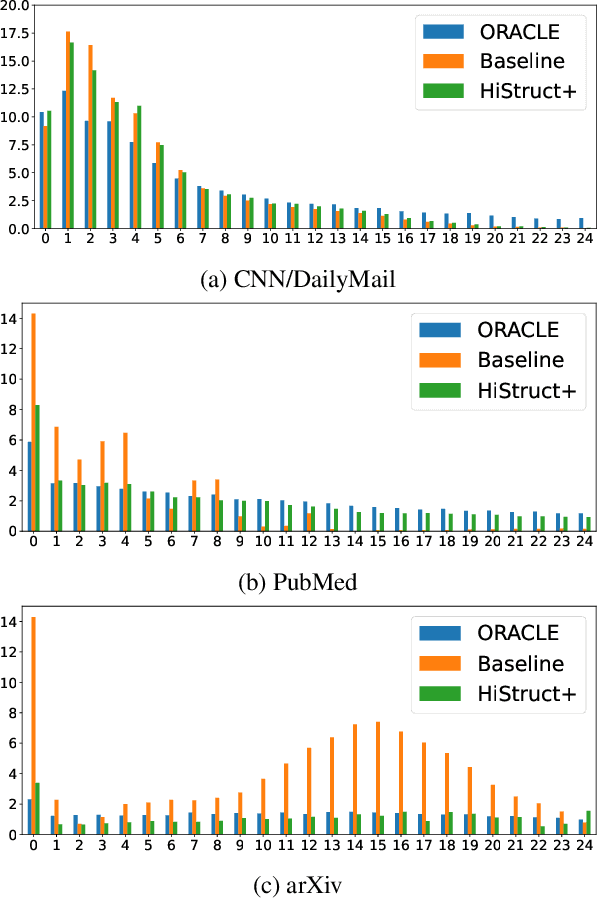
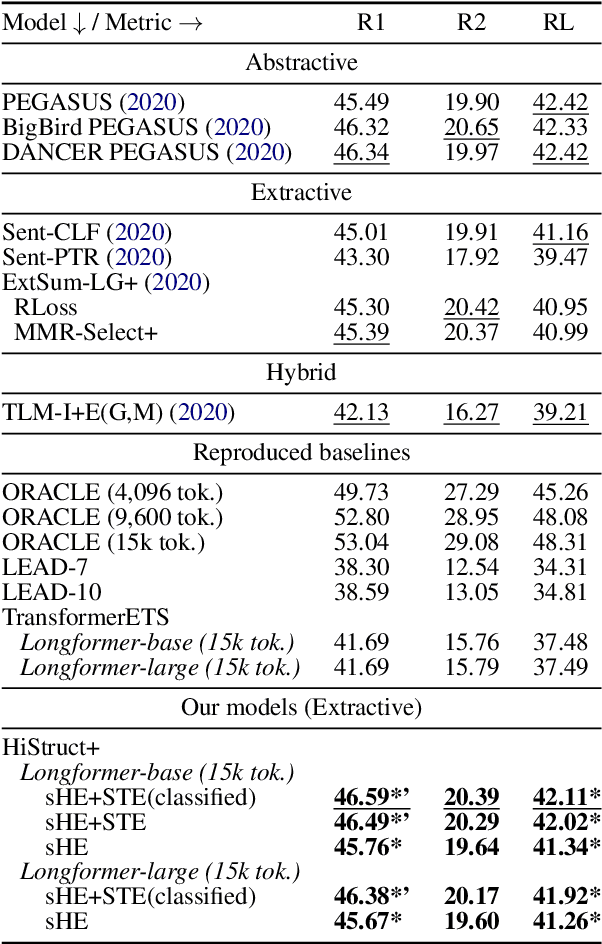
Transformer-based language models usually treat texts as linear sequences. However, most texts also have an inherent hierarchical structure, i.e., parts of a text can be identified using their position in this hierarchy. In addition, section titles usually indicate the common topic of their respective sentences. We propose a novel approach to formulate, extract, encode and inject hierarchical structure information explicitly into an extractive summarization model based on a pre-trained, encoder-only Transformer language model (HiStruct+ model), which improves SOTA ROUGEs for extractive summarization on PubMed and arXiv substantially. Using various experimental settings on three datasets (i.e., CNN/DailyMail, PubMed and arXiv), our HiStruct+ model outperforms a strong baseline collectively, which differs from our model only in that the hierarchical structure information is not injected. It is also observed that the more conspicuous hierarchical structure the dataset has, the larger improvements our method gains. The ablation study demonstrates that the hierarchical position information is the main contributor to our model's SOTA performance.
