 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRL-based Stateful Neural Adaptive Sampling and Denoising for Real-Time Path Tracing
Oct 05, 2023



Monte-Carlo path tracing is a powerful technique for realistic image synthesis but suffers from high levels of noise at low sample counts, limiting its use in real-time applications. To address this, we propose a framework with end-to-end training of a sampling importance network, a latent space encoder network, and a denoiser network. Our approach uses reinforcement learning to optimize the sampling importance network, thus avoiding explicit numerically approximated gradients. Our method does not aggregate the sampled values per pixel by averaging but keeps all sampled values which are then fed into the latent space encoder. The encoder replaces handcrafted spatiotemporal heuristics by learned representations in a latent space. Finally, a neural denoiser is trained to refine the output image. Our approach increases visual quality on several challenging datasets and reduces rendering times for equal quality by a factor of 1.6x compared to the previous state-of-the-art, making it a promising solution for real-time applications.
Going Further With Winograd Convolutions: Tap-Wise Quantization for Efficient Inference on 4x4 Tile
Sep 26, 2022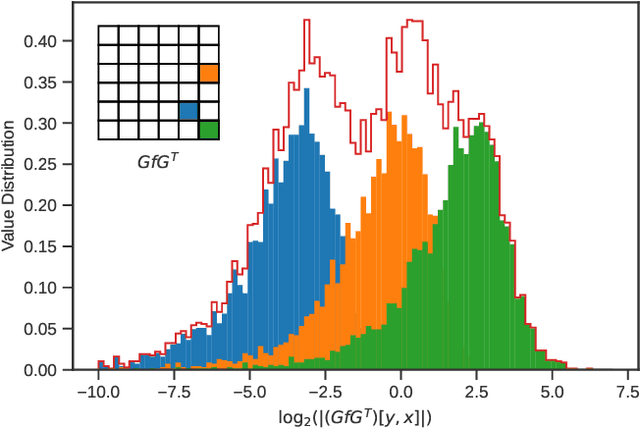

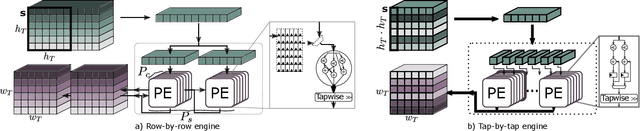
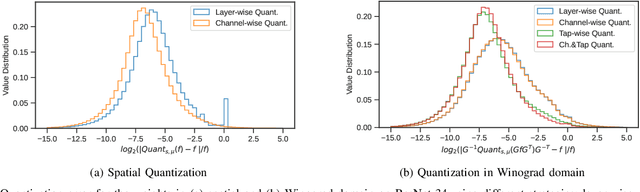
Most of today's computer vision pipelines are built around deep neural networks, where convolution operations require most of the generally high compute effort. The Winograd convolution algorithm computes convolutions with fewer MACs compared to the standard algorithm, reducing the operation count by a factor of 2.25x for 3x3 convolutions when using the version with 2x2-sized tiles $F_2$. Even though the gain is significant, the Winograd algorithm with larger tile sizes, i.e., $F_4$, offers even more potential in improving throughput and energy efficiency, as it reduces the required MACs by 4x. Unfortunately, the Winograd algorithm with larger tile sizes introduces numerical issues that prevent its use on integer domain-specific accelerators and higher computational overhead to transform input and output data between spatial and Winograd domains. To unlock the full potential of Winograd $F_4$, we propose a novel tap-wise quantization method that overcomes the numerical issues of using larger tiles, enabling integer-only inference. Moreover, we present custom hardware units that process the Winograd transformations in a power- and area-efficient way, and we show how to integrate such custom modules in an industrial-grade, programmable DSA. An extensive experimental evaluation on a large set of state-of-the-art computer vision benchmarks reveals that the tap-wise quantization algorithm makes the quantized Winograd $F_4$ network almost as accurate as the FP32 baseline. The Winograd-enhanced DSA achieves up to 1.85x gain in energy efficiency and up to 1.83x end-to-end speed-up for state-of-the-art segmentation and detection networks.
