 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVIN: Learning Multiview Items for Recommendation
May 26, 2020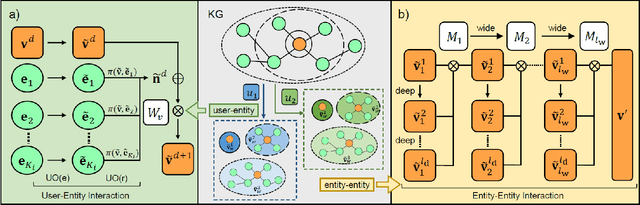
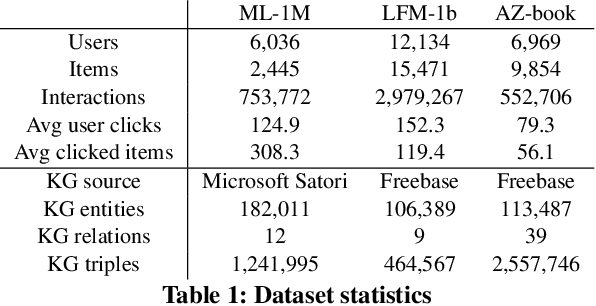
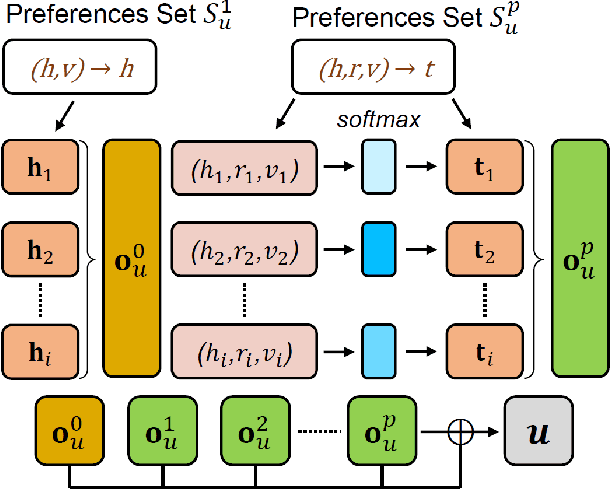
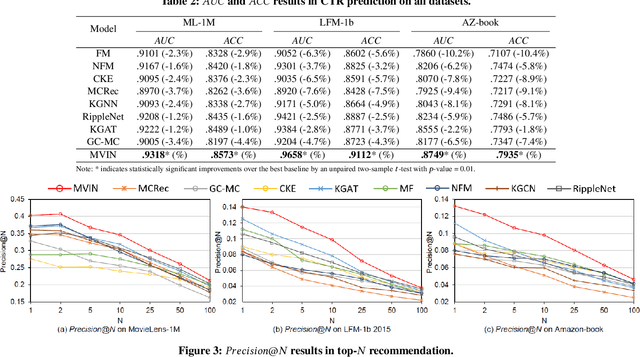
Researchers have begun to utilize heterogeneous knowledge graphs (KGs) as auxiliary information in recommendation systems to mitigate the cold start and sparsity issues. However, utilizing a graph neural network (GNN) to capture information in KG and further apply in RS is still problematic as it is unable to see each item's properties from multiple perspectives. To address these issues, we propose the multi-view item network (MVIN), a GNN-based recommendation model which provides superior recommendations by describing items from a unique mixed view from user and entity angles. MVIN learns item representations from both the user view and the entity view. From the user view, user-oriented modules score and aggregate features to make recommendations from a personalized perspective constructed according to KG entities which incorporates user click information. From the entity view, the mixing layer contrasts layer-wise GCN information to further obtain comprehensive features from internal entity-entity interactions in the KG. We evaluate MVIN on three real-world datasets: MovieLens-1M (ML-1M), LFM-1b 2015 (LFM-1b), and Amazon-Book (AZ-book). Results show that MVIN significantly outperforms state-of-the-art methods on these three datasets. In addition, from user-view cases, we find that MVIN indeed captures entities that attract users. Figures further illustrate that mixing layers in a heterogeneous KG plays a vital role in neighborhood information aggregation.