Neighborhood Contrastive Learning for Scientific Document Representations with Citation Embeddings
Feb 14, 2022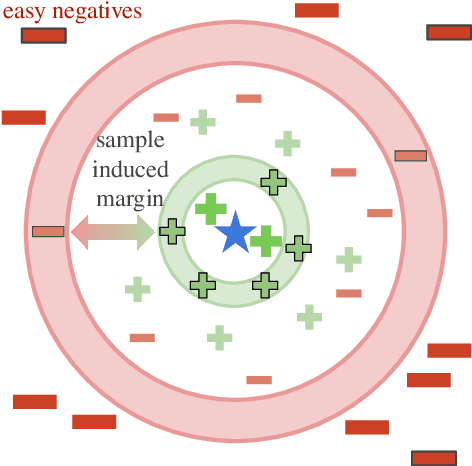
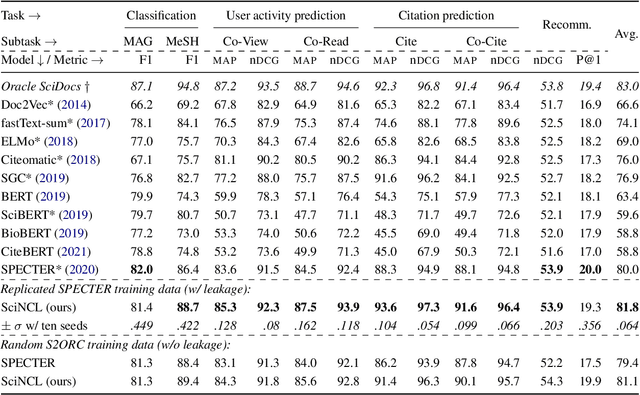
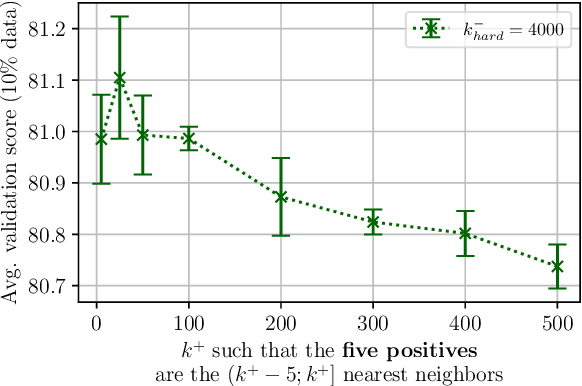
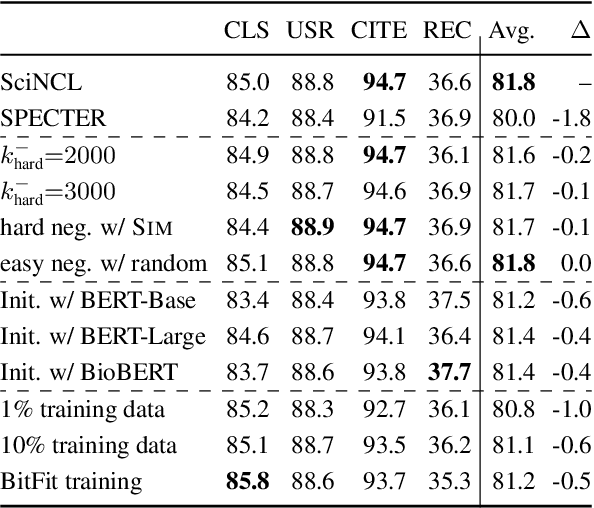
Learning scientific document representations can be substantially improved through contrastive learning objectives, where the challenge lies in creating positive and negative training samples that encode the desired similarity semantics. Prior work relies on discrete citation relations to generate contrast samples. However, discrete citations enforce a hard cut-off to similarity. This is counter-intuitive to similarity-based learning, and ignores that scientific papers can be very similar despite lacking a direct citation - a core problem of finding related research. Instead, we use controlled nearest neighbor sampling over citation graph embeddings for contrastive learning. This control allows us to learn continuous similarity, to sample hard-to-learn negatives and positives, and also to avoid collisions between negative and positive samples by controlling the sampling margin between them. The resulting method SciNCL outperforms the state-of-the-art on the SciDocs benchmark. Furthermore, we demonstrate that it can train (or tune) models sample-efficiently, and that it can be combined with recent training-efficient methods. Perhaps surprisingly, even training a general-domain language model this way outperforms baselines pretrained in-domain.