Vau da muntanialas: Energy-efficient multi-die scalable acceleration of RNN inference
Feb 14, 2022



Recurrent neural networks such as Long Short-Term Memories (LSTMs) learn temporal dependencies by keeping an internal state, making them ideal for time-series problems such as speech recognition. However, the output-to-input feedback creates distinctive memory bandwidth and scalability challenges in designing accelerators for RNNs. We present Muntaniala, an RNN accelerator architecture for LSTM inference with a silicon-measured energy-efficiency of 3.25$TOP/s/W$ and performance of 30.53$GOP/s$ in UMC 65 $nm$ technology. The scalable design of Muntaniala allows running large RNN models by combining multiple tiles in a systolic array. We keep all parameters stationary on every die in the array, drastically reducing the I/O communication to only loading new features and sharing partial results with other dies. For quantifying the overall system power, including I/O power, we built Vau da Muntanialas, to the best of our knowledge, the first demonstration of a systolic multi-chip-on-PCB array of RNN accelerator. Our multi-die prototype performs LSTM inference with 192 hidden states in 330$\mu s$ with a total system power of 9.0$mW$ at 10$MHz$ consuming 2.95$\mu J$. Targeting the 8/16-bit quantization implemented in Muntaniala, we show a phoneme error rate (PER) drop of approximately 3% with respect to floating-point (FP) on a 3L-384NH-123NI LSTM network on the TIMIT dataset.
Sub-mW Keyword Spotting on an MCU: Analog Binary Feature Extraction and Binary Neural Networks
Jan 10, 2022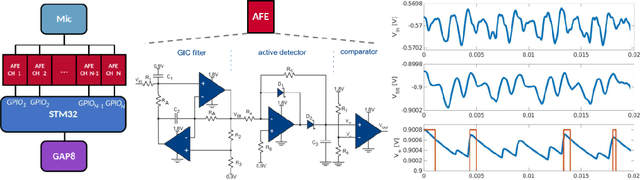

Keyword spotting (KWS) is a crucial function enabling the interaction with the many ubiquitous smart devices in our surroundings, either activating them through wake-word or directly as a human-computer interface. For many applications, KWS is the entry point for our interactions with the device and, thus, an always-on workload. Many smart devices are mobile and their battery lifetime is heavily impacted by continuously running services. KWS and similar always-on services are thus the focus when optimizing the overall power consumption. This work addresses KWS energy-efficiency on low-cost microcontroller units (MCUs). We combine analog binary feature extraction with binary neural networks. By replacing the digital preprocessing with the proposed analog front-end, we show that the energy required for data acquisition and preprocessing can be reduced by 29x, cutting its share from a dominating 85% to a mere 16% of the overall energy consumption for our reference KWS application. Experimental evaluations on the Speech Commands Dataset show that the proposed system outperforms state-of-the-art accuracy and energy efficiency, respectively, by 1% and 4.3x on a 10-class dataset while providing a compelling accuracy-energy trade-off including a 2% accuracy drop for a 71x energy reduction.
