 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Agile Text Classifiers for Everyone
Feb 13, 2023



Text-based safety classifiers are widely used for content moderation and increasingly to tune generative language model behavior - a topic of growing concern for the safety of digital assistants and chatbots. However, different policies require different classifiers, and safety policies themselves improve from iteration and adaptation. This paper introduces and evaluates methods for agile text classification, whereby classifiers are trained using small, targeted datasets that can be quickly developed for a particular policy. Experimenting with 7 datasets from three safety-related domains, comprising 15 annotation schemes, led to our key finding: prompt-tuning large language models, like PaLM 62B, with a labeled dataset of as few as 80 examples can achieve state-of-the-art performance. We argue that this enables a paradigm shift for text classification, especially for models supporting safer online discourse. Instead of collecting millions of examples to attempt to create universal safety classifiers over months or years, classifiers could be tuned using small datasets, created by individuals or small organizations, tailored for specific use cases, and iterated on and adapted in the time-span of a day.
KNNs of Semantic Encodings for Rating Prediction
Feb 01, 2023



This paper explores a novel application of textual semantic similarity to user-preference representation for rating prediction. The approach represents a user's preferences as a graph of textual snippets from review text, where the edges are defined by semantic similarity. This textual, memory-based approach to rating prediction enables review-based explanations for recommendations. The method is evaluated quantitatively, highlighting that leveraging text in this way outperforms both strong memory-based and model-based collaborative filtering baselines.
Beyond Rewards: a Hierarchical Perspective on Offline Multiagent Behavioral Analysis
Jun 17, 2022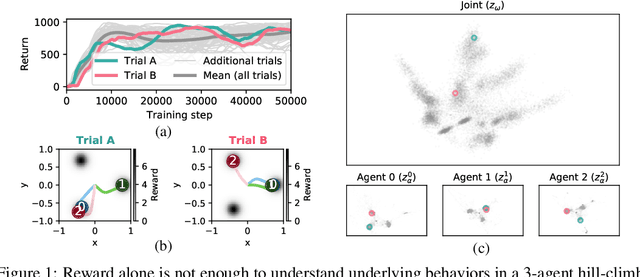
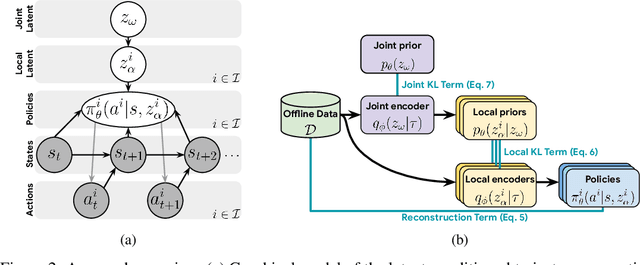
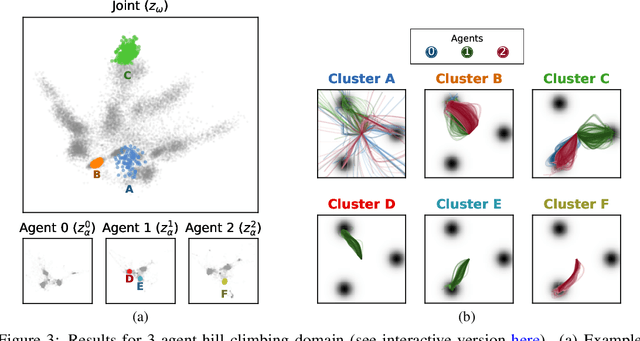

Each year, expert-level performance is attained in increasingly-complex multiagent domains, notable examples including Go, Poker, and StarCraft II. This rapid progression is accompanied by a commensurate need to better understand how such agents attain this performance, to enable their safe deployment, identify limitations, and reveal potential means of improving them. In this paper we take a step back from performance-focused multiagent learning, and instead turn our attention towards agent behavior analysis. We introduce a model-agnostic method for discovery of behavior clusters in multiagent domains, using variational inference to learn a hierarchy of behaviors at the joint and local agent levels. Our framework makes no assumption about agents' underlying learning algorithms, does not require access to their latent states or models, and can be trained using entirely offline observational data. We illustrate the effectiveness of our method for enabling the coupled understanding of behaviors at the joint and local agent level, detection of behavior changepoints throughout training, discovery of core behavioral concepts (e.g., those that facilitate higher returns), and demonstrate the approach's scalability to a high-dimensional multiagent MuJoCo control domain.
