 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatchRecall: Patch-Driven Retrieval for Automated Program Repair
Apr 12, 2026Retrieving the correct set of files from a large codebase is a crucial step in Automated Program Repair (APR). High recall is necessary to ensure that the relevant files are included, but simply increasing the number of retrieved files introduces noise and degrades efficiency. To address this tradeoff, we propose PatchRecall, a hybrid retrieval approach that balances recall with conciseness. Our method combines two complementary strategies: (1) codebase retrieval, where the current issue description is matched against the codebase to surface potentially relevant files, and (2) history-based retrieval, where similar past issues are leveraged to identify edited files as candidate targets. Candidate files from both strategies are merged and reranked to produce the final retrieval set. Experiments on SWE-Bench demonstrate that PatchRecall achieves higher recall without significantly increasing retrieved file count, enabling more effective APR.
BanglaForge: LLM Collaboration with Self-Refinement for Bangla Code Generation
Dec 22, 2025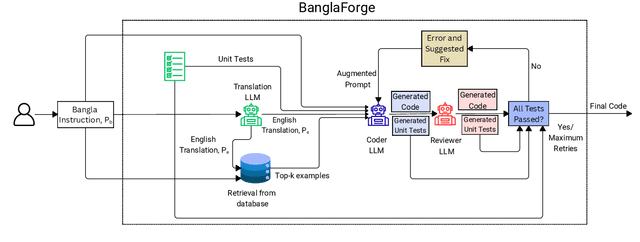
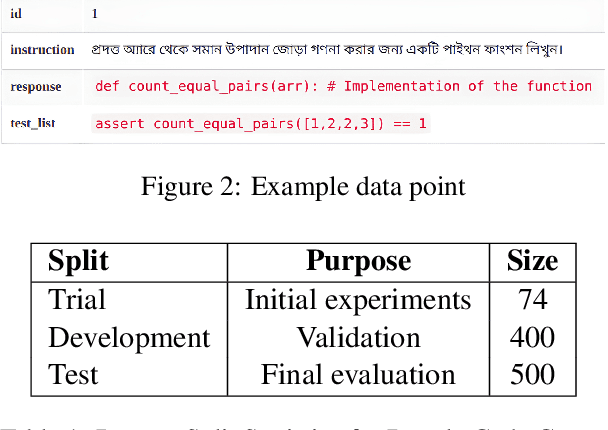
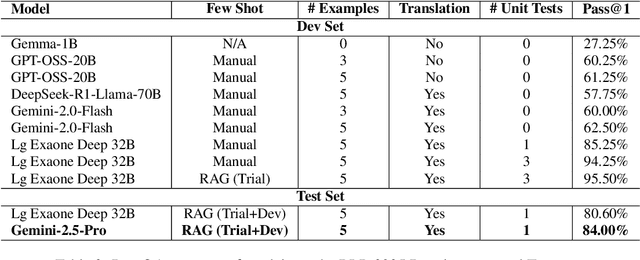

Bangla is a low-resource language for code generation, lacking large-scale annotated datasets and tools to transform natural language specifications into executable programs. This makes Bangla-to-code generation a challenging task requiring innovative solutions. To address this, we introduce BanglaForge, a novel framework for generating code from Bangla function descriptions. BanglaForge leverages a retrieval-augmented dual-model collaboration paradigm with self-refinement, combining in-context learning, llm-based translation, systematic prompt engineering, and iterative self-refinement based on execution feedback, where a coder generates initial solutions and a reviewer enhances them for robustness. On the BLP-2025 Bangla Code Generation benchmark, BanglaForge achieves a competitive Pass@1 accuracy of 84.00%, demonstrating the effectiveness of retrieval, model collaboration, and self-refinement for low-resource Bangla code generation.
WebOperator: Action-Aware Tree Search for Autonomous Agents in Web Environment
Dec 14, 2025LLM-based agents often operate in a greedy, step-by-step manner, selecting actions solely based on the current observation without considering long-term consequences or alternative paths. This lack of foresight is particularly problematic in web environments, which are only partially observable-limited to browser-visible content (e.g., DOM and UI elements)-where a single misstep often requires complex and brittle navigation to undo. Without an explicit backtracking mechanism, agents struggle to correct errors or systematically explore alternative paths. Tree-search methods provide a principled framework for such structured exploration, but existing approaches lack mechanisms for safe backtracking, making them prone to unintended side effects. They also assume that all actions are reversible, ignoring the presence of irreversible actions-limitations that reduce their effectiveness in realistic web tasks. To address these challenges, we introduce WebOperator, a tree-search framework that enables reliable backtracking and strategic exploration. Our method incorporates a best-first search strategy that ranks actions by both reward estimates and safety considerations, along with a robust backtracking mechanism that verifies the feasibility of previously visited paths before replaying them, preventing unintended side effects. To further guide exploration, WebOperator generates action candidates from multiple, varied reasoning contexts to ensure diverse and robust exploration, and subsequently curates a high-quality action set by filtering out invalid actions pre-execution and merging semantically equivalent ones. Experimental results on WebArena and WebVoyager demonstrate the effectiveness of WebOperator. On WebArena, WebOperator achieves a state-of-the-art 54.6% success rate with gpt-4o, underscoring the critical advantage of integrating strategic foresight with safe execution.
DFCon: Attention-Driven Supervised Contrastive Learning for Robust Deepfake Detection
Jan 28, 2025