Sub-100uW Multispectral Riemannian Classification for EEG-based Brain--Machine Interfaces
Dec 18, 2021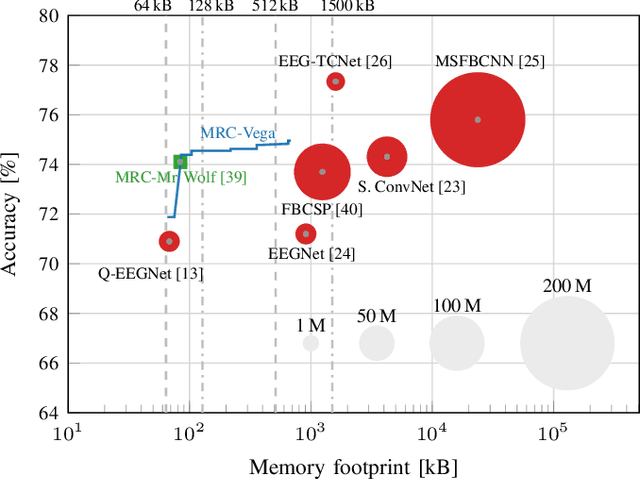

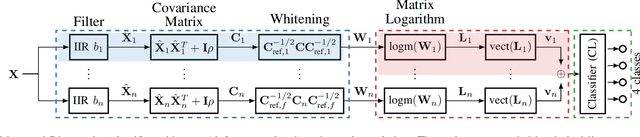
Motor imagery brain--machine interfaces enable us to control machines by merely thinking of performing a motor action. Practical use cases require a wearable solution where the classification of the brain signals is done locally near the sensor using machine learning models embedded on energy-efficient microcontroller units, for assured privacy, user comfort, and long-term usage. In this work, we provide practical insights on the accuracy-cost trade-off for embedded BMI solutions. Our multispectral Riemannian classifier reaches 75.1% accuracy on a 4-class MI task. The accuracy is further improved by tuning different types of classifiers to each subject, achieving 76.4%. We further scale down the model by quantizing it to mixed-precision representations with a minimal accuracy loss of 1% and 1.4%, respectively, which is still up to 4.1% more accurate than the state-of-the-art embedded convolutional neural network. We implement the model on a low-power MCU within an energy budget of merely 198uJ and taking only 16.9ms per classification. Classifying samples continuously, overlapping the 3.5s samples by 50% to avoid missing user inputs allows for operation at just 85uW. Compared to related works in embedded MI-BMIs, our solution sets the new state-of-the-art in terms of accuracy-energy trade-off for near-sensor classification.
Reinforcement Learning for Scalable Logic Optimization with Graph Neural Networks
May 04, 2021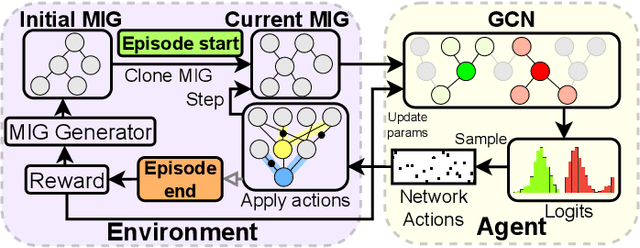
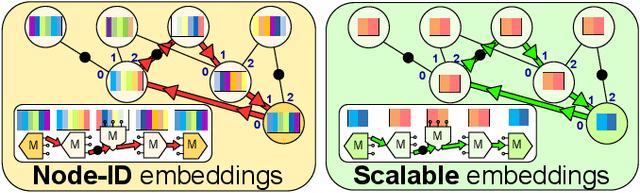
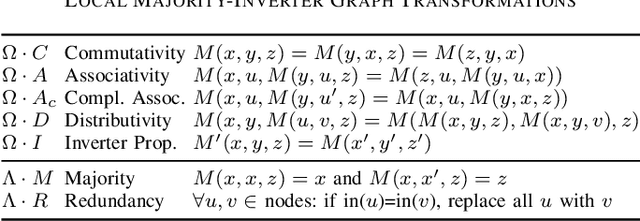
Logic optimization is an NP-hard problem commonly approached through hand-engineered heuristics. We propose to combine graph convolutional networks with reinforcement learning and a novel, scalable node embedding method to learn which local transforms should be applied to the logic graph. We show that this method achieves a similar size reduction as ABC on smaller circuits and outperforms it by 1.5-1.75x on larger random graphs.
