 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemEval-2017 Task 1: Semantic Textual Similarity - Multilingual and Cross-lingual Focused Evaluation
Jul 31, 2017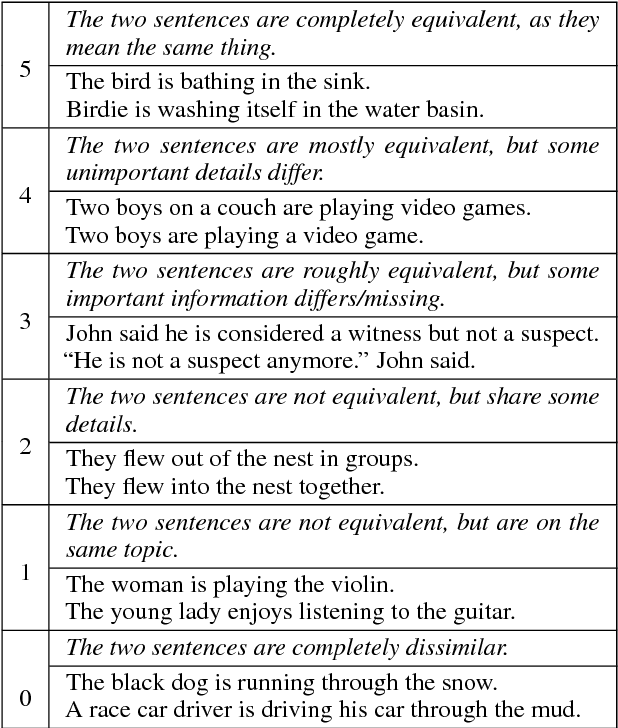
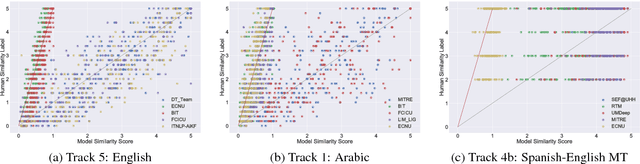
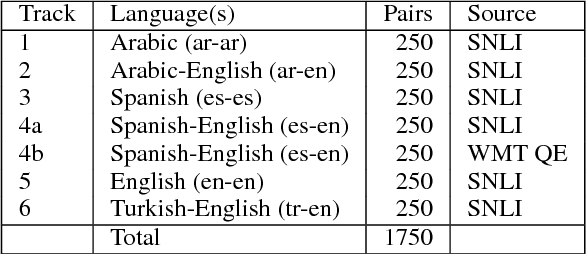
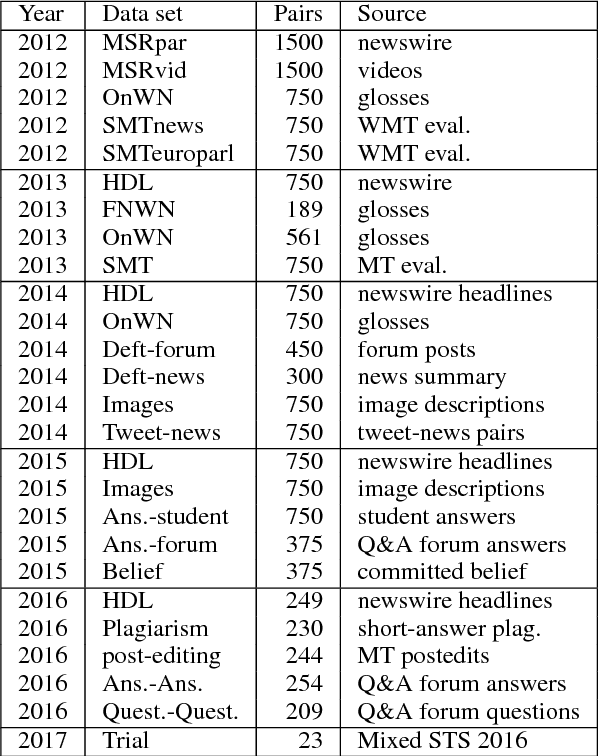
Semantic Textual Similarity (STS) measures the meaning similarity of sentences. Applications include machine translation (MT), summarization, generation, question answering (QA), short answer grading, semantic search, dialog and conversational systems. The STS shared task is a venue for assessing the current state-of-the-art. The 2017 task focuses on multilingual and cross-lingual pairs with one sub-track exploring MT quality estimation (MTQE) data. The task obtained strong participation from 31 teams, with 17 participating in all language tracks. We summarize performance and review a selection of well performing methods. Analysis highlights common errors, providing insight into the limitations of existing models. To support ongoing work on semantic representations, the STS Benchmark is introduced as a new shared training and evaluation set carefully selected from the corpus of English STS shared task data (2012-2017).
