 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrecting Selection Bias in Sparse User Feedback for Large Language Model Quality Estimation: A Multi-Agent Hierarchical Bayesian Approach
May 12, 2026[Abridged] Production LLM deployments receive feedback from a non-random fraction of users: thumbs sit mostly in the tails of the satisfaction distribution, and a naive average over them can land 40-50 percentage points away from true system quality. We treat this as a topic- and sentiment- stratified selection-bias problem and propose a three-agent hierarchical Bayesian pipeline that does not require ground-truth labels on individual interactions. A Topic Clustering Agent partitions the stream via UMAP + HDBSCAN over text embeddings; a Bias Modeling Agent fits a two-stage hierarchical Beta-Binomial under NUTS, inferring per-topic selection rates $s_c$ and quality $q_c$ with partial pooling; a Synthesis Agent reweights $q_c$ by true topic prevalence $\hatπ_c = n_c/N$ to report a bias-corrected aggregate posterior $\bar Q = \sum_c \hatπ_c q_c$ with credible interval, plus drift signals for online recalibration. Validation uses UltraFeedback (N=10,232 retained interactions, $C=18$ clusters, $Q^\star=0.6249$) with simulated topic- and sentiment-dependent selection biases. We compare five Bayesian variants against Naive and IPW baselines. A mild prior on the feedback channel (typical positive-feedback rate and negative-to-positive ratio, both readable from any production dashboard without labels) keeps Hierarchical-Informed within 4-13 pp of $Q^\star$ as the bias ratio sweeps from 1:1 to 30:1, with 95% credible intervals covering $Q^\star$ in 50/50 random-seed replicates at $κ_{\max}=10$. Without channel-side priors, every weak-prior variant misses $Q^\star$ by 22-33 pp: the per-cluster sufficient statistics admit a one-parameter family of equally good fits, and the prior on the bias channel (not on latent quality) is what breaks the degeneracy.
From Intent to Execution: Composing Agentic Workflows with Agent Recommendation
May 05, 2026Multi-Agent Systems (MAS) built using AI agents fulfill a variety of user intents that may be used to design and build a family of related applications. However, the creation of such MAS currently involves manual composition of the plan, manual selection of appropriate agents, and manual creation of execution graphs. This paper introduces a framework for the automated creation of multi-agent systems which replaces multiple manual steps with an automated framework. The proposed framework consists of software modules and a workflow to orchestrate the requisite task- specific application. The modules include: an LLM-derived planner, a set of tasks described in natural language, a dynamic call graph, an orchestrator for map agents to tasks, and an agent recommender that finds the most suitable agent(s) from local and global agent registries. The agent recommender uses a two-stage information retrieval (IR) system comprising a fast retriever and an LLM-based re-ranker. We implemented a series of experiments exploring the choice of embedders, re- rankers, agent description enrichment, and supervising critique agent. We benchmarked this system end-to-end, evaluating the combination of planning, agent selection, and task completion, with our proposed approach. Our experimental results show that our approach outperforms the state-of-the- art in terms of the recall rate and is more robust and scalable compared to previous approaches. The critique agent holistically reevaluates both agent and tool recommendations against the overall plan. We show that the inclusion of the critique agent further enhances the recall score, proving that the comprehensive review and revision of task-based agent selection is an essential step in building end-to-end multi-agent systems.
Searching for Optimal Runtime Assurance via Reachability and Reinforcement Learning
Oct 06, 2023A runtime assurance system (RTA) for a given plant enables the exercise of an untrusted or experimental controller while assuring safety with a backup (or safety) controller. The relevant computational design problem is to create a logic that assures safety by switching to the safety controller as needed, while maximizing some performance criteria, such as the utilization of the untrusted controller. Existing RTA design strategies are well-known to be overly conservative and, in principle, can lead to safety violations. In this paper, we formulate the optimal RTA design problem and present a new approach for solving it. Our approach relies on reward shaping and reinforcement learning. It can guarantee safety and leverage machine learning technologies for scalability. We have implemented this algorithm and present experimental results comparing our approach with state-of-the-art reachability and simulation-based RTA approaches in a number of scenarios using aircraft models in 3D space with complex safety requirements. Our approach can guarantee safety while increasing utilization of the experimental controller over existing approaches.
