 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Gaussian Denoiser Epistemic Uncertainty and Decoupled Dual-Attention Fusion
Jan 22, 2021
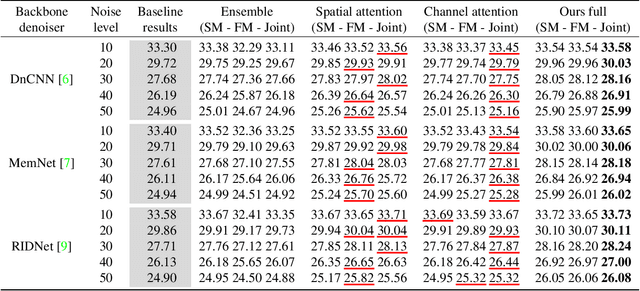
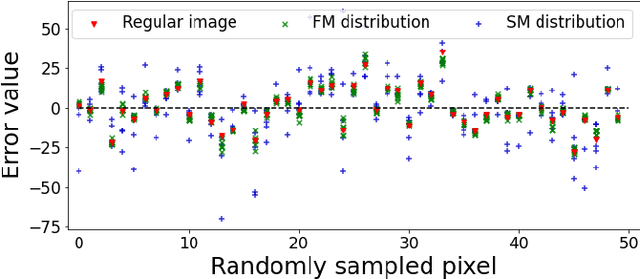
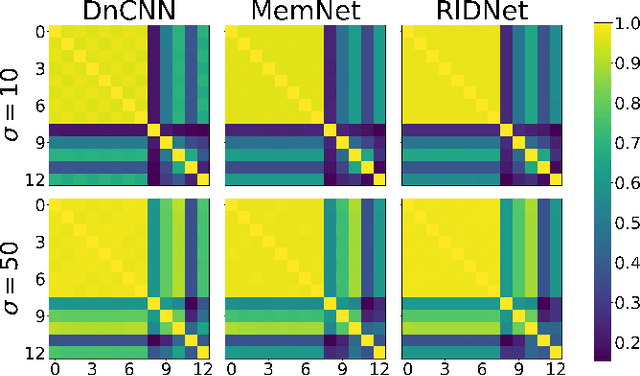
Following the performance breakthrough of denoising networks, improvements have come chiefly through novel architecture designs and increased depth. While novel denoising networks were designed for real images coming from different distributions, or for specific applications, comparatively small improvement was achieved on Gaussian denoising. The denoising solutions suffer from epistemic uncertainty that can limit further advancements. This uncertainty is traditionally mitigated through different ensemble approaches. However, such ensembles are prohibitively costly with deep networks, which are already large in size. Our work focuses on pushing the performance limits of state-of-the-art methods on Gaussian denoising. We propose a model-agnostic approach for reducing epistemic uncertainty while using only a single pretrained network. We achieve this by tapping into the epistemic uncertainty through augmented and frequency-manipulated images to obtain denoised images with varying error. We propose an ensemble method with two decoupled attention paths, over the pixel domain and over that of our different manipulations, to learn the final fusion. Our results significantly improve over the state-of-the-art baselines and across varying noise levels.