Personalized Machine Translation: Preserving Original Author Traits
Jan 12, 2017
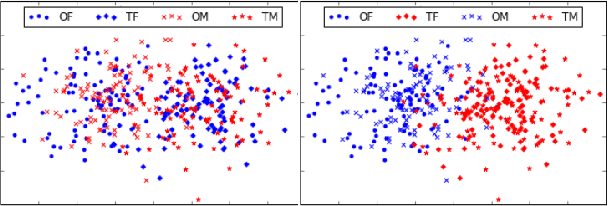
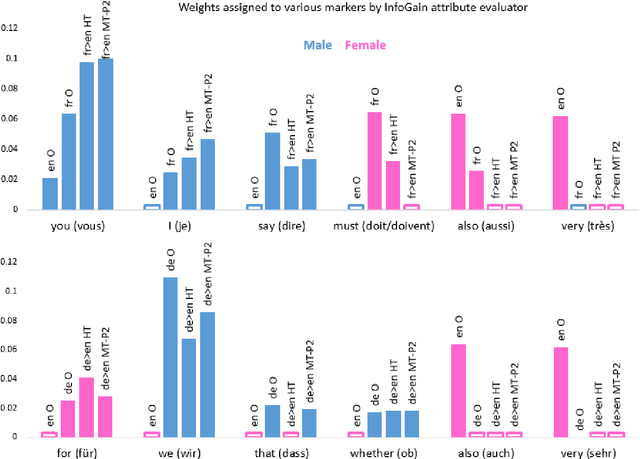
The language that we produce reflects our personality, and various personal and demographic characteristics can be detected in natural language texts. We focus on one particular personal trait of the author, gender, and study how it is manifested in original texts and in translations. We show that author's gender has a powerful, clear signal in originals texts, but this signal is obfuscated in human and machine translation. We then propose simple domain-adaptation techniques that help retain the original gender traits in the translation, without harming the quality of the translation, thereby creating more personalized machine translation systems.
Vicinity-Driven Paragraph and Sentence Alignment for Comparable Corpora
Dec 13, 2016Parallel corpora have driven great progress in the field of Text Simplification. However, most sentence alignment algorithms either offer a limited range of alignment types supported, or simply ignore valuable clues present in comparable documents. We address this problem by introducing