 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReFace: Real-time Adversarial Attacks on Face Recognition Systems
Jun 09, 2022
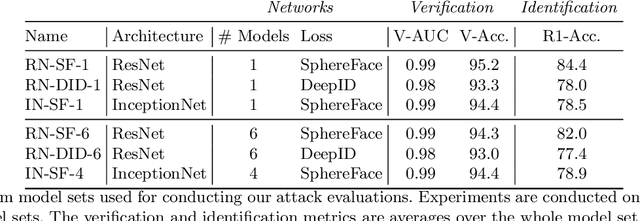
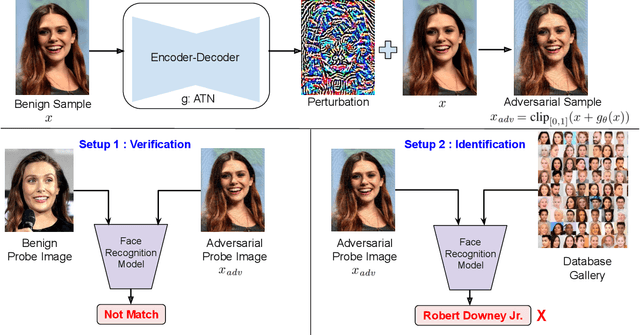
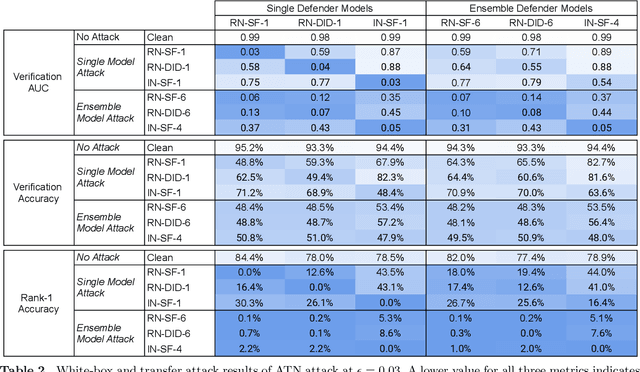
Deep neural network based face recognition models have been shown to be vulnerable to adversarial examples. However, many of the past attacks require the adversary to solve an input-dependent optimization problem using gradient descent which makes the attack impractical in real-time. These adversarial examples are also tightly coupled to the attacked model and are not as successful in transferring to different models. In this work, we propose ReFace, a real-time, highly-transferable attack on face recognition models based on Adversarial Transformation Networks (ATNs). ATNs model adversarial example generation as a feed-forward neural network. We find that the white-box attack success rate of a pure U-Net ATN falls substantially short of gradient-based attacks like PGD on large face recognition datasets. We therefore propose a new architecture for ATNs that closes this gap while maintaining a 10000x speedup over PGD. Furthermore, we find that at a given perturbation magnitude, our ATN adversarial perturbations are more effective in transferring to new face recognition models than PGD. ReFace attacks can successfully deceive commercial face recognition services in a transfer attack setting and reduce face identification accuracy from 82% to 16.4% for AWS SearchFaces API and Azure face verification accuracy from 91% to 50.1%.
Privacy Leakage Avoidance with Switching Ensembles
Nov 18, 2019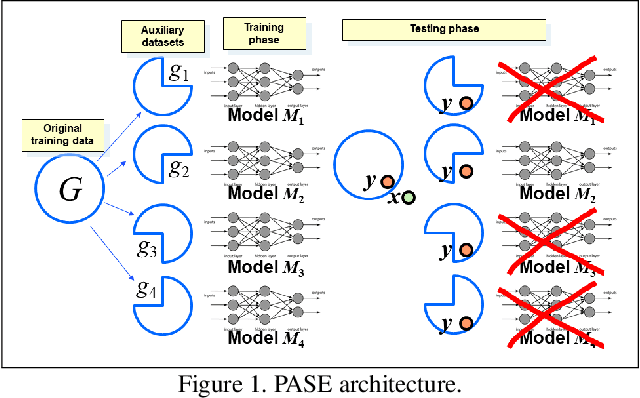
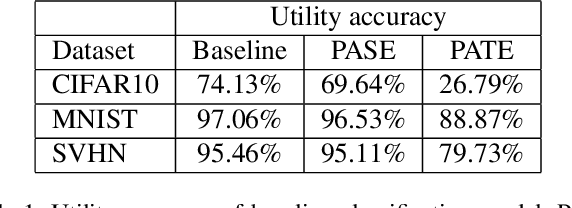
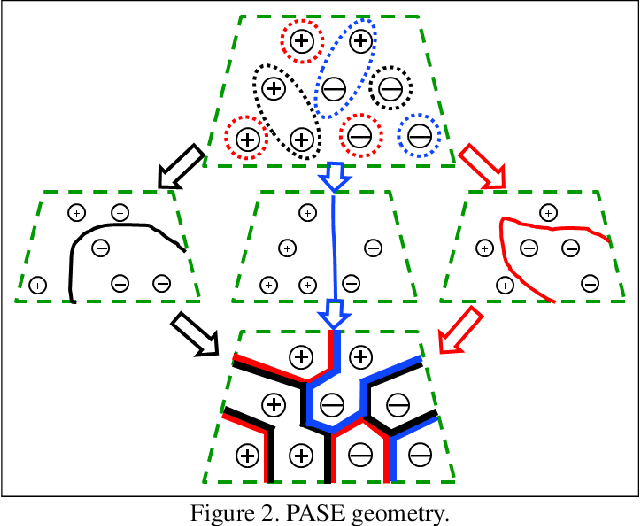
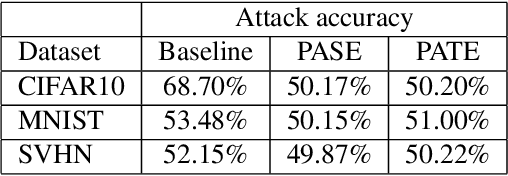
We consider membership inference attacks, one of the main privacy issues in machine learning. These recently developed attacks have been proven successful in determining, with confidence better than a random guess, whether a given sample belongs to the dataset on which the attacked machine learning model was trained. Several approaches have been developed to mitigate this privacy leakage but the tradeoff performance implications of these defensive mechanisms (i.e., accuracy and utility of the defended machine learning model) are not well studied yet. We propose a novel approach of privacy leakage avoidance with switching ensembles (PASE), which both protects against current membership inference attacks and does that with very small accuracy penalty, while requiring acceptable increase in training and inference time. We test our PASE method, along with the the current state-of-the-art PATE approach, on three calibration image datasets and analyze their tradeoffs.