BIGPrior: Towards Decoupling Learned Prior Hallucination and Data Fidelity in Image Restoration
Nov 03, 2020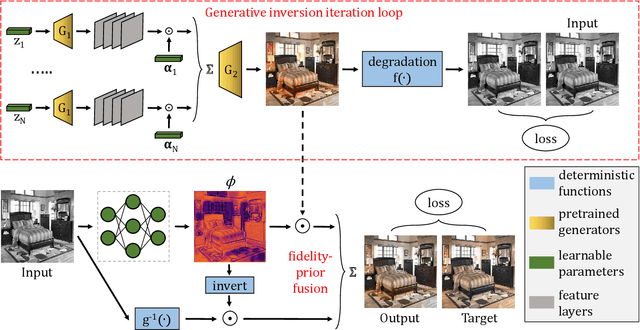



Image restoration encompasses fundamental image processing tasks that have been addressed with different algorithms and deep learning methods. Classical restoration algorithms leverage a variety of priors, either implicitly or explicitly. Their priors are hand-designed and their corresponding weights are heuristically assigned. Thus, deep learning methods often produce superior restoration quality. Deep networks are, however, capable of strong and hardly-predictable hallucinations. Networks jointly and implicitly learn to be faithful to the observed data while learning an image prior, and the separation of original and hallucinated data downstream is then not possible. This limits their wide-spread adoption in restoration applications. Furthermore, it is often the hallucinated part that is victim to degradation-model overfitting. We present an approach with decoupled network-prior hallucination and data fidelity. We refer to our framework as the Bayesian Integration of a Generative Prior (BIGPrior). Our BIGPrior method is rooted in a Bayesian restoration framework, and tightly connected to classical restoration methods. In fact, our approach can be viewed as a generalization of a large family of classical restoration algorithms. We leverage a recent network inversion method to extract image prior information from a generative network. We show on image colorization, inpainting, and denoising that our framework consistently improves the prior results through good integration of data fidelity. Our method, though partly reliant on the quality of the generative network inversion, is competitive with state-of-the-art supervised and task-specific restoration methods. It also provides an additional metric that sets forth the degree of prior reliance per pixel. Indeed, the per pixel contributions of the decoupled data fidelity and prior terms are readily available in our proposed framework.
AIM 2020: Scene Relighting and Illumination Estimation Challenge
Sep 27, 2020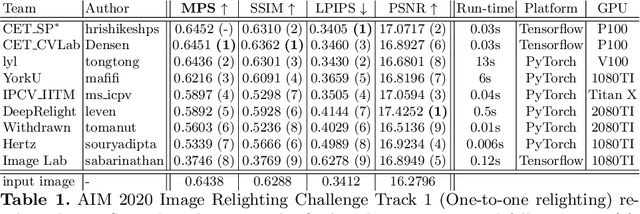

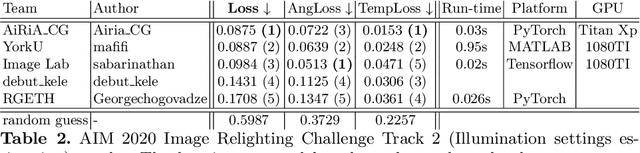

We review the AIM 2020 challenge on virtual image relighting and illumination estimation. This paper presents the novel VIDIT dataset used in the challenge and the different proposed solutions and final evaluation results over the 3 challenge tracks. The first track considered one-to-one relighting; the objective was to relight an input photo of a scene with a different color temperature and illuminant orientation (i.e., light source position). The goal of the second track was to estimate illumination settings, namely the color temperature and orientation, from a given image. Lastly, the third track dealt with any-to-any relighting, thus a generalization of the first track. The target color temperature and orientation, rather than being pre-determined, are instead given by a guide image. Participants were allowed to make use of their track 1 and 2 solutions for track 3. The tracks had 94, 52, and 56 registered participants, respectively, leading to 20 confirmed submissions in the final competition stage.
VIDIT: Virtual Image Dataset for Illumination Transfer
May 13, 2020
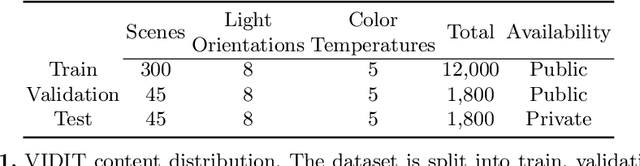
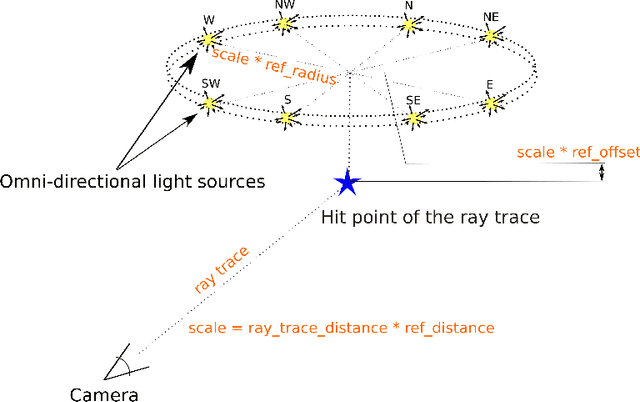

Deep image relighting is gaining more interest lately, as it allows photo enhancement through illumination-specific retouching without human effort. Aside from aesthetic enhancement and photo montage, image relighting is valuable for domain adaptation, whether to augment datasets for training or to normalize input test data. Accurate relighting is, however, very challenging for various reasons, such as the difficulty in removing and recasting shadows and the modeling of different surfaces. We present a novel dataset, the Virtual Image Dataset for Illumination Transfer (VIDIT), in an effort to create a reference evaluation benchmark and to push forward the development of illumination manipulation methods. Virtual datasets are not only an important step towards achieving real-image performance but have also proven capable of improving training even when real datasets are possible to acquire and available. VIDIT contains 300 virtual scenes used for training, where every scene is captured 40 times in total: from 8 equally-spaced azimuthal angles, each lit with 5 different illuminants.
