 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the advantages of stochastic encoders
Feb 18, 2021
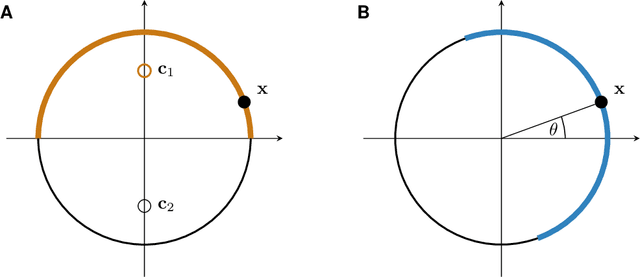

Stochastic encoders have been used in rate-distortion theory and neural compression because they can be easier to handle. However, in performance comparisons with deterministic encoders they often do worse, suggesting that noise in the encoding process may generally be a bad idea. It is poorly understood if and when stochastic encoders do better than deterministic encoders. In this paper we provide one illustrative example which shows that stochastic encoders can significantly outperform the best deterministic encoders. Our toy example suggests that stochastic encoders may be particularly useful in the regime of "perfect perceptual quality".
Universally Quantized Neural Compression
Jun 17, 2020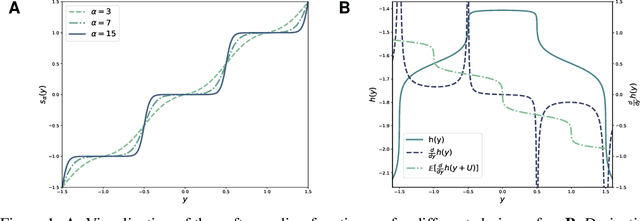
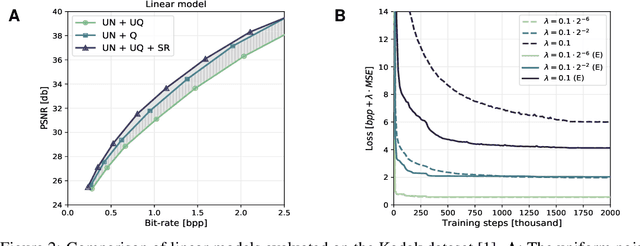
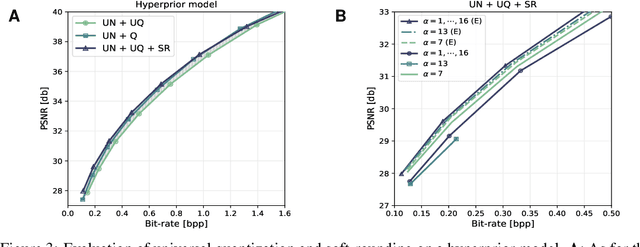

A popular approach to learning encoders for lossy compression is to use additive uniform noise during training as a differentiable approximation to test-time quantization. We demonstrate that a uniform noise channel can also be implemented at test time using universal quantization (Ziv, 1985). This allows us to eliminate the mismatch between training and test phases while maintaining a completely differentiable loss function. Implementing the uniform noise channel is a special case of a more general problem to communicate a sample, which we prove is computationally hard if we do not make assumptions about its distribution. However, the uniform special case is efficient as well as easy to implement and thus of great interest from a practical point of view. Finally, we show that quantization can be obtained as a limiting case of a soft quantizer applied to the uniform noise channel, bridging compression with and without quantization.