On Natural Language User Profiles for Transparent and Scrutable Recommendation
May 19, 2022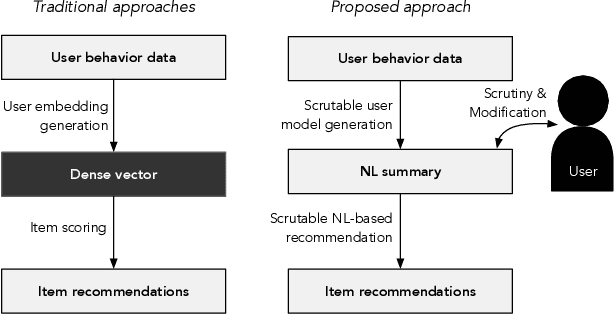



Natural interaction with recommendation and personalized search systems has received tremendous attention in recent years. We focus on the challenge of supporting people's understanding and control of these systems and explore a fundamentally new way of thinking about representation of knowledge in recommendation and personalization systems. Specifically, we argue that it may be both desirable and possible for algorithms that use natural language representations of users' preferences to be developed. We make the case that this could provide significantly greater transparency, as well as affordances for practical actionable interrogation of, and control over, recommendations. Moreover, we argue that such an approach, if successfully applied, may enable a major step towards systems that rely less on noisy implicit observations while increasing portability of knowledge of one's interests.
GLaM: Efficient Scaling of Language Models with Mixture-of-Experts