A Qualitative Evaluation of User Preference for Link-based vs. Text-based Recommendations of Wikipedia Articles
Sep 16, 2021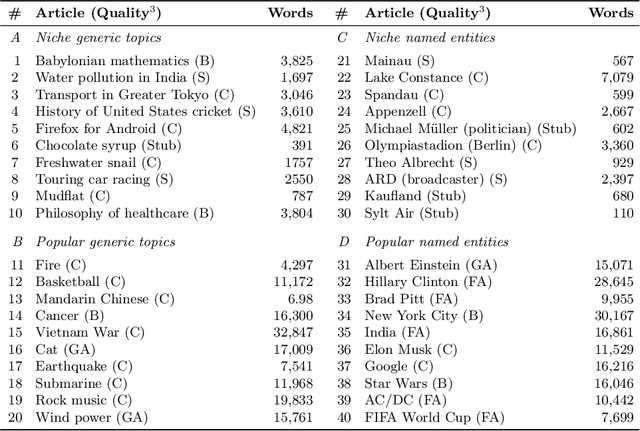
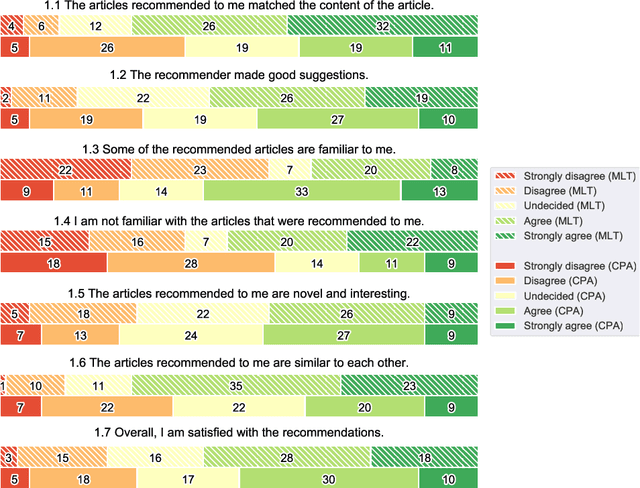
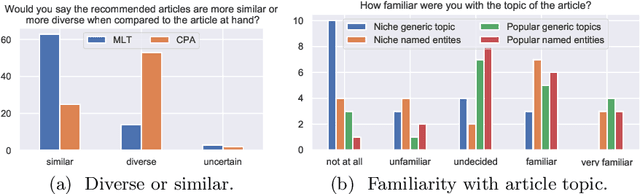
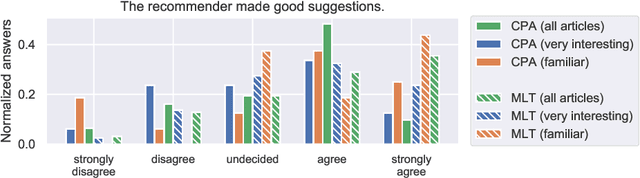
Literature recommendation systems (LRS) assist readers in the discovery of relevant content from the overwhelming amount of literature available. Despite the widespread adoption of LRS, there is a lack of research on the user-perceived recommendation characteristics for fundamentally different approaches to content-based literature recommendation. To complement existing quantitative studies on literature recommendation, we present qualitative study results that report on users' perceptions for two contrasting recommendation classes: (1) link-based recommendation represented by the Co-Citation Proximity (CPA) approach, and (2) text-based recommendation represented by Lucene's MoreLikeThis (MLT) algorithm. The empirical data analyzed in our study with twenty users and a diverse set of 40 Wikipedia articles indicate a noticeable difference between text- and link-based recommendation generation approaches along several key dimensions. The text-based MLT method receives higher satisfaction ratings in terms of user-perceived similarity of recommended articles. In contrast, the CPA approach receives higher satisfaction scores in terms of diversity and serendipity of recommendations. We conclude that users of literature recommendation systems can benefit most from hybrid approaches that combine both link- and text-based approaches, where the user's information needs and preferences should control the weighting for the approaches used. The optimal weighting of multiple approaches used in a hybrid recommendation system is highly dependent on a user's shifting needs.