Discriminative Topic Modeling with Logistic LDA
Sep 03, 2019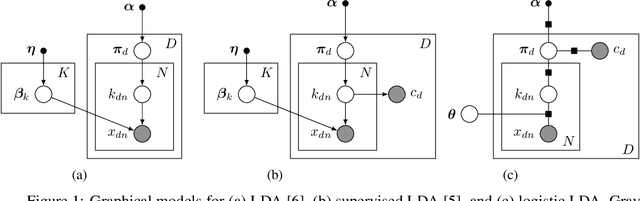


Despite many years of research into latent Dirichlet allocation (LDA), applying LDA to collections of non-categorical items is still challenging. Yet many problems with much richer data share a similar structure and could benefit from the vast literature on LDA. We propose logistic LDA, a novel discriminative variant of latent Dirichlet allocation which is easy to apply to arbitrary inputs. In particular, our model can easily be applied to groups of images, arbitrary text embeddings, and integrate well with deep neural networks. Although it is a discriminative model, we show that logistic LDA can learn from unlabeled data in an unsupervised manner by exploiting the group structure present in the data. In contrast to other recent topic models designed to handle arbitrary inputs, our model does not sacrifice the interpretability and principled motivation of LDA.
Addressing Delayed Feedback for Continuous Training with Neural Networks in CTR prediction
Jul 15, 2019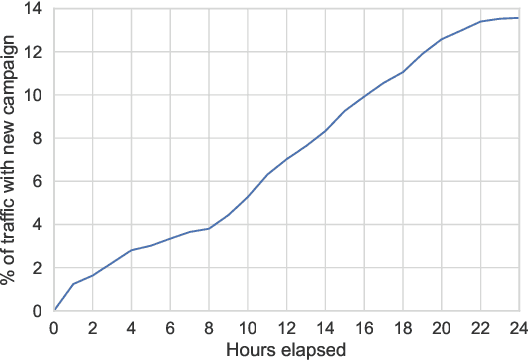
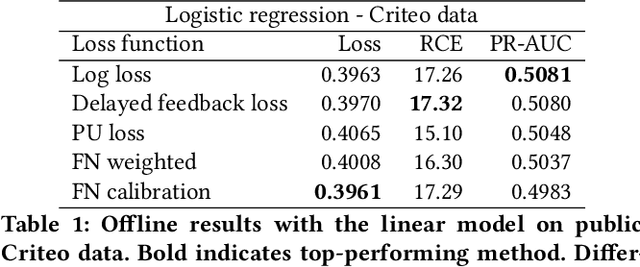
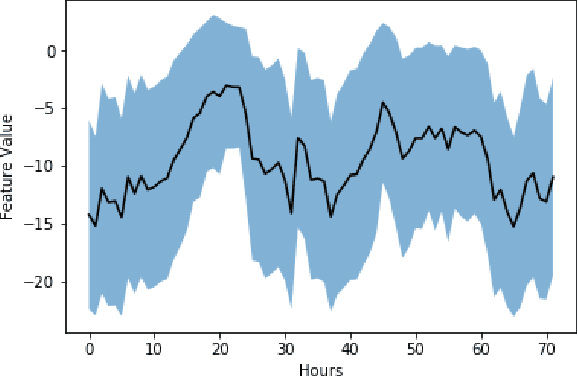
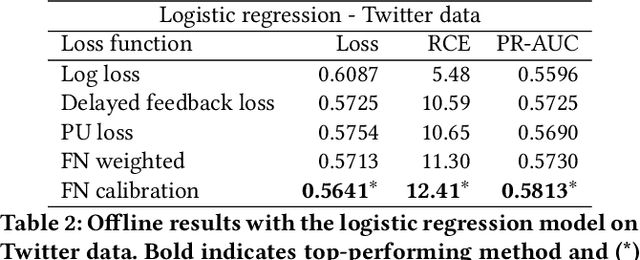
One of the challenges in display advertising is that the distribution of features and click through rate (CTR) can exhibit large shifts over time due to seasonality, changes to ad campaigns and other factors. The predominant strategy to keep up with these shifts is to train predictive models continuously, on fresh data, in order to prevent them from becoming stale. However, in many ad systems positive labels are only observed after a possibly long and random delay. These delayed labels pose a challenge to data freshness in continuous training: fresh data may not have complete label information at the time they are ingested by the training algorithm. Naive strategies which consider any data point a negative example until a positive label becomes available tend to underestimate CTR, resulting in inferior user experience and suboptimal performance for advertisers. The focus of this paper is to identify the best combination of loss functions and models that enable large-scale learning from a continuous stream of data in the presence of delayed labels. In this work, we compare 5 different loss functions, 3 of them applied to this problem for the first time. We benchmark their performance in offline settings on both public and proprietary datasets in conjunction with shallow and deep model architectures. We also discuss the engineering cost associated with implementing each loss function in a production environment. Finally, we carried out online experiments with the top performing methods, in order to validate their performance in a continuous training scheme. While training on 668 million in-house data points offline, our proposed methods outperform previous state-of-the-art by 3% relative cross entropy (RCE). During online experiments, we observed 55% gain in revenue per thousand requests (RPMq) against naive log loss.