Dec 13, 2021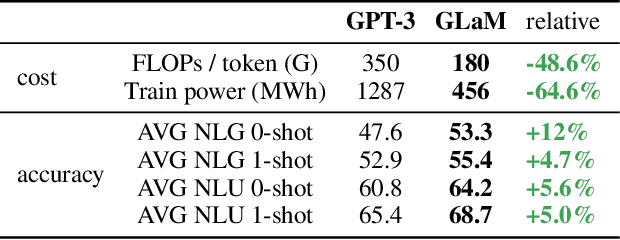
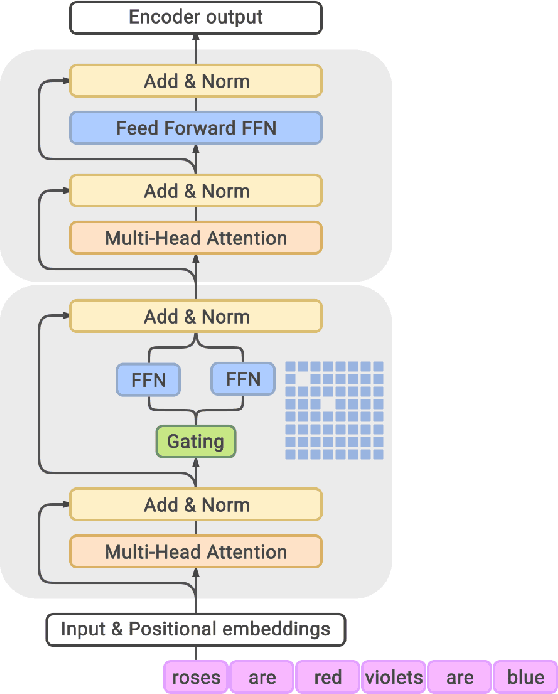
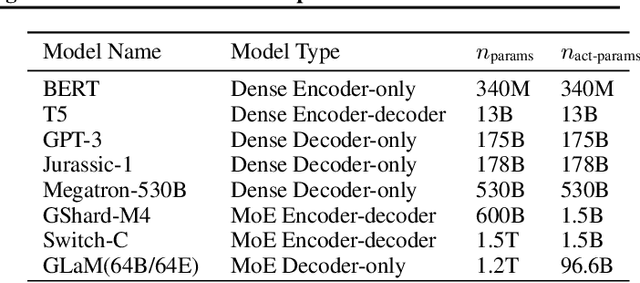
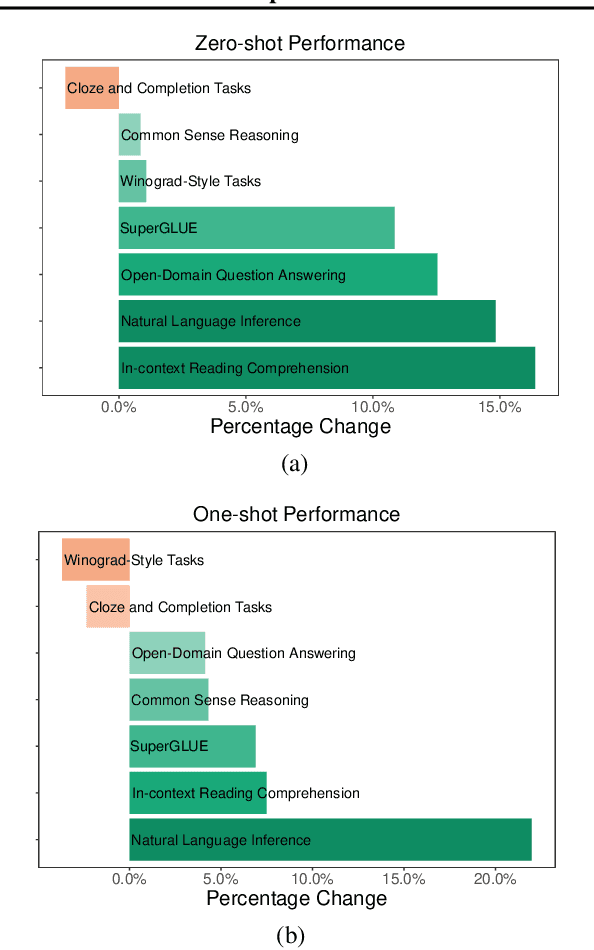
Scaling language models with more data, compute and parameters has driven significant progress in natural language processing. For example, thanks to scaling, GPT-3 was able to achieve strong results on in-context learning tasks. However, training these large dense models requires significant amounts of computing resources. In this paper, we propose and develop a family of language models named GLaM (Generalist Language Model), which uses a sparsely activated mixture-of-experts architecture to scale the model capacity while also incurring substantially less training cost compared to dense variants. The largest GLaM has 1.2 trillion parameters, which is approximately 7x larger than GPT-3. It consumes only 1/3 of the energy used to train GPT-3 and requires half of the computation flops for inference, while still achieving better overall zero-shot and one-shot performance across 29 NLP tasks.