Evaluating Document Representations for Content-based Legal Literature Recommendations
Apr 28, 2021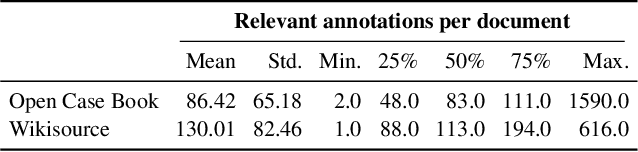
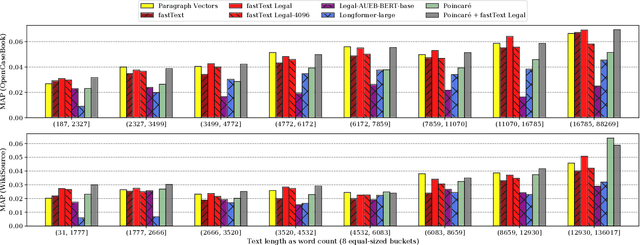
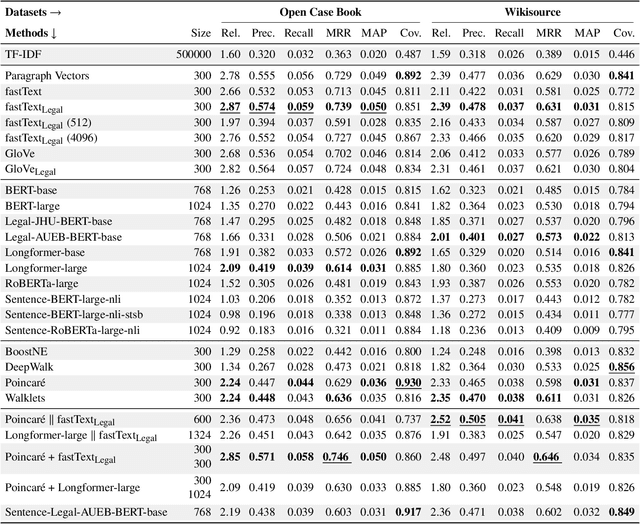
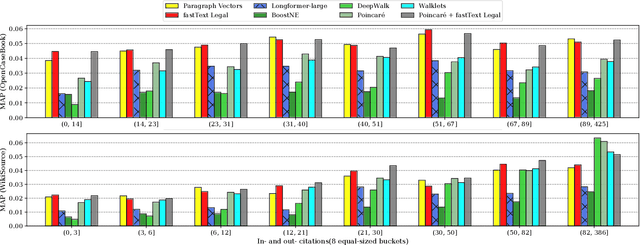
Recommender systems assist legal professionals in finding relevant literature for supporting their case. Despite its importance for the profession, legal applications do not reflect the latest advances in recommender systems and representation learning research. Simultaneously, legal recommender systems are typically evaluated in small-scale user study without any public available benchmark datasets. Thus, these studies have limited reproducibility. To address the gap between research and practice, we explore a set of state-of-the-art document representation methods for the task of retrieving semantically related US case law. We evaluate text-based (e.g., fastText, Transformers), citation-based (e.g., DeepWalk, Poincar\'e), and hybrid methods. We compare in total 27 methods using two silver standards with annotations for 2,964 documents. The silver standards are newly created from Open Case Book and Wikisource and can be reused under an open license facilitating reproducibility. Our experiments show that document representations from averaged fastText word vectors (trained on legal corpora) yield the best results, closely followed by Poincar\'e citation embeddings. Combining fastText and Poincar\'e in a hybrid manner further improves the overall result. Besides the overall performance, we analyze the methods depending on document length, citation count, and the coverage of their recommendations. We make our source code, models, and datasets publicly available at https://github.com/malteos/legal-document-similarity/.