Realizability of Planar Point Embeddings from Angle Measurements
May 09, 2020
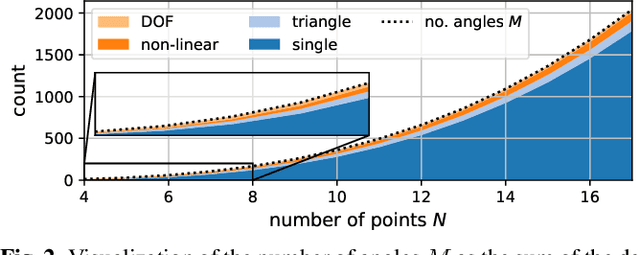
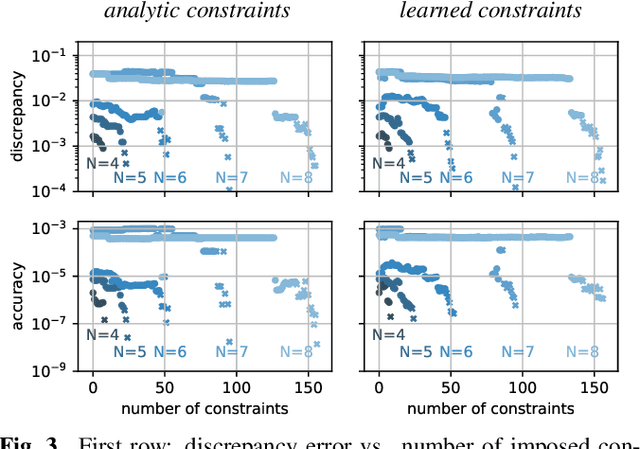
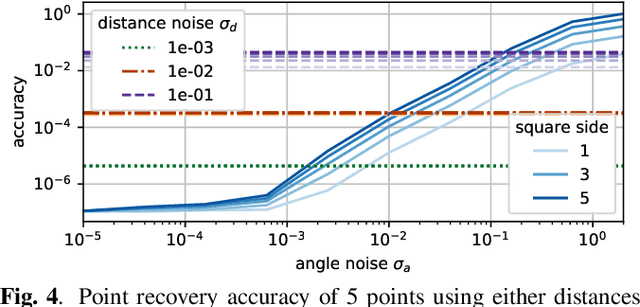
Localization of a set of nodes is an important and a thoroughly researched problem in robotics and sensor networks. This paper is concerned with the theory of localization from inner-angle measurements. We focus on the challenging case where no anchor locations are known. Inspired by Euclidean distance matrices, we investigate when a set of inner angles corresponds to a realizable point set. In particular, we find linear and non-linear constraints that are provably necessary, and we conjecture also sufficient for characterizing realizable angle sets. We confirm this in extensive numerical simulations, and we illustrate the use of these constraints for denoising angle measurements along with the reconstruction of a valid point set.