Attractive or Faithful? Popularity-Reinforced Learning for Inspired Headline Generation
Feb 06, 2020
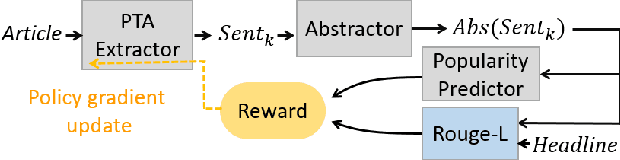
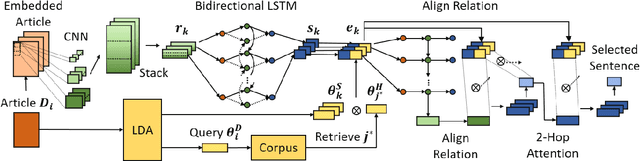

With the rapid proliferation of online media sources and published news, headlines have become increasingly important for attracting readers to news articles, since users may be overwhelmed with the massive information. In this paper, we generate inspired headlines that preserve the nature of news articles and catch the eye of the reader simultaneously. The task of inspired headline generation can be viewed as a specific form of Headline Generation (HG) task, with the emphasis on creating an attractive headline from a given news article. To generate inspired headlines, we propose a novel framework called POpularity-Reinforced Learning for inspired Headline Generation (PORL-HG). PORL-HG exploits the extractive-abstractive architecture with 1) Popular Topic Attention (PTA) for guiding the extractor to select the attractive sentence from the article and 2) a popularity predictor for guiding the abstractor to rewrite the attractive sentence. Moreover, since the sentence selection of the extractor is not differentiable, techniques of reinforcement learning (RL) are utilized to bridge the gap with rewards obtained from a popularity score predictor. Through quantitative and qualitative experiments, we show that the proposed PORL-HG significantly outperforms the state-of-the-art headline generation models in terms of attractiveness evaluated by both human (71.03%) and the predictor (at least 27.60%), while the faithfulness of PORL-HG is also comparable to the state-of-the-art generation model.
Multi-step Joint-Modality Attention Network for Scene-Aware Dialogue System
Jan 17, 2020
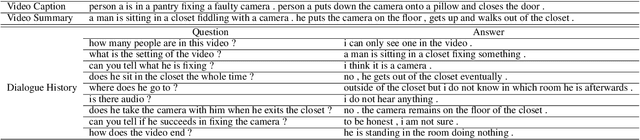

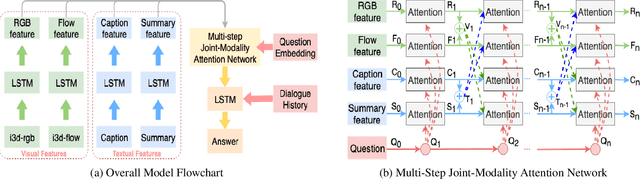
Understanding dynamic scenes and dialogue contexts in order to converse with users has been challenging for multimodal dialogue systems. The 8-th Dialog System Technology Challenge (DSTC8) proposed an Audio Visual Scene-Aware Dialog (AVSD) task, which contains multiple modalities including audio, vision, and language, to evaluate how dialogue systems understand different modalities and response to users. In this paper, we proposed a multi-step joint-modality attention network (JMAN) based on recurrent neural network (RNN) to reason on videos. Our model performs a multi-step attention mechanism and jointly considers both visual and textual representations in each reasoning process to better integrate information from the two different modalities. Compared to the baseline released by AVSD organizers, our model achieves a relative 12.1% and 22.4% improvement over the baseline on ROUGE-L score and CIDEr score.
Knowledge-Enriched Visual Storytelling
Dec 03, 2019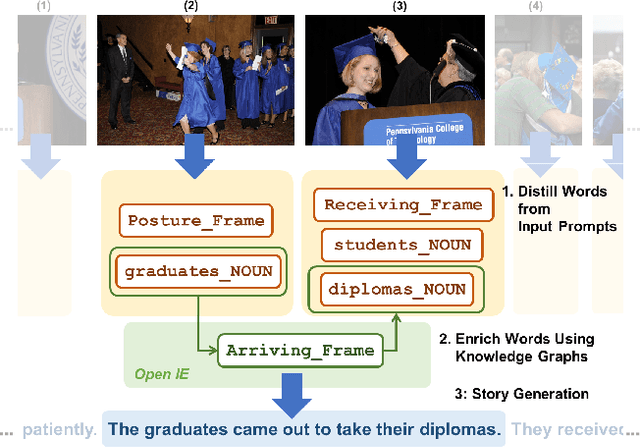

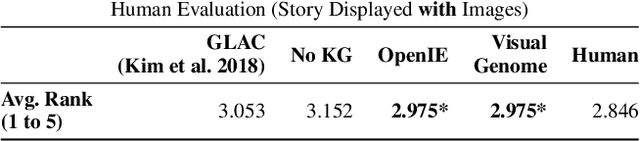
Stories are diverse and highly personalized, resulting in a large possible output space for story generation. Existing end-to-end approaches produce monotonous stories because they are limited to the vocabulary and knowledge in a single training dataset. This paper introduces KG-Story, a three-stage framework that allows the story generation model to take advantage of external Knowledge Graphs to produce interesting stories. KG-Story distills a set of representative words from the input prompts, enriches the word set by using external knowledge graphs, and finally generates stories based on the enriched word set. This distill-enrich-generate framework allows the use of external resources not only for the enrichment phase, but also for the distillation and generation phases. In this paper, we show the superiority of KG-Story for visual storytelling, where the input prompt is a sequence of five photos and the output is a short story. Per the human ranking evaluation, stories generated by KG-Story are on average ranked better than that of the state-of-the-art systems. Our code and output stories are available at https://github.com/zychen423/KE-VIST.