ECG-TCN: Wearable Cardiac Arrhythmia Detection with a Temporal Convolutional Network
Mar 25, 2021
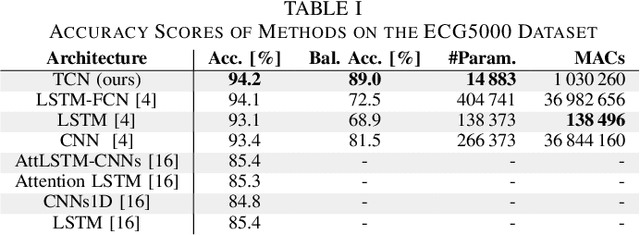
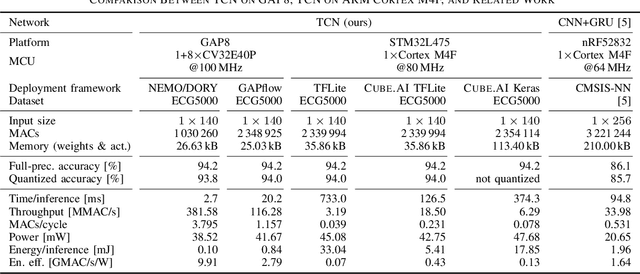
Personalized ubiquitous healthcare solutions require energy-efficient wearable platforms that provide an accurate classification of bio-signals while consuming low average power for long-term battery-operated use. Single lead electrocardiogram (ECG) signals provide the ability to detect, classify, and even predict cardiac arrhythmia. In this paper, we propose a novel temporal convolutional network (TCN) that achieves high accuracy while still being feasible for wearable platform use. Experimental results on the ECG5000 dataset show that the TCN has a similar accuracy (94.2%) score as the state-of-the-art (SoA) network while achieving an improvement of 16.5% in the balanced accuracy score. This accurate classification is done with 27 times fewer parameters and 37 times less multiply-accumulate operations. We test our implementation on two publicly available platforms, the STM32L475, which is based on ARM Cortex M4F, and the GreenWaves Technologies GAP8 on the GAPuino board, based on 1+8 RISC-V CV32E40P cores. Measurements show that the GAP8 implementation respects the real-time constraints while consuming 0.10 mJ per inference. With 9.91 GMAC/s/W, it is 23.0 times more energy-efficient and 46.85 times faster than an implementation on the ARM Cortex M4F (0.43 GMAC/s/W). Overall, we obtain 8.1% higher accuracy while consuming 19.6 times less energy and being 35.1 times faster compared to a previous SoA embedded implementation.
Mixed-Precision Quantization and Parallel Implementation of Multispectral Riemannian Classification for Brain--Machine Interfaces
Feb 22, 2021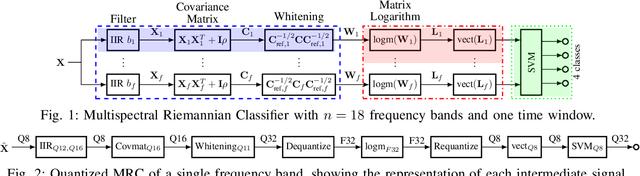
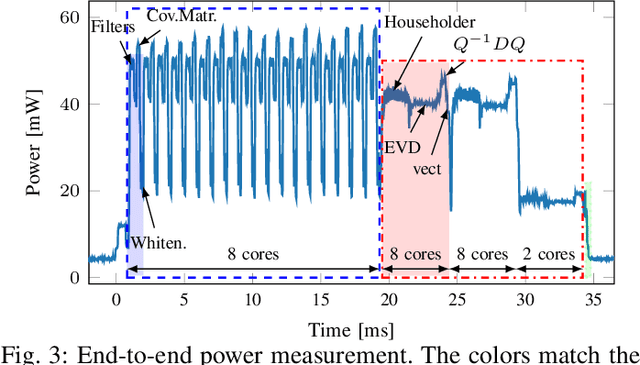
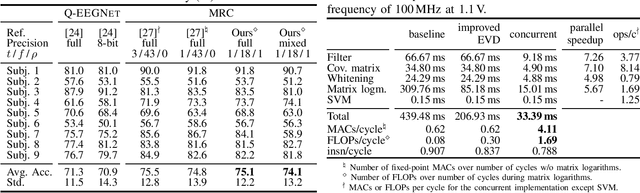
With Motor-Imagery (MI) Brain--Machine Interfaces (BMIs) we may control machines by merely thinking of performing a motor action. Practical use cases require a wearable solution where the classification of the brain signals is done locally near the sensor using machine learning models embedded on energy-efficient microcontroller units (MCUs), for assured privacy, user comfort, and long-term usage. In this work, we provide practical insights on the accuracy-cost tradeoff for embedded BMI solutions. Our proposed Multispectral Riemannian Classifier reaches 75.1% accuracy on 4-class MI task. We further scale down the model by quantizing it to mixed-precision representations with a minimal accuracy loss of 1%, which is still 3.2% more accurate than the state-of-the-art embedded convolutional neural network. We implement the model on a low-power MCU with parallel processing units taking only 33.39ms and consuming 1.304mJ per classification.