HoloGAN: Unsupervised learning of 3D representations from natural images
Apr 02, 2019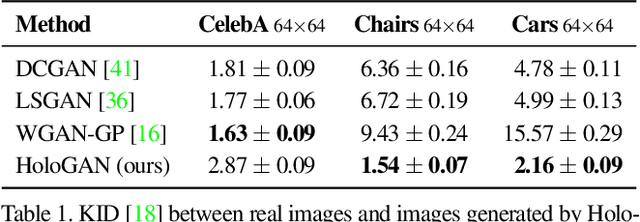
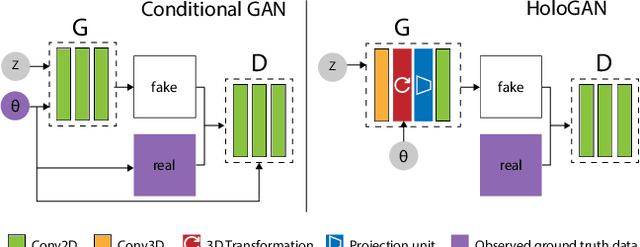
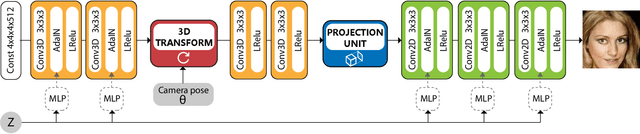

We propose a novel generative adversarial network (GAN) for the task of unsupervised learning of 3D representations from natural images. Most generative models rely on 2D kernels to generate images and make few assumptions about the 3D world. These models therefore tend to create blurry images or artefacts in tasks that require a strong 3D understanding, such as novel-view synthesis. HoloGAN instead learns a 3D representation of the world, and to render this representation in a realistic manner. Unlike other GANs, HoloGAN provides explicit control over the pose of generated objects through rigid-body transformations of the learnt 3D features. Our experiments show that using explicit 3D features enables HoloGAN to disentangle 3D pose and identity, which is further decomposed into shape and appearance, while still being able to generate images with similar or higher visual quality than other generative models. HoloGAN can be trained end-to-end from unlabelled 2D images only. Particularly, we do not require pose labels, 3D shapes, or multiple views of the same objects. This shows that HoloGAN is the first generative model that learns 3D representations from natural images in an entirely unsupervised manner.