Aspect-based Document Similarity for Research Papers
Oct 13, 2020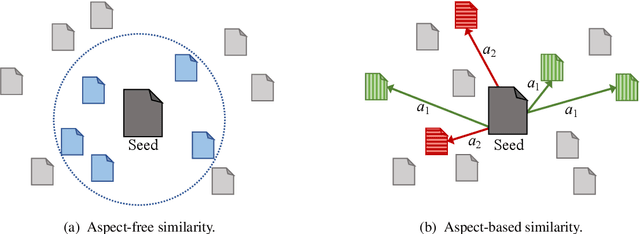
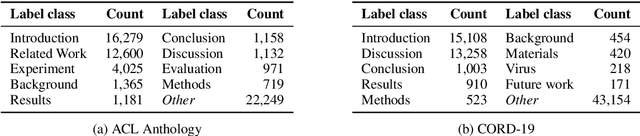
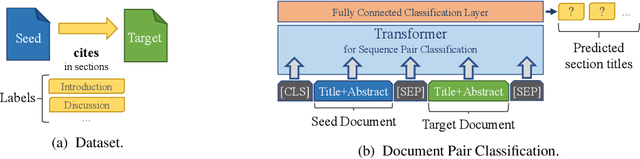
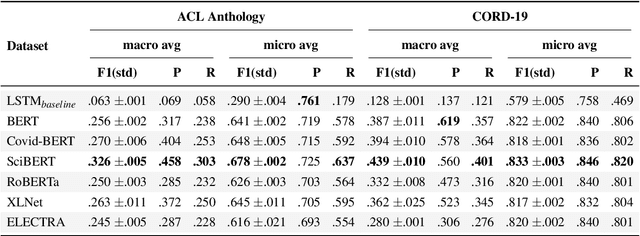
Traditional document similarity measures provide a coarse-grained distinction between similar and dissimilar documents. Typically, they do not consider in what aspects two documents are similar. This limits the granularity of applications like recommender systems that rely on document similarity. In this paper, we extend similarity with aspect information by performing a pairwise document classification task. We evaluate our aspect-based document similarity for research papers. Paper citations indicate the aspect-based similarity, i.e., the section title in which a citation occurs acts as a label for the pair of citing and cited paper. We apply a series of Transformer models such as RoBERTa, ELECTRA, XLNet, and BERT variations and compare them to an LSTM baseline. We perform our experiments on two newly constructed datasets of 172,073 research paper pairs from the ACL Anthology and CORD-19 corpus. Our results show SciBERT as the best performing system. A qualitative examination validates our quantitative results. Our findings motivate future research of aspect-based document similarity and the development of a recommender system based on the evaluated techniques. We make our datasets, code, and trained models publicly available.