Divergence-Based Adaptive Extreme Video Completion
Apr 14, 2020

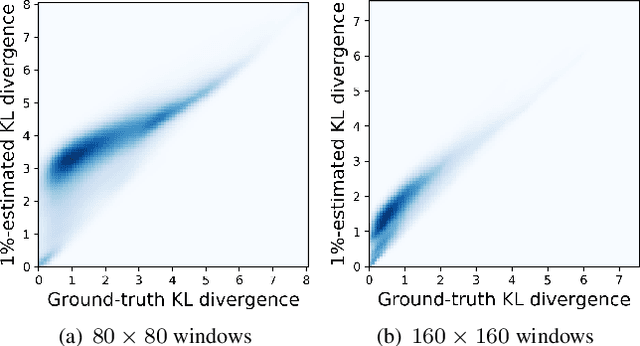
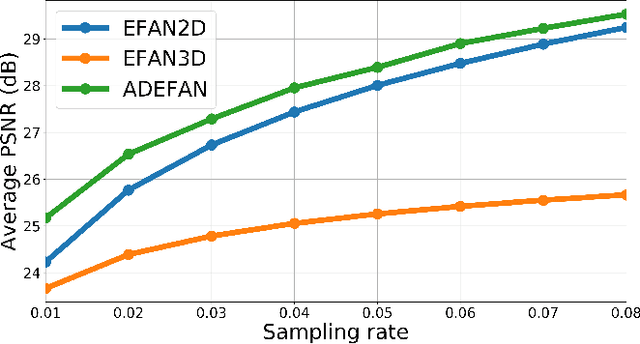
Extreme image or video completion, where, for instance, we only retain 1% of pixels in random locations, allows for very cheap sampling in terms of the required pre-processing. The consequence is, however, a reconstruction that is challenging for humans and inpainting algorithms alike. We propose an extension of a state-of-the-art extreme image completion algorithm to extreme video completion. We analyze a color-motion estimation approach based on color KL-divergence that is suitable for extremely sparse scenarios. Our algorithm leverages the estimate to adapt between its spatial and temporal filtering when reconstructing the sparse randomly-sampled video. We validate our results on 50 publicly-available videos using reconstruction PSNR and mean opinion scores.
Stochastic Frequency Masking to Improve Super-Resolution and Denoising Networks
Mar 16, 2020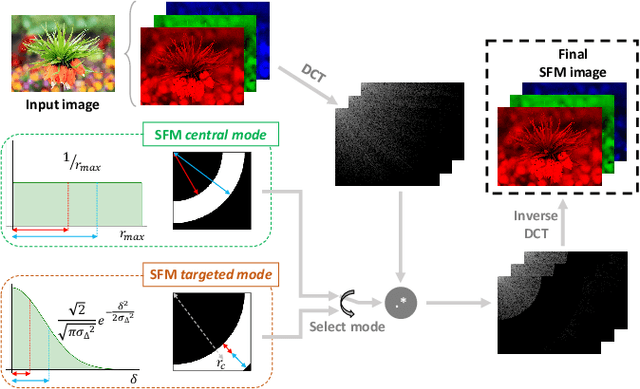

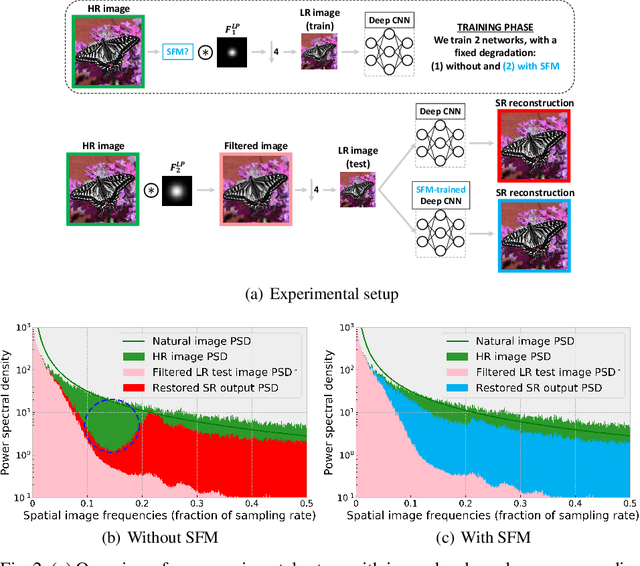
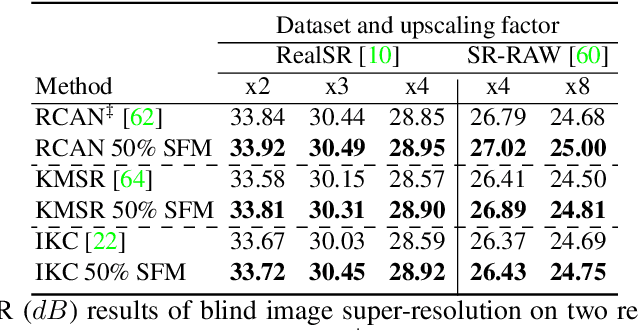
Super-resolution and denoising are ill-posed yet fundamental image restoration tasks. In blind settings, the degradation kernel or the noise level are unknown. This makes restoration even more challenging, notably for learning-based methods, as they tend to overfit to the degradation seen during training. We present an analysis, in the frequency domain, of degradation-kernel overfitting in super-resolution and introduce a conditional learning perspective that extends to both super-resolution and denoising. Building on our formulation, we propose a stochastic frequency masking of images used in training to regularize the networks and address the overfitting problem. Our technique improves state-of-the-art methods on blind super-resolution with different synthetic kernels, real super-resolution, blind Gaussian denoising, and real-image denoising.