Faster gaze prediction with dense networks and Fisher pruning
Jul 09, 2018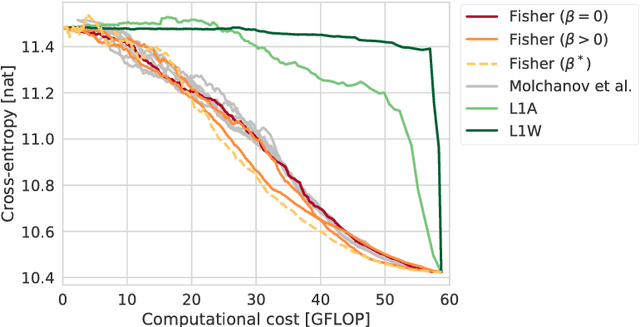
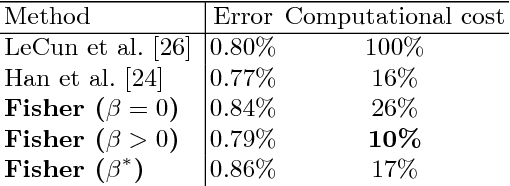
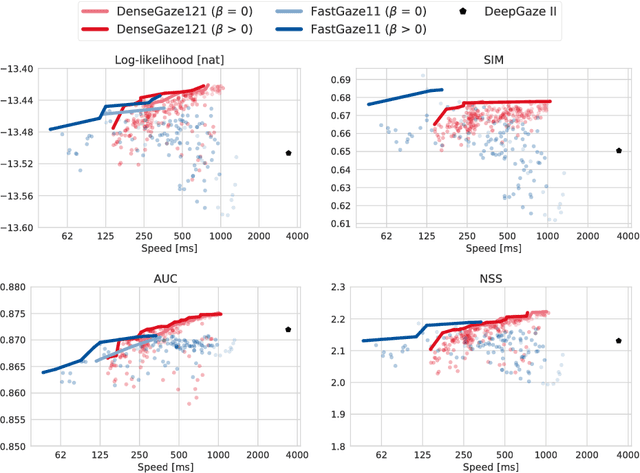
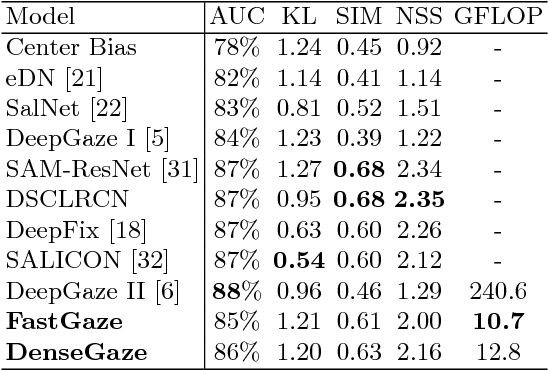
Predicting human fixations from images has recently seen large improvements by leveraging deep representations which were pretrained for object recognition. However, as we show in this paper, these networks are highly overparameterized for the task of fixation prediction. We first present a simple yet principled greedy pruning method which we call Fisher pruning. Through a combination of knowledge distillation and Fisher pruning, we obtain much more runtime-efficient architectures for saliency prediction, achieving a 10x speedup for the same AUC performance as a state of the art network on the CAT2000 dataset. Speeding up single-image gaze prediction is important for many real-world applications, but it is also a crucial step in the development of video saliency models, where the amount of data to be processed is substantially larger.
Fast Face-swap Using Convolutional Neural Networks
Jul 27, 2017
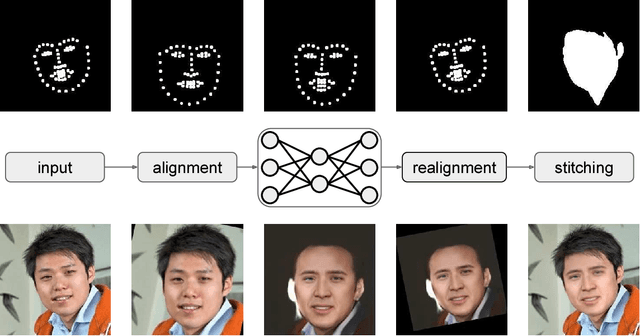
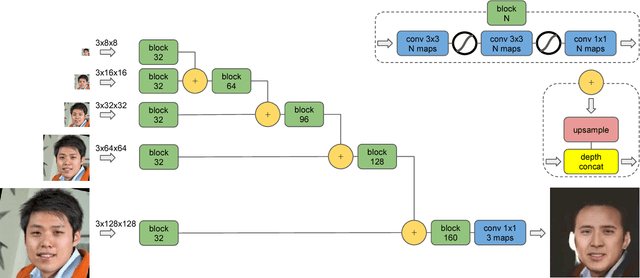
We consider the problem of face swapping in images, where an input identity is transformed into a target identity while preserving pose, facial expression, and lighting. To perform this mapping, we use convolutional neural networks trained to capture the appearance of the target identity from an unstructured collection of his/her photographs.This approach is enabled by framing the face swapping problem in terms of style transfer, where the goal is to render an image in the style of another one. Building on recent advances in this area, we devise a new loss function that enables the network to produce highly photorealistic results. By combining neural networks with simple pre- and post-processing steps, we aim at making face swap work in real-time with no input from the user.