a new set of flexible vicinity-driven paragraph and sentence alignment algorithms that 1-N, N-1, N-N and long distance null alignments without the need for hard-to-replicate supervised models.
Exploring Prediction Uncertainty in Machine Translation Quality Estimation
Jun 30, 2016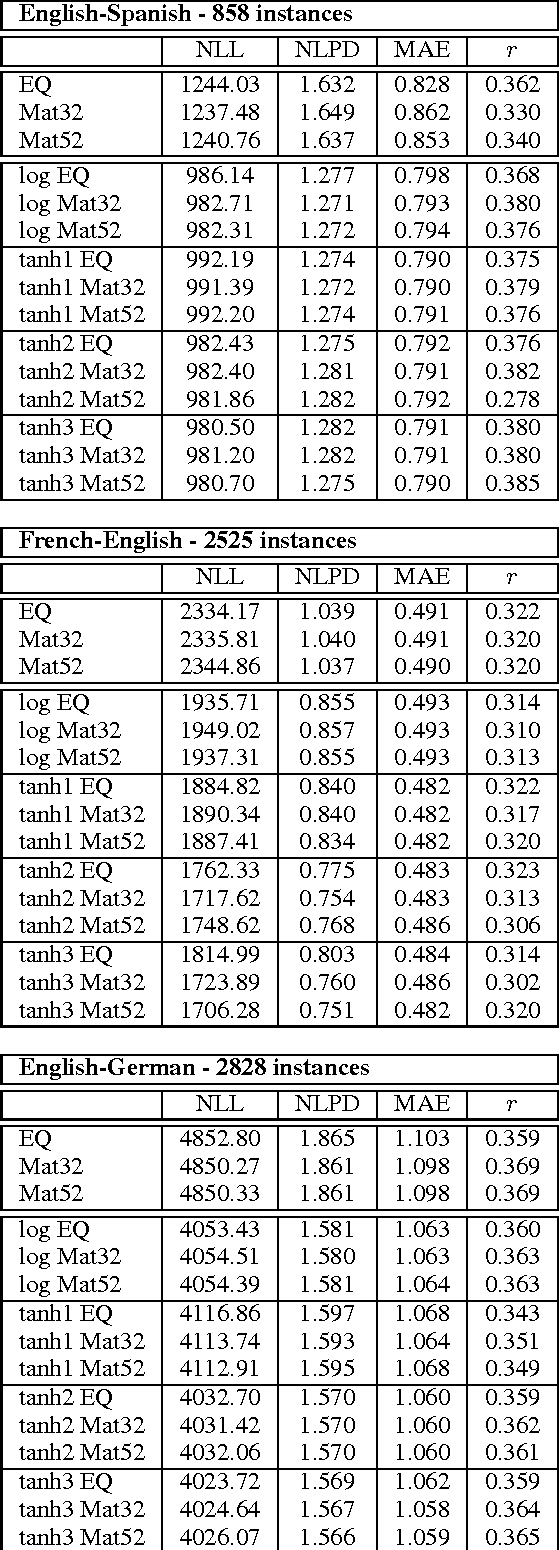
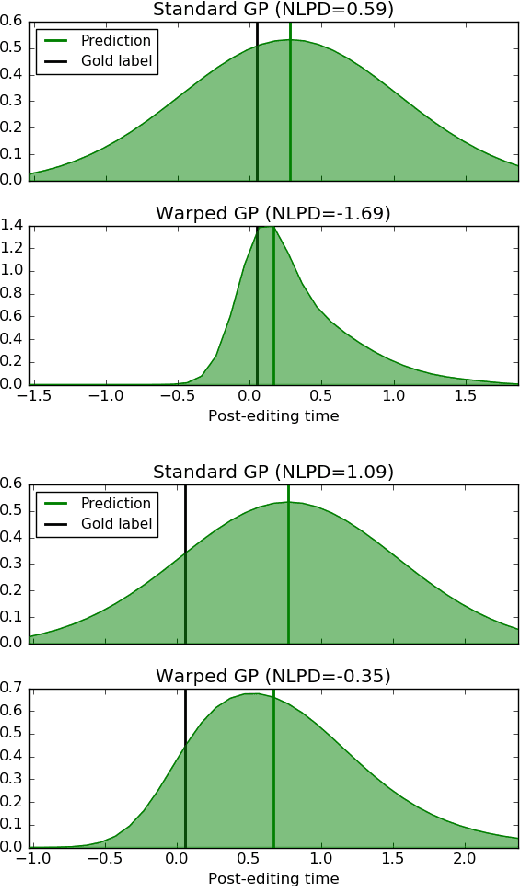
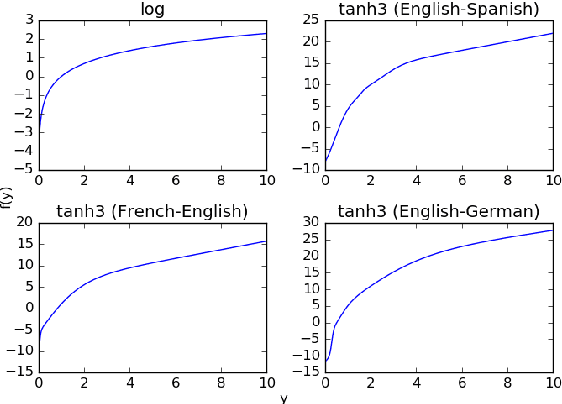
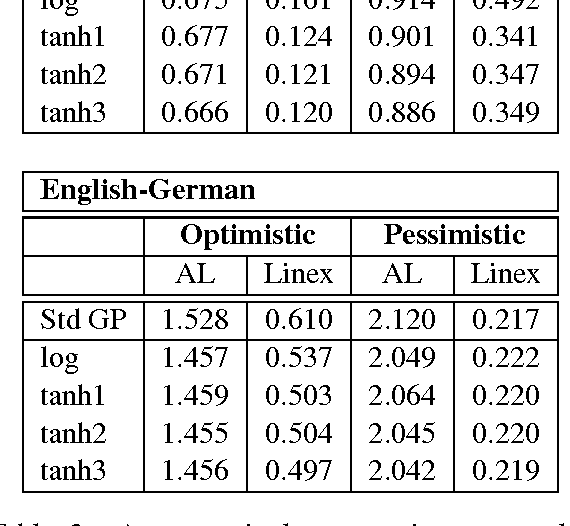
Machine Translation Quality Estimation is a notoriously difficult task, which lessens its usefulness in real-world translation environments. Such scenarios can be improved if quality predictions are accompanied by a measure of uncertainty. However, models in this task are traditionally evaluated only in terms of point estimate metrics, which do not take prediction uncertainty into account. We investigate probabilistic methods for Quality Estimation that can provide well-calibrated uncertainty estimates and evaluate them in terms of their full posterior predictive distributions. We also show how this posterior information can be useful in an asymmetric risk scenario, which aims to capture typical situations in translation workflows.