W2S: A Joint Denoising and Super-Resolution Dataset
Mar 12, 2020



Denoising and super-resolution (SR) are fundamental tasks in imaging. These two restoration tasks are well covered in the literature, however, only separately. Given a noisy low-resolution (LR) input image, it is yet unclear what the best approach would be in order to obtain a noise-free high-resolution (HR) image. In order to study joint denoising and super-resolution (JDSR), a dataset containing pairs of noisy LR images and the corresponding HR images is fundamental. We propose such a novel JDSR dataset, Wieldfield2SIM (W2S), acquired using microscopy equipment and techniques. W2S is comprised of 144,000 real fluorescence microscopy images, used to form a total of 360 sets of images. A set is comprised of noisy LR images with different noise levels, a noise-free LR image, and a corresponding high-quality HR image. W2S allows us to benchmark the combinations of 6 denoising methods and 6 SR methods. We show that state-of-the-art SR networks perform very poorly on noisy inputs, with a loss reaching 14dB relative to noise-free inputs. Our evaluation also shows that applying the best denoiser in terms of reconstruction error followed by the best SR method does not yield the best result. The best denoising PSNR can, for instance, come at the expense of a loss in high frequencies, which is detrimental for SR methods. We lastly demonstrate that a light-weight SR network with a novel texture loss, trained specifically for JDSR, outperforms any combination of state-of-the-art deep denoising and SR networks.
AL2: Progressive Activation Loss for Learning General Representations in Classification Neural Networks
Mar 07, 2020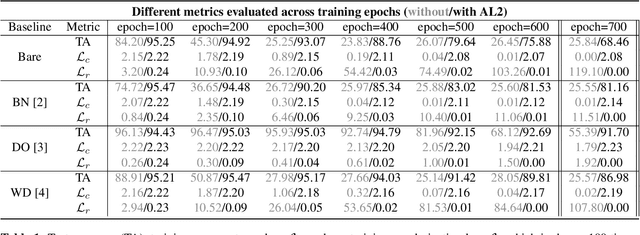
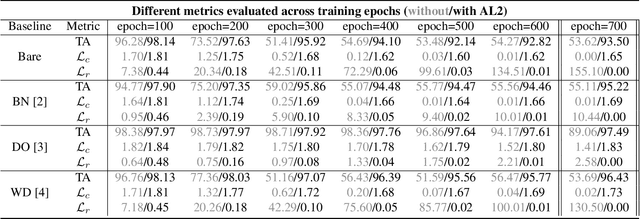
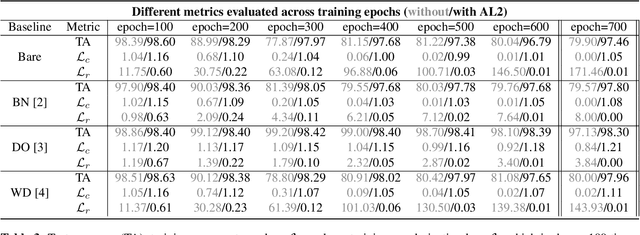
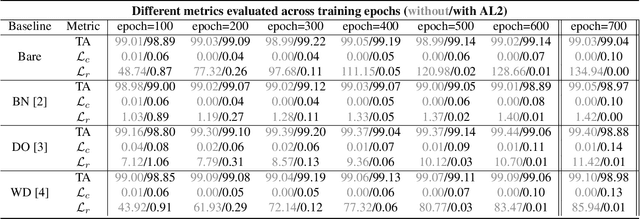
The large capacity of neural networks enables them to learn complex functions. To avoid overfitting, networks however require a lot of training data that can be expensive and time-consuming to collect. A common practical approach to attenuate overfitting is the use of network regularization techniques. We propose a novel regularization method that progressively penalizes the magnitude of activations during training. The combined activation signals produced by all neurons in a given layer form the representation of the input image in that feature space. We propose to regularize this representation in the last feature layer before classification layers. Our method's effect on generalization is analyzed with label randomization tests and cumulative ablations. Experimental results show the advantages of our approach in comparison with commonly-used regularizers on standard benchmark datasets.