Checkerboard artifact free sub-pixel convolution: A note on sub-pixel convolution, resize convolution and convolution resize
Jul 10, 2017
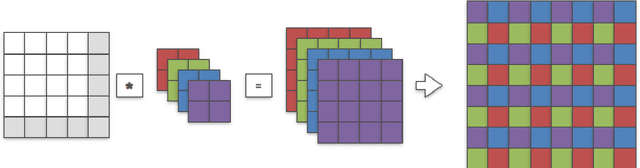
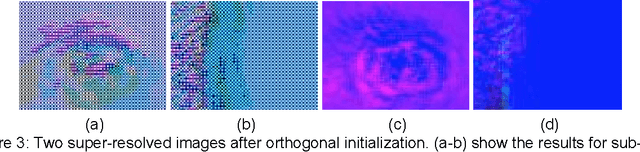
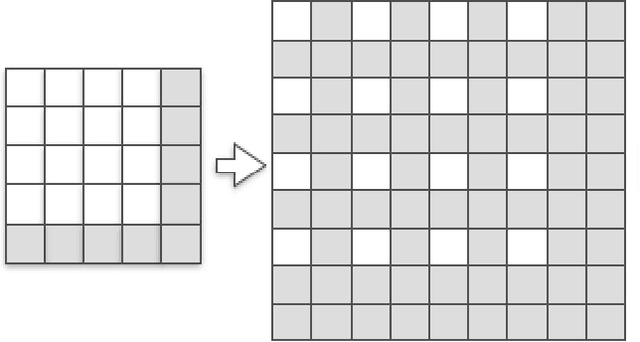
The most prominent problem associated with the deconvolution layer is the presence of checkerboard artifacts in output images and dense labels. To combat this problem, smoothness constraints, post processing and different architecture designs have been proposed. Odena et al. highlight three sources of checkerboard artifacts: deconvolution overlap, random initialization and loss functions. In this note, we proposed an initialization method for sub-pixel convolution known as convolution NN resize. Compared to sub-pixel convolution initialized with schemes designed for standard convolution kernels, it is free from checkerboard artifacts immediately after initialization. Compared to resize convolution, at the same computational complexity, it has more modelling power and converges to solutions with smaller test errors.