Toxicity Detection can be Sensitive to the Conversational Context
Nov 19, 2021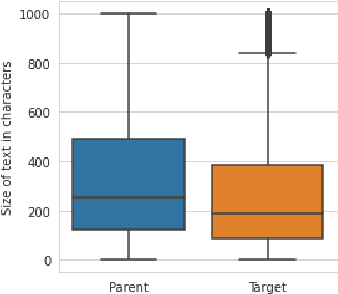

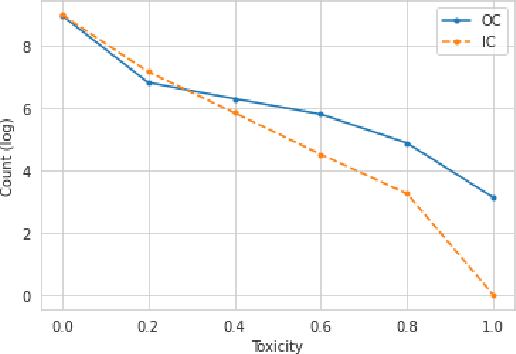
User posts whose perceived toxicity depends on the conversational context are rare in current toxicity detection datasets. Hence, toxicity detectors trained on existing datasets will also tend to disregard context, making the detection of context-sensitive toxicity harder when it does occur. We construct and publicly release a dataset of 10,000 posts with two kinds of toxicity labels: (i) annotators considered each post with the previous one as context; and (ii) annotators had no additional context. Based on this, we introduce a new task, context sensitivity estimation, which aims to identify posts whose perceived toxicity changes if the context (previous post) is also considered. We then evaluate machine learning systems on this task, showing that classifiers of practical quality can be developed, and we show that data augmentation with knowledge distillation can improve the performance further. Such systems could be used to enhance toxicity detection datasets with more context-dependent posts, or to suggest when moderators should consider the parent posts, which often may be unnecessary and may otherwise introduce significant additional cost.
Augmenting the User-Item Graph with Textual Similarity Models
Sep 20, 2021

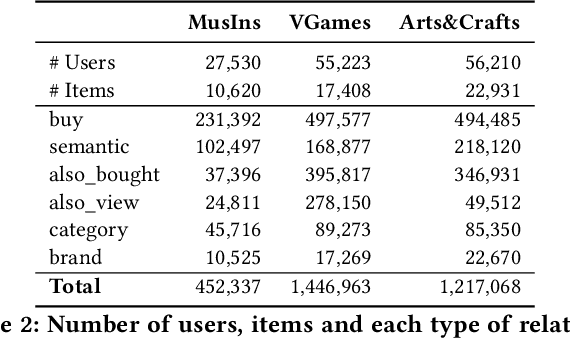
This paper introduces a simple and effective form of data augmentation for recommender systems. A paraphrase similarity model is applied to widely available textual data, such as reviews and product descriptions, yielding new semantic relations that are added to the user-item graph. This increases the density of the graph without needing further labeled data. The data augmentation is evaluated on a variety of