 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHappy Dance, Slow Clap: Using Reaction GIFs to Predict Induced Affect on Twitter
May 20, 2021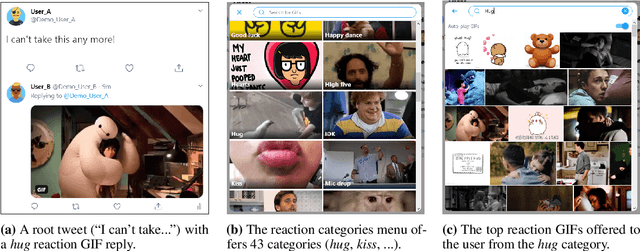
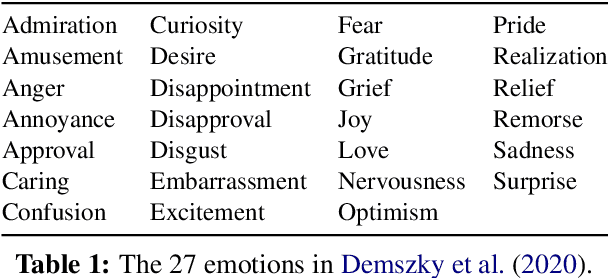
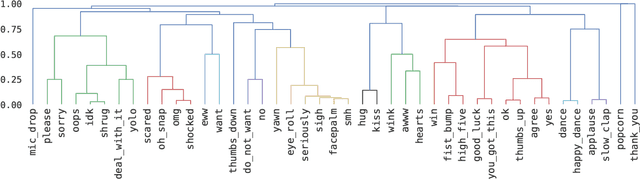
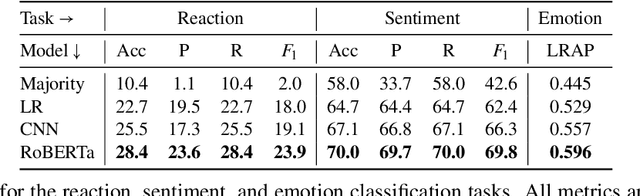
Datasets with induced emotion labels are scarce but of utmost importance for many NLP tasks. We present a new, automated method for collecting texts along with their induced reaction labels. The method exploits the online use of reaction GIFs, which capture complex affective states. We show how to augment the data with induced emotion and induced sentiment labels. We use our method to create and publish ReactionGIF, a first-of-its-kind affective dataset of 30K tweets. We provide baselines for three new tasks, including induced sentiment prediction and multilabel classification of induced emotions. Our method and dataset open new research opportunities in emotion detection and affective computing.
Beyond Fair Pay: Ethical Implications of NLP Crowdsourcing
Apr 20, 2021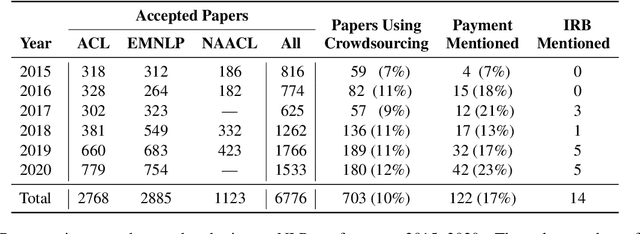


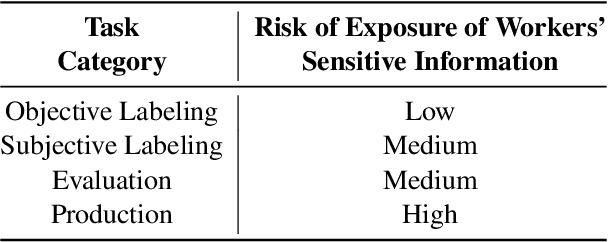
The use of crowdworkers in NLP research is growing rapidly, in tandem with the exponential increase in research production in machine learning and AI. Ethical discussion regarding the use of crowdworkers within the NLP research community is typically confined in scope to issues related to labor conditions such as fair pay. We draw attention to the lack of ethical considerations related to the various tasks performed by workers, including labeling, evaluation, and production. We find that the Final Rule, the common ethical framework used by researchers, did not anticipate the use of online crowdsourcing platforms for data collection, resulting in gaps between the spirit and practice of human-subjects ethics in NLP research. We enumerate common scenarios where crowdworkers performing NLP tasks are at risk of harm. We thus recommend that researchers evaluate these risks by considering the three ethical principles set up by the Belmont Report. We also clarify some common misconceptions regarding the Institutional Review Board (IRB) application. We hope this paper will serve to reopen the discussion within our community regarding the ethical use of crowdworkers.