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
May 25, 2017
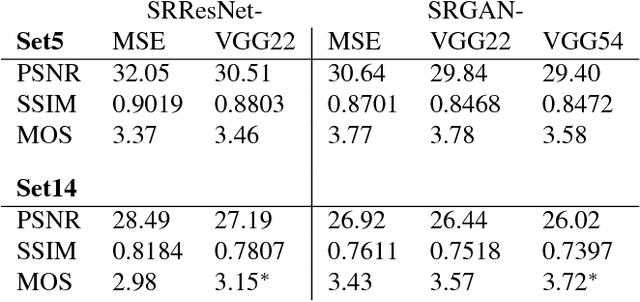

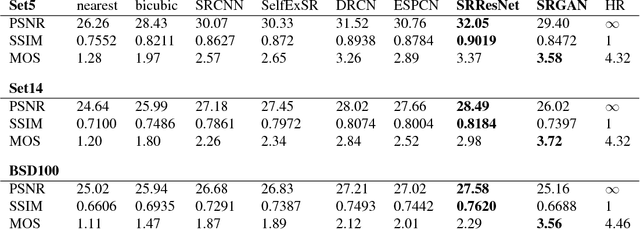
Despite the breakthroughs in accuracy and speed of single image super-resolution using faster and deeper convolutional neural networks, one central problem remains largely unsolved: how do we recover the finer texture details when we super-resolve at large upscaling factors? The behavior of optimization-based super-resolution methods is principally driven by the choice of the objective function. Recent work has largely focused on minimizing the mean squared reconstruction error. The resulting estimates have high peak signal-to-noise ratios, but they are often lacking high-frequency details and are perceptually unsatisfying in the sense that they fail to match the fidelity expected at the higher resolution. In this paper, we present SRGAN, a generative adversarial network (GAN) for image super-resolution (SR). To our knowledge, it is the first framework capable of inferring photo-realistic natural images for 4x upscaling factors. To achieve this, we propose a perceptual loss function which consists of an adversarial loss and a content loss. The adversarial loss pushes our solution to the natural image manifold using a discriminator network that is trained to differentiate between the super-resolved images and original photo-realistic images. In addition, we use a content loss motivated by perceptual similarity instead of similarity in pixel space. Our deep residual network is able to recover photo-realistic textures from heavily downsampled images on public benchmarks. An extensive mean-opinion-score (MOS) test shows hugely significant gains in perceptual quality using SRGAN. The MOS scores obtained with SRGAN are closer to those of the original high-resolution images than to those obtained with any state-of-the-art method.
Lossy Image Compression with Compressive Autoencoders
Mar 01, 2017
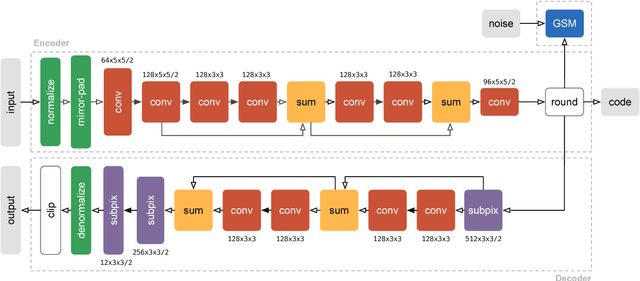
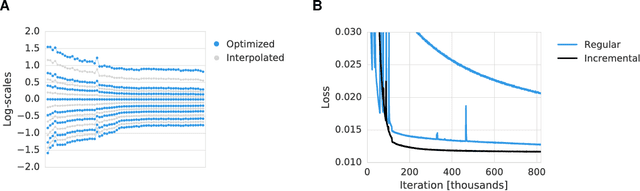
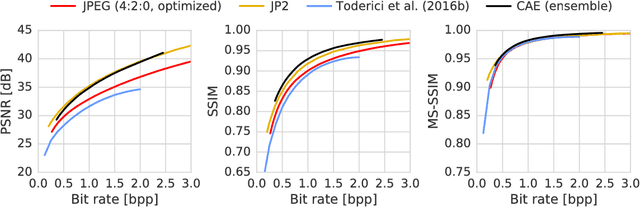
We propose a new approach to the problem of optimizing autoencoders for lossy image compression. New media formats, changing hardware technology, as well as diverse requirements and content types create a need for compression algorithms which are more flexible than existing codecs. Autoencoders have the potential to address this need, but are difficult to optimize directly due to the inherent non-differentiabilty of the compression loss. We here show that minimal changes to the loss are sufficient to train deep autoencoders competitive with JPEG 2000 and outperforming recently proposed approaches based on RNNs. Our network is furthermore computationally efficient thanks to a sub-pixel architecture, which makes it suitable for high-resolution images. This is in contrast to previous work on autoencoders for compression using coarser approximations, shallower architectures, computationally expensive methods, or focusing on small images.