Membership Model Inversion Attacks for Deep Networks
Oct 09, 2019
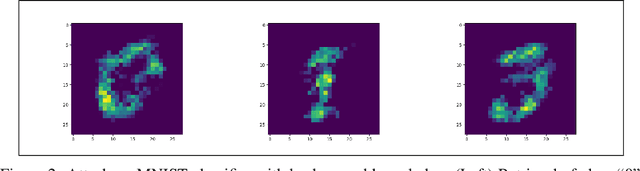
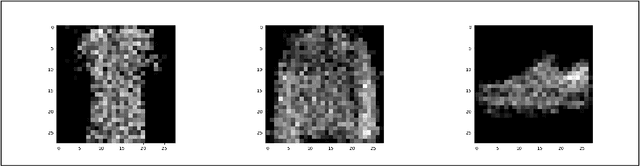

With the increasing adoption of AI, inherent security and privacy vulnerabilities formachine learning systems are being discovered. One such vulnerability makes itpossible for an adversary to obtain private information about the types of instancesused to train the targeted machine learning model. This so-called model inversionattack is based on sequential leveraging of classification scores towards obtaininghigh confidence representations for various classes. However, for deep networks,such procedures usually lead to unrecognizable representations that are uselessfor the adversary. In this paper, we introduce a more realistic definition of modelinversion, where the adversary is aware of the general purpose of the attackedmodel (for instance, whether it is an OCR system or a facial recognition system),and the goal is to find realistic class representations within the corresponding lower-dimensional manifold (of, respectively, general symbols or general faces). To thatend, we leverage properties of generative adversarial networks for constructinga connected lower-dimensional manifold, and demonstrate the efficiency of ourmodel inversion attack that is carried out within that manifold.
A Random Subspace Technique That Is Resistant to a Limited Number of Features Corrupted by an Adversary
Feb 19, 2019

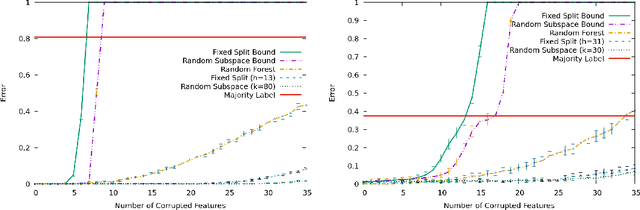
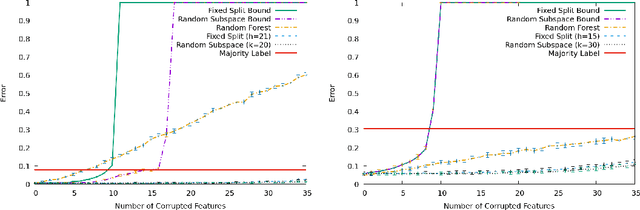
In this paper, we consider batch supervised learning where an adversary is allowed to corrupt instances with arbitrarily large noise. The adversary is allowed to corrupt any $l$ features in each instance and the adversary can change their values in any way. This noise is introduced on test instances and the algorithm receives no label feedback for these instances. We provide several subspace voting techniques that can be used to transform existing algorithms and prove data-dependent performance bounds in this setting. The key insight to our results is that we set our parameters so that a significant fraction of the voting hypotheses do not contain corrupt features and, for many real world problems, these uncorrupt hypotheses are sufficient to achieve high accuracy. We empirically validate our approach on several datasets including three new datasets that deal with side channel electromagnetic information.