SocialNLP EmotionX 2019 Challenge Overview: Predicting Emotions in Spoken Dialogues and Chats
Sep 18, 2019
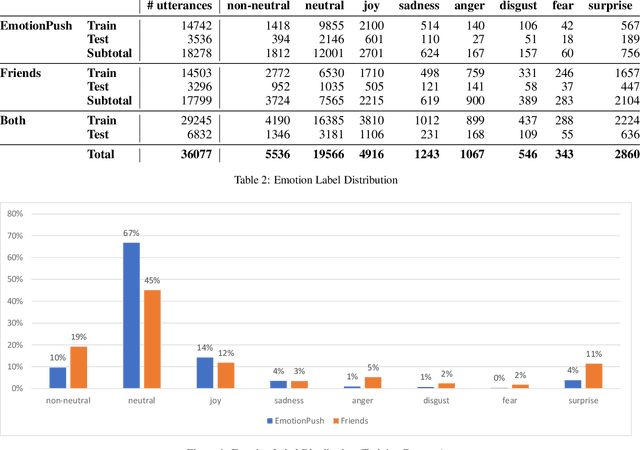
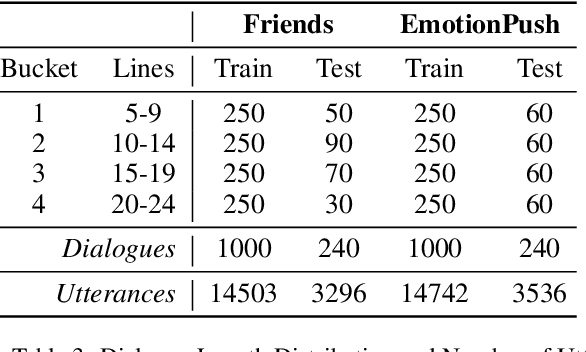

We present an overview of the EmotionX 2019 Challenge, held at the 7th International Workshop on Natural Language Processing for Social Media (SocialNLP), in conjunction with IJCAI 2019. The challenge entailed predicting emotions in spoken and chat-based dialogues using augmented EmotionLines datasets. EmotionLines contains two distinct datasets: the first includes excerpts from a US-based TV sitcom episode scripts (Friends) and the second contains online chats (EmotionPush). A total of thirty-six teams registered to participate in the challenge. Eleven of the teams successfully submitted their predictions performance evaluation. The top-scoring team achieved a micro-F1 score of 81.5% for the spoken-based dialogues (Friends) and 79.5% for the chat-based dialogues (EmotionPush).