SocialNLP EmotionGIF 2020 Challenge Overview: Predicting Reaction GIF Categories on Social Media
Feb 24, 2021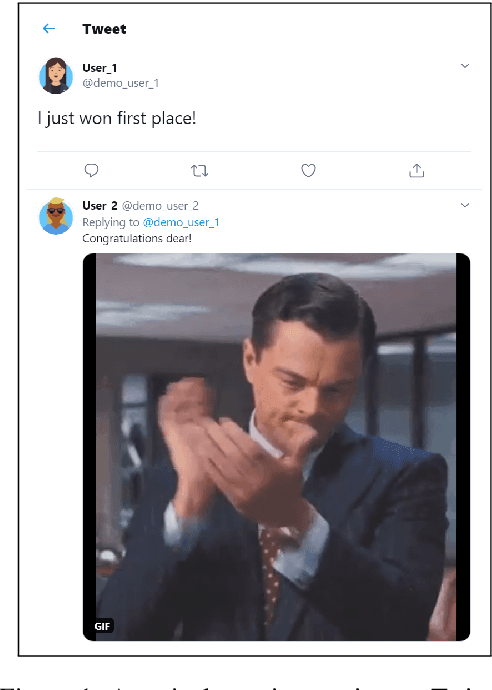



We present an overview of the EmotionGIF2020 Challenge, held at the 8th International Workshop on Natural Language Processing for Social Media (SocialNLP), in conjunction with ACL 2020. The challenge required predicting affective reactions to online texts, and included the EmotionGIF dataset, with tweets labeled for the reaction categories. The novel dataset included 40K tweets with their reaction GIFs. Due to the special circumstances of year 2020, two rounds of the competition were conducted. A total of 84 teams registered for the task. Of these, 25 teams success-fully submitted entries to the evaluation phase in the first round, while 13 teams participated successfully in the second round. Of the top participants, five teams presented a technical report and shared their code. The top score of the winning team using the Recall@K metric was 62.47%.
Reactive Supervision: A New Method for Collecting Sarcasm Data
Sep 28, 2020
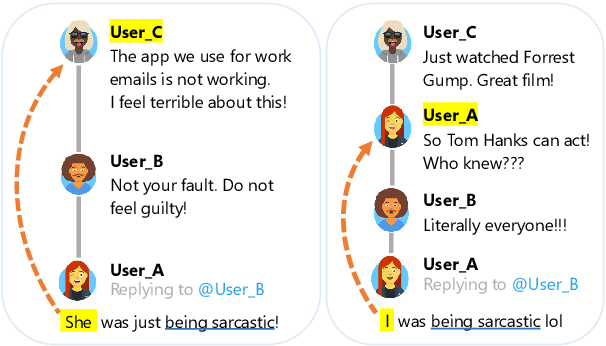
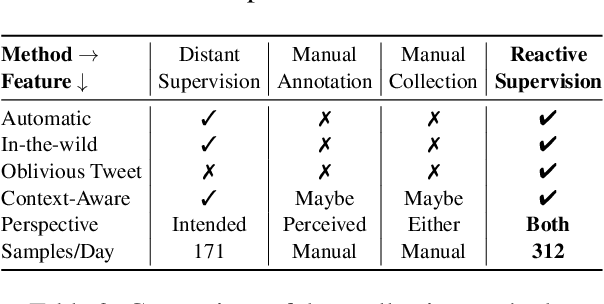
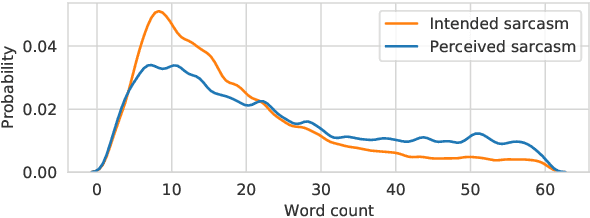
Sarcasm detection is an important task in affective computing, requiring large amounts of labeled data. We introduce reactive supervision, a novel data collection method that utilizes the dynamics of online conversations to overcome the limitations of existing data collection techniques. We use the new method to create and release a first-of-its-kind large dataset of tweets with sarcasm perspective labels and new contextual features. The dataset is expected to advance sarcasm detection research. Our method can be adapted to other affective computing domains, thus opening up new research opportunities.