Sound Event Detection with Binary Neural Networks on Tightly Power-Constrained IoT Devices
Jan 12, 2021
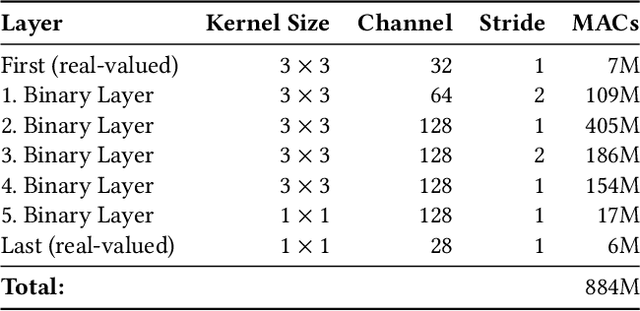
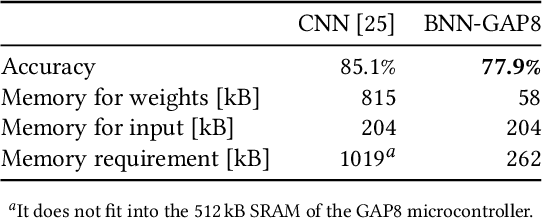
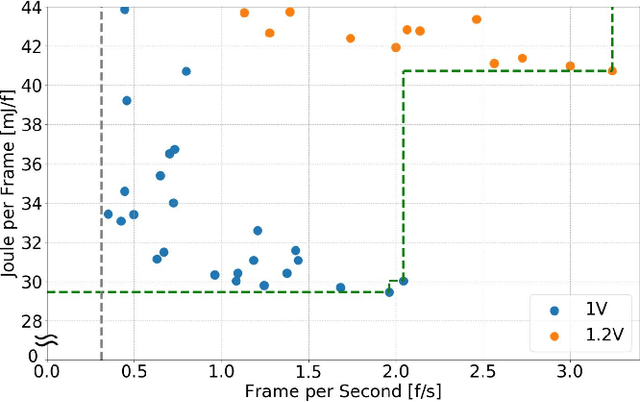
Sound event detection (SED) is a hot topic in consumer and smart city applications. Existing approaches based on Deep Neural Networks are very effective, but highly demanding in terms of memory, power, and throughput when targeting ultra-low power always-on devices. Latency, availability, cost, and privacy requirements are pushing recent IoT systems to process the data on the node, close to the sensor, with a very limited energy supply, and tight constraints on the memory size and processing capabilities precluding to run state-of-the-art DNNs. In this paper, we explore the combination of extreme quantization to a small-footprint binary neural network (BNN) with the highly energy-efficient, RISC-V-based (8+1)-core GAP8 microcontroller. Starting from an existing CNN for SED whose footprint (815 kB) exceeds the 512 kB of memory available on our platform, we retrain the network using binary filters and activations to match these memory constraints. (Fully) binary neural networks come with a natural drop in accuracy of 12-18% on the challenging ImageNet object recognition challenge compared to their equivalent full-precision baselines. This BNN reaches a 77.9% accuracy, just 7% lower than the full-precision version, with 58 kB (7.2 times less) for the weights and 262 kB (2.4 times less) memory in total. With our BNN implementation, we reach a peak throughput of 4.6 GMAC/s and 1.5 GMAC/s over the full network, including preprocessing with Mel bins, which corresponds to an efficiency of 67.1 GMAC/s/W and 31.3 GMAC/s/W, respectively. Compared to the performance of an ARM Cortex-M4 implementation, our system has a 10.3 times faster execution time and a 51.1 times higher energy-efficiency.