Entropy-Enhanced Multimodal Attention Model for Scene-Aware Dialogue Generation
Aug 22, 2019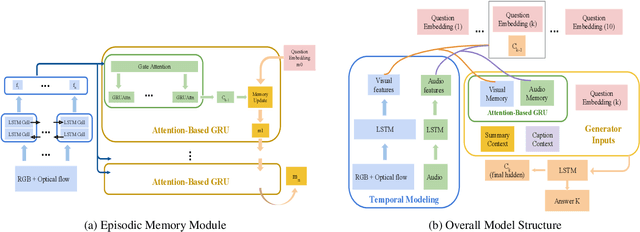
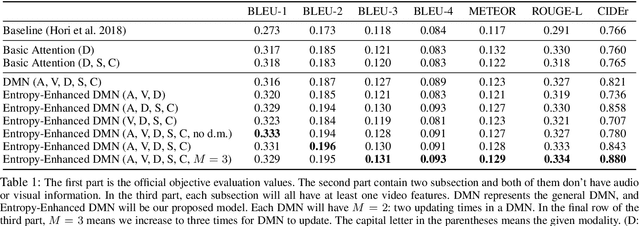

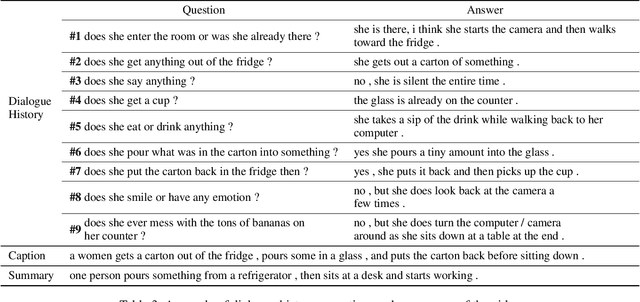
With increasing information from social media, there are more and more videos available. Therefore, the ability to reason on a video is important and deserves to be discussed. TheDialog System Technology Challenge (DSTC7) (Yoshino et al. 2018) proposed an Audio Visual Scene-aware Dialog (AVSD) task, which contains five modalities including video, dialogue history, summary, and caption, as a scene-aware environment. In this paper, we propose the entropy-enhanced dynamic memory network (DMN) to effectively model video modality. The attention-based GRU in the proposed model can improve the model's ability to comprehend and memorize sequential information. The entropy mechanism can control the attention distribution higher, so each to-be-answered question can focus more specifically on a small set of video segments. After the entropy-enhanced DMN secures the video context, we apply an attention model that in-corporates summary and caption to generate an accurate answer given the question about the video. In the official evaluation, our system can achieve improved performance against the released baseline model for both subjective and objective evaluation metrics.
From Receptive to Productive: Learning to Use Confusing Words through Automatically Selected Example Sentences
Jun 06, 2019



Knowing how to use words appropriately has been a key to improving language proficiency. Previous studies typically discuss how students learn receptively to select the correct candidate from a set of confusing words in the fill-in-the-blank task where specific context is given. In this paper, we go one step further, assisting students to learn to use confusing words appropriately in a productive task: sentence translation. We leverage the GiveMeExample system, which suggests example sentences for each confusing word, to achieve this goal. In this study, students learn to