Tutorial on NLP-Inspired Network Embedding
Oct 16, 2019
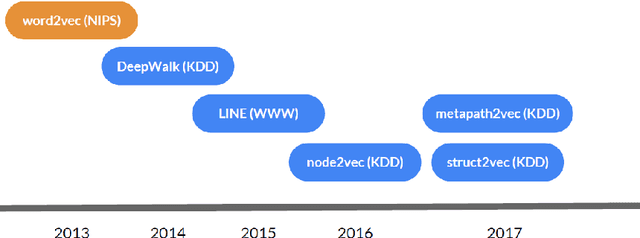
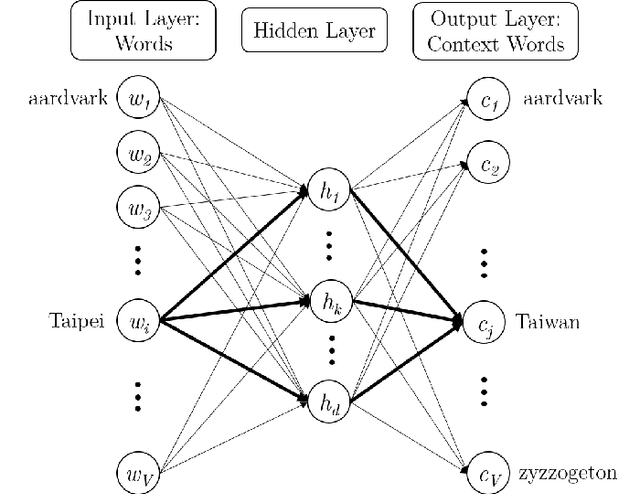
This tutorial covers a few recent papers in the field of network embedding. Network embedding is a collective term for techniques for mapping graph nodes to vectors of real numbers in a multidimensional space. To be useful, a good embedding should preserve the structure of the graph. The vectors can then be used as input to various network and graph analysis tasks, such as link prediction. The papers discussed develop methods for the online learning of such embeddings, and include DeepWalk, LINE, node2vec, struc2vec and megapath2vec. These new methods and developments in online learning of network embeddings have major applications for the analysis of graphs and networks, including online social networks.
SocialNLP EmotionX 2019 Challenge Overview: Predicting Emotions in Spoken Dialogues and Chats
Sep 18, 2019
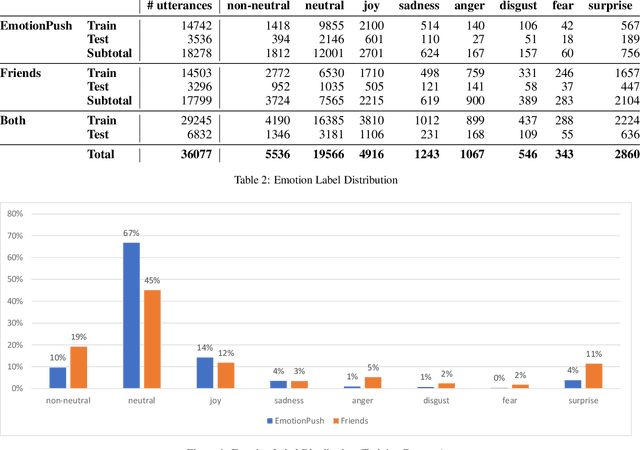
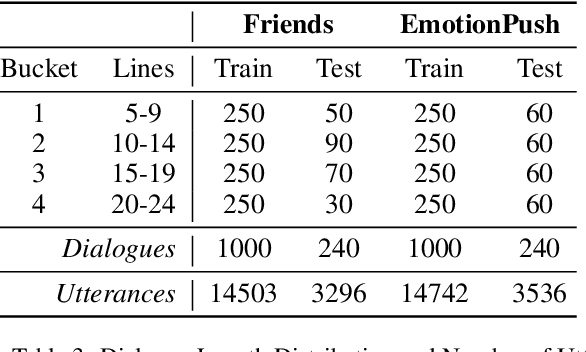

We present an overview of the EmotionX 2019 Challenge, held at the 7th International Workshop on Natural Language Processing for Social Media (SocialNLP), in conjunction with IJCAI 2019. The challenge entailed predicting emotions in spoken and chat-based dialogues using augmented EmotionLines datasets. EmotionLines contains two distinct datasets: the first includes excerpts from a US-based TV sitcom episode scripts (Friends) and the second contains online chats (EmotionPush). A total of thirty-six teams registered to participate in the challenge. Eleven of the teams successfully submitted their predictions performance evaluation. The top-scoring team achieved a micro-F1 score of 81.5% for the spoken-based dialogues (Friends) and 79.5% for the chat-based dialogues (EmotionPush).