This report presents our approach for the IEEE SP Cup 2025: Deepfake Face Detection in the Wild (DFWild-Cup), focusing on detecting deepfakes across diverse datasets. Our methodology employs advanced backbone models, including MaxViT, CoAtNet, and EVA-02, fine-tuned using supervised contrastive loss to enhance feature separation. These models were specifically chosen for their complementary strengths. Integration of convolution layers and strided attention in MaxViT is well-suited for detecting local features. In contrast, hybrid use of convolution and attention mechanisms in CoAtNet effectively captures multi-scale features. Robust pretraining with masked image modeling of EVA-02 excels at capturing global features. After training, we freeze the parameters of these models and train the classification heads. Finally, a majority voting ensemble is employed to combine the predictions from these models, improving robustness and generalization to unseen scenarios. The proposed system addresses the challenges of detecting deepfakes in real-world conditions and achieves a commendable accuracy of 95.83% on the validation dataset.
MapEval: A Map-Based Evaluation of Geo-Spatial Reasoning in Foundation Models
Dec 31, 2024



Recent advancements in foundation models have enhanced AI systems' capabilities in autonomous tool usage and reasoning. However, their ability in location or map-based reasoning - which improves daily life by optimizing navigation, facilitating resource discovery, and streamlining logistics - has not been systematically studied. To bridge this gap, we introduce MapEval, a benchmark designed to assess diverse and complex map-based user queries with geo-spatial reasoning. MapEval features three task types (textual, API-based, and visual) that require collecting world information via map tools, processing heterogeneous geo-spatial contexts (e.g., named entities, travel distances, user reviews or ratings, images), and compositional reasoning, which all state-of-the-art foundation models find challenging. Comprising 700 unique multiple-choice questions about locations across 180 cities and 54 countries, MapEval evaluates foundation models' ability to handle spatial relationships, map infographics, travel planning, and navigation challenges. Using MapEval, we conducted a comprehensive evaluation of 28 prominent foundation models. While no single model excelled across all tasks, Claude-3.5-Sonnet, GPT-4o, and Gemini-1.5-Pro achieved competitive performance overall. However, substantial performance gaps emerged, particularly in MapEval, where agents with Claude-3.5-Sonnet outperformed GPT-4o and Gemini-1.5-Pro by 16% and 21%, respectively, and the gaps became even more amplified when compared to open-source LLMs. Our detailed analyses provide insights into the strengths and weaknesses of current models, though all models still fall short of human performance by more than 20% on average, struggling with complex map images and rigorous geo-spatial reasoning. This gap highlights MapEval's critical role in advancing general-purpose foundation models with stronger geo-spatial understanding.
MapQaTor: A System for Efficient Annotation of Map Query Datasets
Dec 30, 2024Mapping and navigation services like Google Maps, Apple Maps, Openstreet Maps, are essential for accessing various location-based data, yet they often struggle to handle natural language geospatial queries. Recent advancements in Large Language Models (LLMs) show promise in question answering (QA), but creating reliable geospatial QA datasets from map services remains challenging. We introduce MapQaTor, a web application that streamlines the creation of reproducible, traceable map-based QA datasets. With its plug-and-play architecture, MapQaTor enables seamless integration with any maps API, allowing users to gather and visualize data from diverse sources with minimal setup. By caching API responses, the platform ensures consistent ground truth, enhancing the reliability of the data even as real-world information evolves. MapQaTor centralizes data retrieval, annotation, and visualization within a single platform, offering a unique opportunity to evaluate the current state of LLM-based geospatial reasoning while advancing their capabilities for improved geospatial understanding. Evaluation metrics show that, MapQaTor speeds up the annotation process by at least 30 times compared to manual methods, underscoring its potential for developing geospatial resources, such as complex map reasoning datasets. The website is live at: https://mapqator.github.io/ and a demo video is available at: https://youtu.be/7_aV9Wmhs6Q.