differentiate the confusing words by reading the example sentences, and then choose the appropriate word(s) to complete the sentence translation task. Results show students made substantial progress in terms of sentence structure. In addition, highly proficient students better managed to learn confusing words. In view of the influence of the first language on learners, we further propose an effective approach to improve the quality of the suggested sentences.
UHop: An Unrestricted-Hop Relation Extraction Framework for Knowledge-Based Question Answering
Apr 02, 2019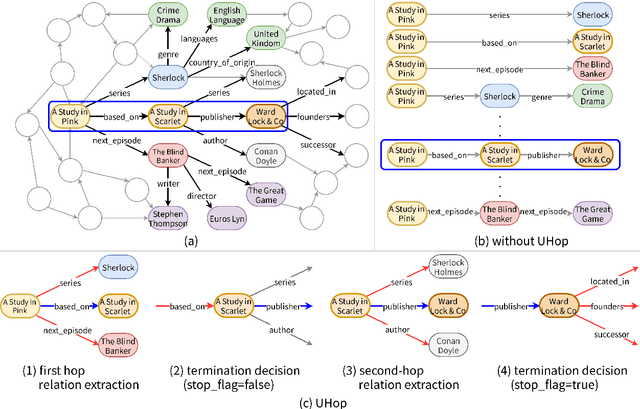
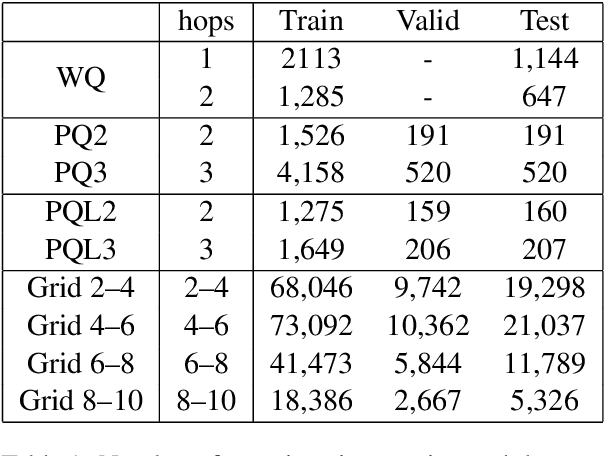
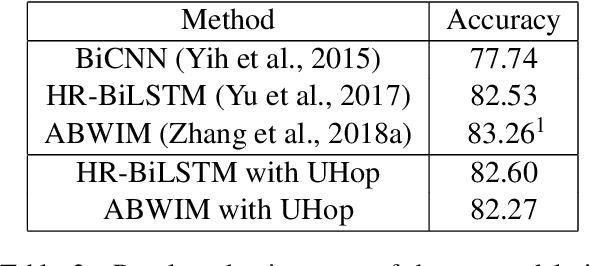
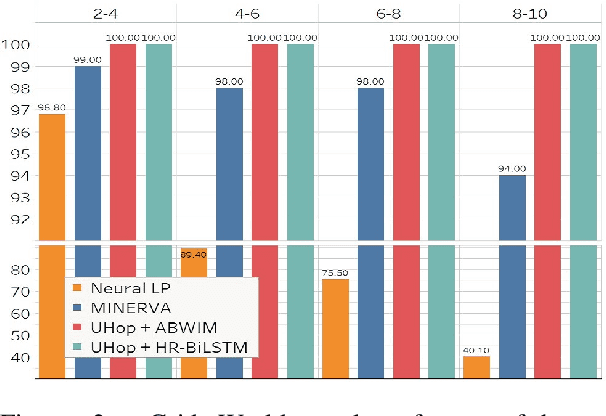
In relation extraction for knowledge-based question answering, searching from one entity to another entity via a single relation is called "one hop". In related work, an exhaustive search from all one-hop relations, two-hop relations, and so on to the max-hop relations in the knowledge graph is necessary but expensive. Therefore, the number of hops is generally restricted to two or three. In this paper, we propose UHop, an unrestricted-hop framework which relaxes this restriction by use of a transition-based search framework to replace the relation-chain-based search one. We conduct experiments on conventional 1- and 2-hop questions as well as lengthy questions, including datasets such as WebQSP, PathQuestion, and Grid World. Results show that the proposed framework enables the ability to halt, works well with state-of-the-art models, achieves competitive performance without exhaustive searches, and opens the performance gap for long relation paths.
Dixit: Interactive Visual Storytelling via Term Manipulation
Mar 11, 2019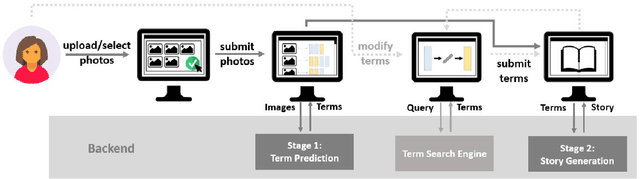

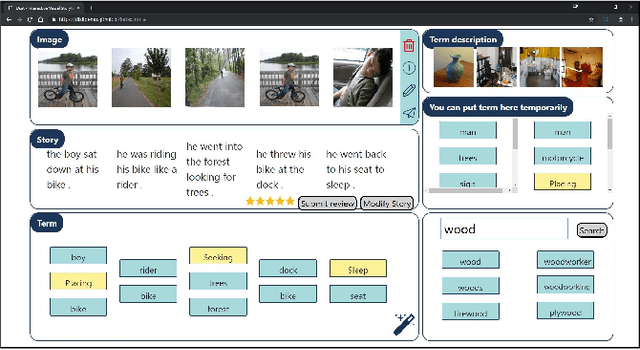
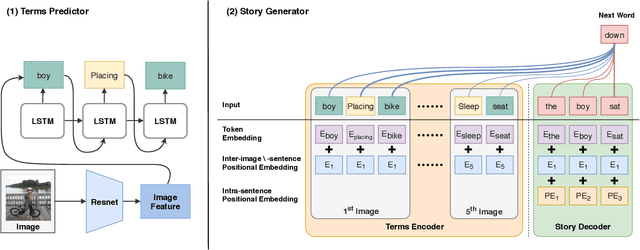
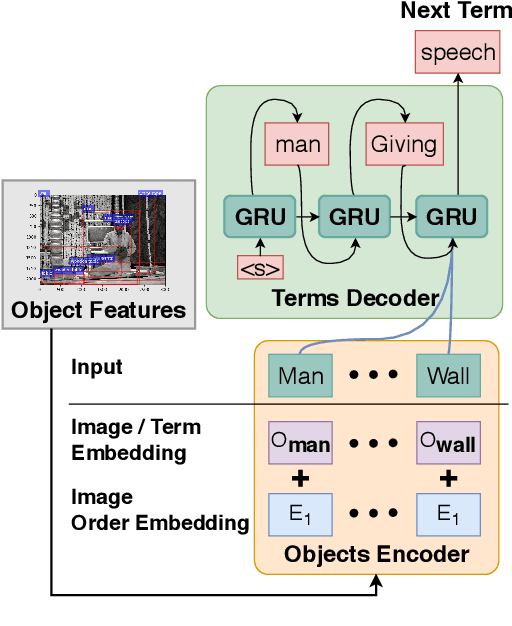