Multi30K: Multilingual English-German Image Descriptions
May 02, 2016
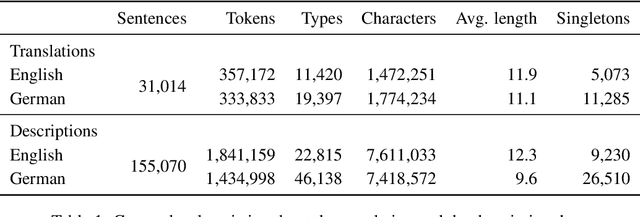

We introduce the Multi30K dataset to stimulate multilingual multimodal research. Recent advances in image description have been demonstrated on English-language datasets almost exclusively, but image description should not be limited to English. This dataset extends the Flickr30K dataset with i) German translations created by professional translators over a subset of the English descriptions, and ii) descriptions crowdsourced independently of the original English descriptions. We outline how the data can be used for multilingual image description and multimodal machine translation, but we anticipate the data will be useful for a broader range of tasks.
The USFD Spoken Language Translation System for IWSLT 2014
Sep 13, 2015
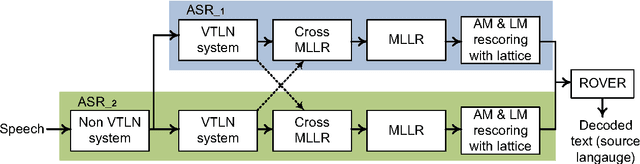
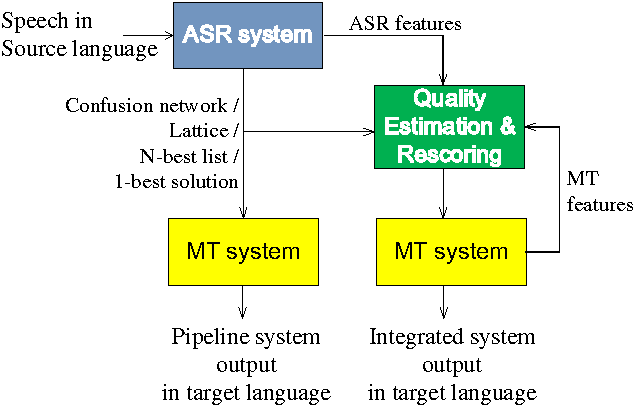
The University of Sheffield (USFD) participated in the International Workshop for Spoken Language Translation (IWSLT) in 2014. In this paper, we will introduce the USFD SLT system for IWSLT. Automatic speech recognition (ASR) is achieved by two multi-pass deep neural network systems with adaptation and rescoring techniques. Machine translation (MT) is achieved by a phrase-based system. The USFD primary system incorporates state-of-the-art ASR and MT techniques and gives a BLEU score of 23.45 and 14.75 on the English-to-French and English-to-German speech-to-text translation task with the IWSLT 2014 data. The USFD contrastive systems explore the integration of ASR and MT by using a quality estimation system to rescore the ASR outputs, optimising towards better translation. This gives a further 0.54 and 0.26 BLEU improvement respectively on the IWSLT 2012 and 2014 evaluation data.
Learning Structural Kernels for Natural Language Processing
Aug 10, 2015Structural kernels are a flexible learning paradigm that has been widely used in Natural Language Processing. However, the problem of model selection in kernel-based methods is usually overlooked. Previous approaches mostly rely on setting default values for kernel hyperparameters or using grid search, which is slow and coarse-grained. In contrast, Bayesian methods allow efficient model selection by maximizing the evidence on the training data through gradient-based methods. In this paper we show how to perform this in the context of structural kernels by using Gaussian Processes. Experimental results on tree kernels show that this procedure results in better prediction performance compared to hyperparameter optimization via grid search. The framework proposed in this paper can be adapted to other structures besides trees, e.g., strings and graphs, thereby extending the utility of kernel-based methods.