Statistically Model Checking PCTL Specifications on Markov Decision Processes via Reinforcement Learning
Apr 22, 2020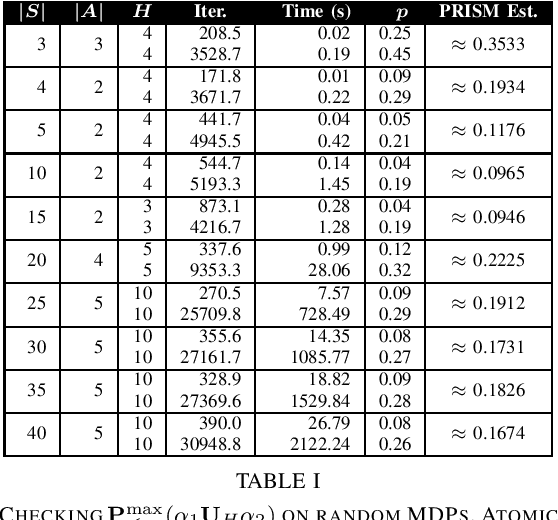
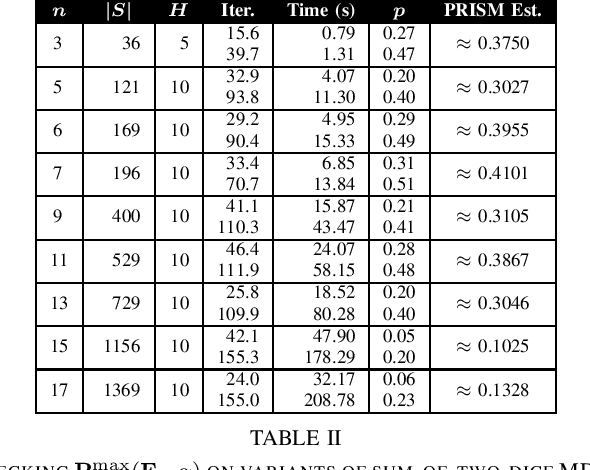
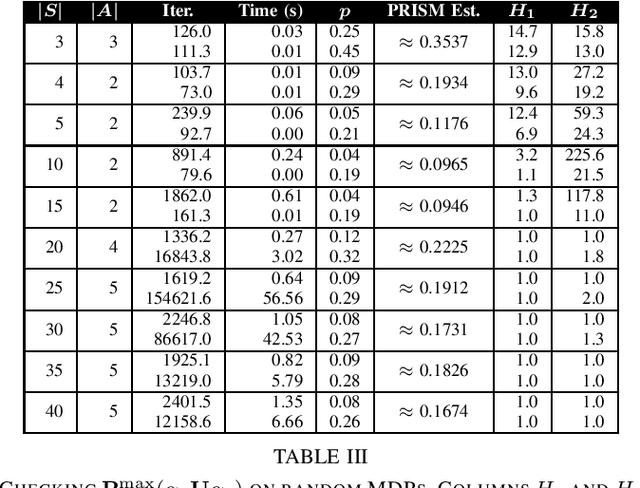
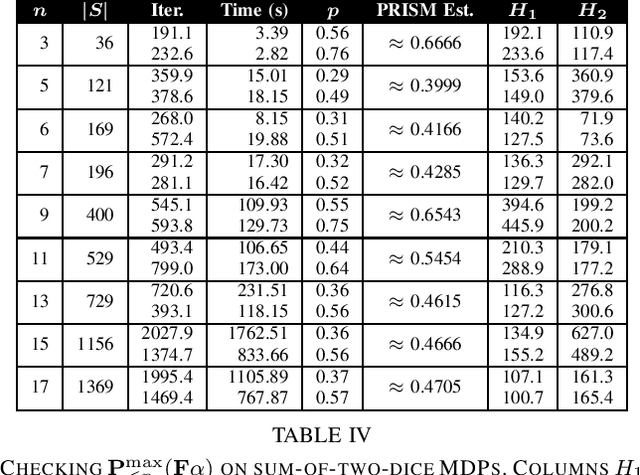
Probabilistic Computation Tree Logic (PCTL) is frequently used to formally specify control objectives such as probabilistic reachability and safety. In this work, we focus on model checking PCTL specifications statistically on Markov Decision Processes (MDPs) by sampling, e.g., checking whether there exists a feasible policy such that the probability of reaching certain goal states is greater than a threshold. We use reinforcement learning to search for such a feasible policy for PCTL specifications, and then develop a statistical model checking (SMC) method with provable guarantees on its error. Specifically, we first use upper-confidence-bound (UCB) based Q-learning to design an SMC algorithm for bounded-time PCTL specifications, and then extend this algorithm to unbounded-time specifications by identifying a proper truncation time by checking the PCTL specification and its negation at the same time. Finally, we evaluate the proposed method on case studies.