EEG-TCNet: An Accurate Temporal Convolutional Network for Embedded Motor-Imagery Brain-Machine Interfaces
May 31, 2020
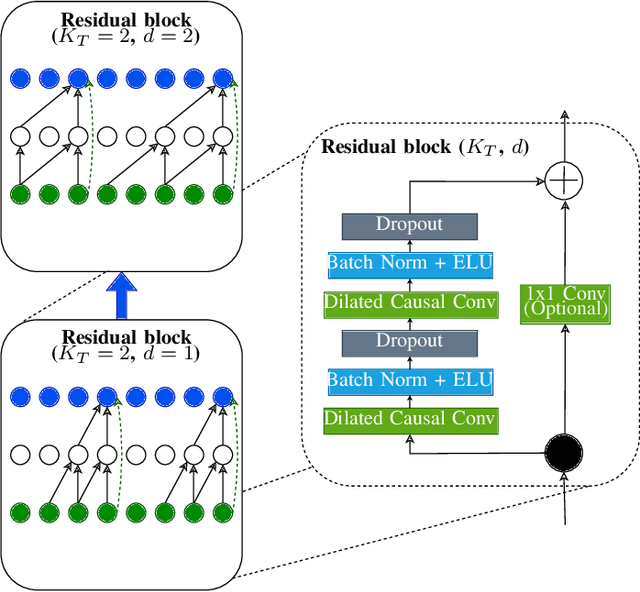

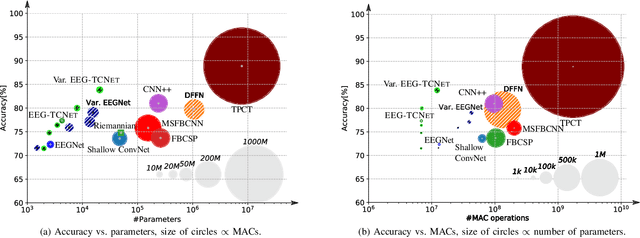
In recent years, deep learning (DL) has contributed significantly to the improvement of motor-imagery brain-machine interfaces (MI-BMIs) based on electroencephalography(EEG). While achieving high classification accuracy, DL models have also grown in size, requiring a vast amount of memory and computational resources. This poses a major challenge to an embedded BMI solution that guarantees user privacy, reduced latency, and low power consumption by processing the data locally. In this paper, we propose EEG-TCNet, a novel temporal convolutional network (TCN) that achieves outstanding accuracy while requiring few trainable parameters. Its low memory footprint and low computational complexity for inference make it suitable for embedded classification on resource-limited devices at the edge. Experimental results on the BCI Competition IV-2a dataset show that EEG-TCNet achieves 77.35% classification accuracy in 4-class MI. By finding the optimal network hyperparameters per subject, we further improve the accuracy to 83.84%. Finally, we demonstrate the versatility of EEG-TCNet on the Mother of All BCI Benchmarks (MOABB), a large scale test benchmark containing 12 different EEG datasets with MI experiments. The results indicate that EEG-TCNet successfully generalizes beyond one single dataset, outperforming the current state-of-the-art (SoA) on MOABB by a meta-effect of 0.25.