In this paper, we introduce Dixit, an interactive visual storytelling system that the user interacts with iteratively to compose a short story for a photo sequence. The user initiates the process by uploading a sequence of photos. Dixit first extracts text terms from each photo which describe the objects (e.g., boy, bike) or actions (e.g., sleep) in the photo, and then allows the user to add new terms or remove existing terms. Dixit then generates a short story based on these terms. Behind the scenes, Dixit uses an LSTM-based model trained on image caption data and FrameNet to distill terms from each image and utilizes a transformer decoder to compose a context-coherent story. Users change images or terms iteratively with Dixit to create the most ideal story. Dixit also allows users to manually edit and rate stories. The proposed procedure opens up possibilities for interpretable and controllable visual storytelling, allowing users to understand the story formation rationale and to intervene in the generation process.
EmotionLines: An Emotion Corpus of Multi-Party Conversations
May 30, 2018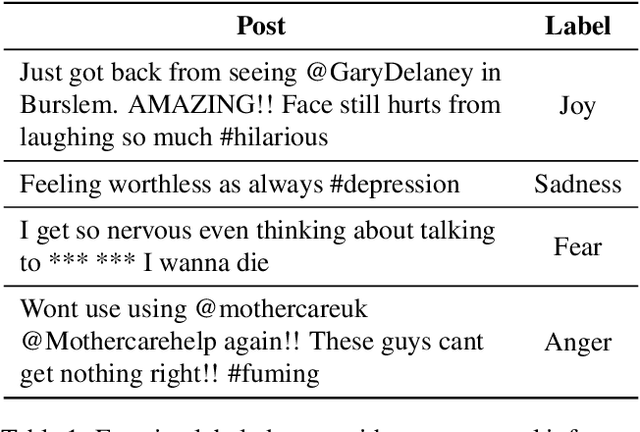
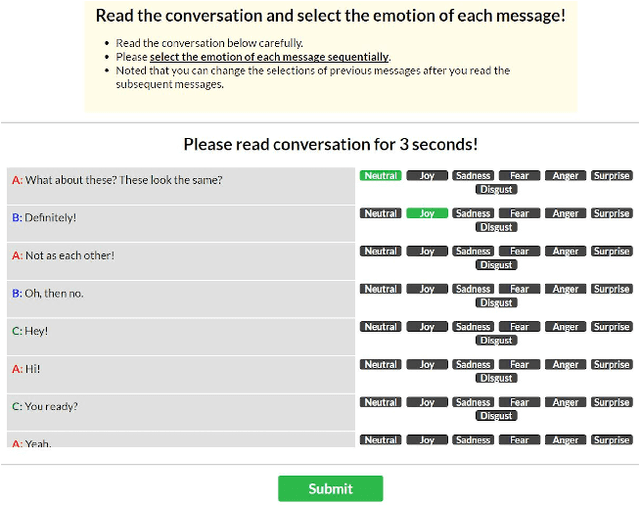


Feeling emotion is a critical characteristic to distinguish people from machines. Among all the multi-modal resources for emotion detection, textual datasets are those containing the least additional information in addition to semantics, and hence are adopted widely for testing the developed systems. However, most of the textual emotional datasets consist of emotion labels of only individual words, sentences or documents, which makes it challenging to discuss the contextual flow of emotions. In this paper, we introduce EmotionLines, the first dataset with emotions labeling on all utterances in each dialogue only based on their textual content. Dialogues in EmotionLines are collected from Friends TV scripts and private Facebook messenger dialogues. Then one of seven emotions, six Ekman's basic emotions plus the neutral emotion, is labeled on each utterance by 5 Amazon MTurkers. A total of 29,245 utterances from 2,000 dialogues are labeled in EmotionLines. We also provide several strong baselines for emotion detection models on EmotionLines in this paper.