Towards an Open Platform for Legal Information
May 27, 2020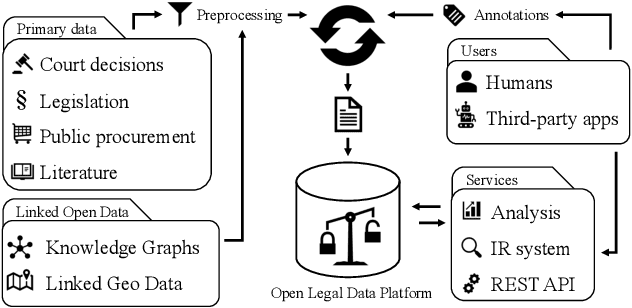

Recent advances in the area of legal information systems have led to a variety of applications that promise support in processing and accessing legal documents. Unfortunately, these applications have various limitations, e.g., regarding scope or extensibility. Furthermore, we do not observe a trend towards open access in digital libraries in the legal domain as we observe in other domains, e.g., economics of computer science. To improve open access in the legal domain, we present our approach for an open source platform to transparently process and access Legal Open Data. This enables the sustainable development of legal applications by offering a single technology stack. Moreover, the approach facilitates the development and deployment of new technologies. As proof of concept, we implemented six technologies and generated metadata for more than 250,000 German laws and court decisions. Thus, we can provide users of our platform not only access to legal documents, but also the contained information.
QURATOR: Innovative Technologies for Content and Data Curation
Apr 25, 2020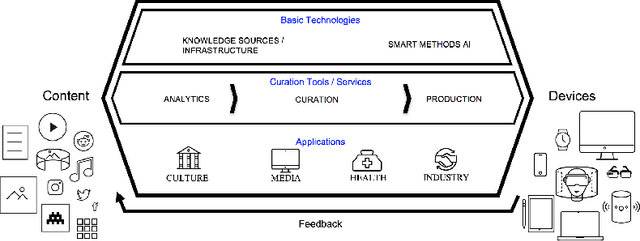
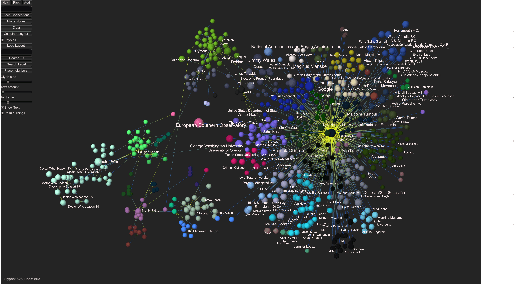
In all domains and sectors, the demand for intelligent systems to support the processing and generation of digital content is rapidly increasing. The availability of vast amounts of content and the pressure to publish new content quickly and in rapid succession requires faster, more efficient and smarter processing and generation methods. With a consortium of ten partners from research and industry and a broad range of expertise in AI, Machine Learning and Language Technologies, the QURATOR project, funded by the German Federal Ministry of Education and Research, develops a sustainable and innovative technology platform that provides services to support knowledge workers in various industries to address the challenges they face when curating digital content. The project's vision and ambition is to establish an ecosystem for content curation technologies that significantly pushes the current state of the art and transforms its region, the metropolitan area Berlin-Brandenburg, into a global centre of excellence for curation technologies.