Blind Universal Bayesian Image Denoising with Gaussian Noise Level Learning
Jul 05, 2019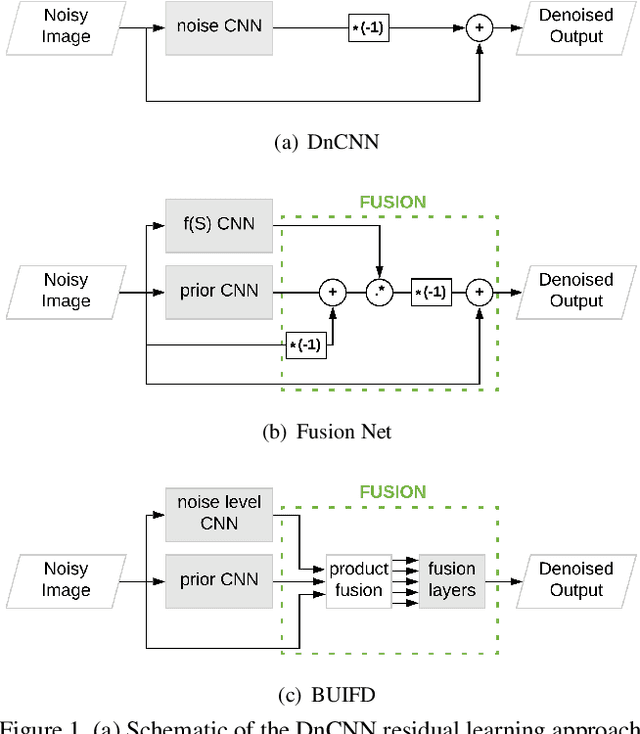

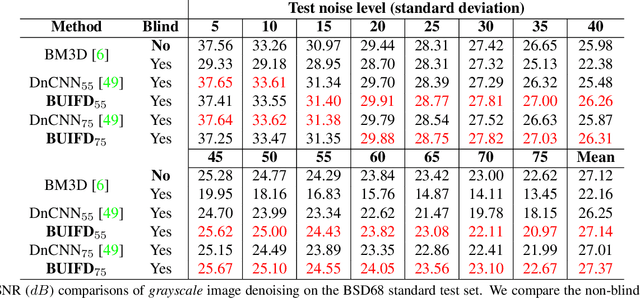

Blind and universal image denoising consists of a unique model that denoises images with any level of noise. It is especially practical as noise levels do not need to be known when the model is developed or at test time. We propose a theoretically-grounded blind and universal deep learning image denoiser for Gaussian noise. Our network is based on an optimal denoising solution, which we call fusion denoising. It is derived theoretically with a Gaussian image prior assumption. Synthetic experiments show our network's generalization strength to unseen noise levels. We also adapt the fusion denoising network architecture for real image denoising. Our approach improves real-world grayscale image denoising PSNR results by up to $0.7dB$ for training noise levels and by up to $2.82dB$ on noise levels not seen during training. It also improves state-of-the-art color image denoising performance on every single noise level, by an average of $0.1dB$, whether trained on or not.