Towards Discourse Parsing-inspired Semantic Storytelling
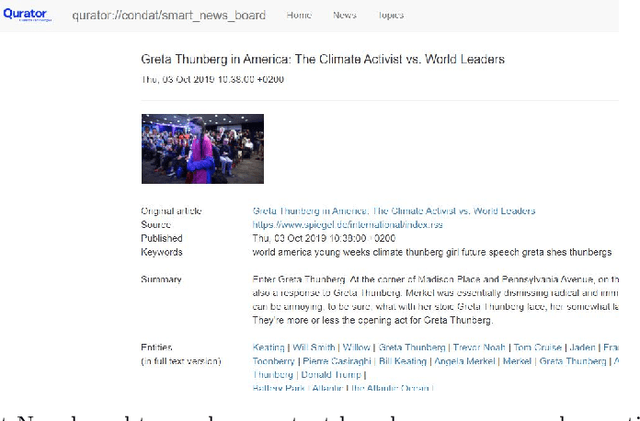
Apr 25, 2020

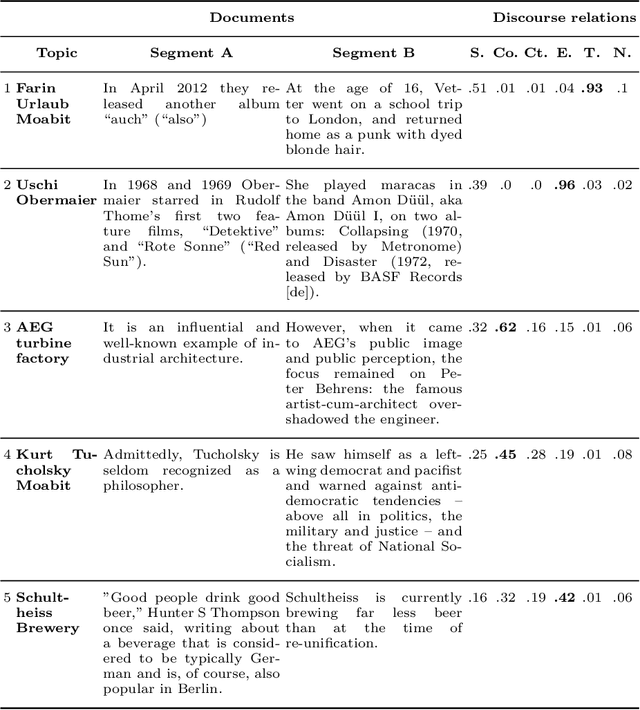
Previous work of ours on Semantic Storytelling uses text analytics procedures including Named Entity Recognition and Event Detection. In this paper, we outline our longer-term vision on Semantic Storytelling and describe the current conceptual and technical approach. In the project that drives our research we develop AI-based technologies that are verified by partners from industry. One long-term goal is the development of an approach for Semantic Storytelling that has broad coverage and that is, furthermore, robust. We provide first results on experiments that involve discourse parsing, applied to a concrete use case, "Explore the Neighbourhood!", which is based on a semi-automatically collected data set with documents about noteworthy people in one of Berlin's districts. Though automatically obtaining annotations for coherence relations from plain text is a non-trivial challenge, our preliminary results are promising. We envision our approach to be combined with additional features (NER, coreference resolution, knowledge graphs
Named Entities in Medical Case Reports: Corpus and Experiments
Mar 29, 2020
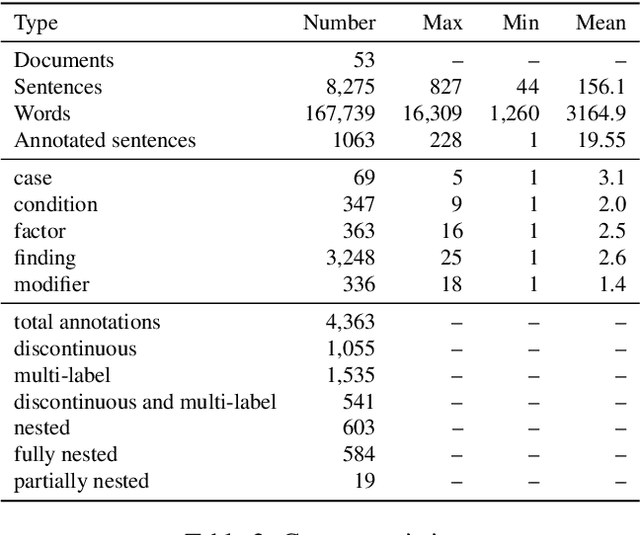

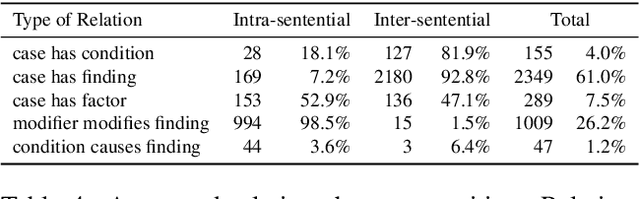
We present a new corpus comprising annotations of medical entities in case reports, originating from PubMed Central's open access library. In the case reports, we annotate cases, conditions, findings, factors and negation modifiers. Moreover, where applicable, we annotate relations between these entities. As such, this is the first corpus of this kind made available to the scientific community in English. It enables the initial investigation of automatic information extraction from case reports through tasks like Named Entity Recognition, Relation Extraction and (sentence/paragraph) relevance detection. Additionally, we present four strong baseline systems for the detection of medical entities made available through the annotated dataset.