recommendation algorithms, using Euclidean, hyperbolic, and complex spaces, and over three categories of Amazon product reviews with differing characteristics. Results show that the data augmentation technique provides significant improvements to all types of models, with the most pronounced gains for knowledge graph-based recommenders, particularly in cold-start settings, leading to state-of-the-art performance.
Civil Rephrases Of Toxic Texts With Self-Supervised Transformers
Feb 11, 2021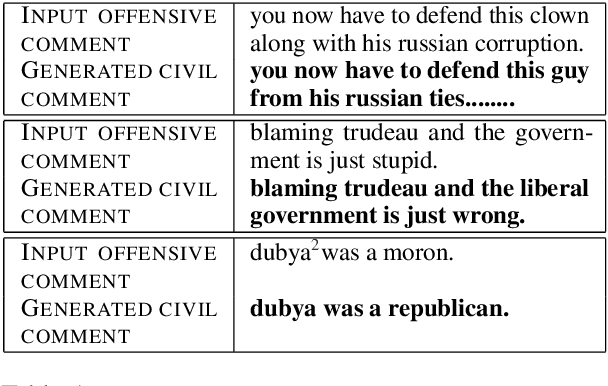
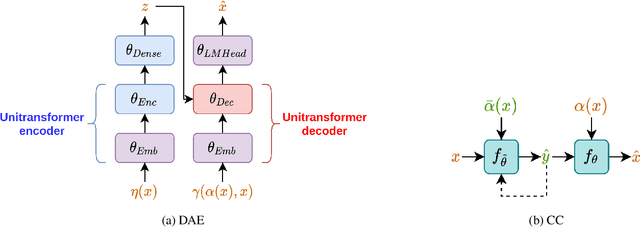
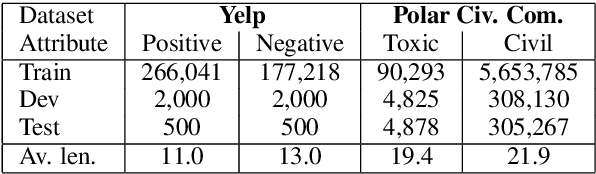
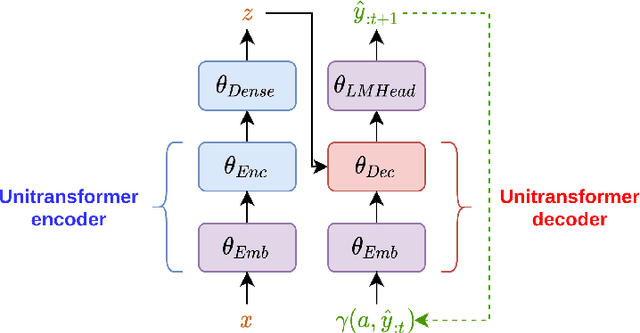
Platforms that support online commentary, from social networks to news sites, are increasingly leveraging machine learning to assist their moderation efforts. But this process does not typically provide feedback to the author that would help them contribute according to the community guidelines. This is prohibitively time-consuming for human moderators to do, and computational approaches are still nascent. This work focuses on models that can help suggest rephrasings of toxic comments in a more civil manner. Inspired by recent progress in unpaired sequence-to-sequence tasks, a self-supervised learning model is introduced, called CAE-T5. CAE-T5 employs a pre-trained text-to-text transformer, which is fine tuned with a denoising and cyclic auto-encoder loss. Experimenting with the largest toxicity detection dataset to date (Civil Comments) our model generates sentences that are more fluent and better at preserving the initial content compared to earlier text style transfer systems which we compare with using several scoring systems and human evaluation.
Six Attributes of Unhealthy Conversation
Oct 14, 2020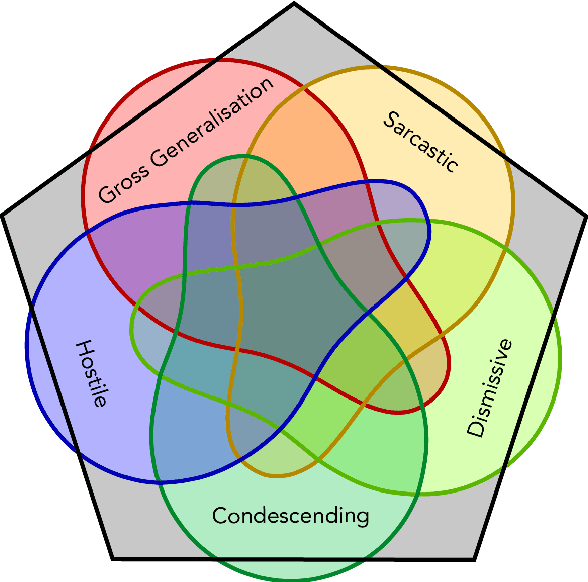
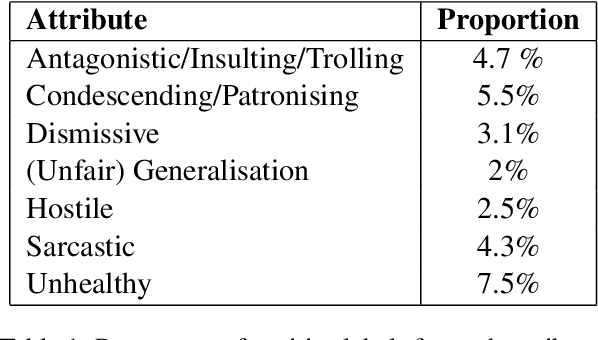
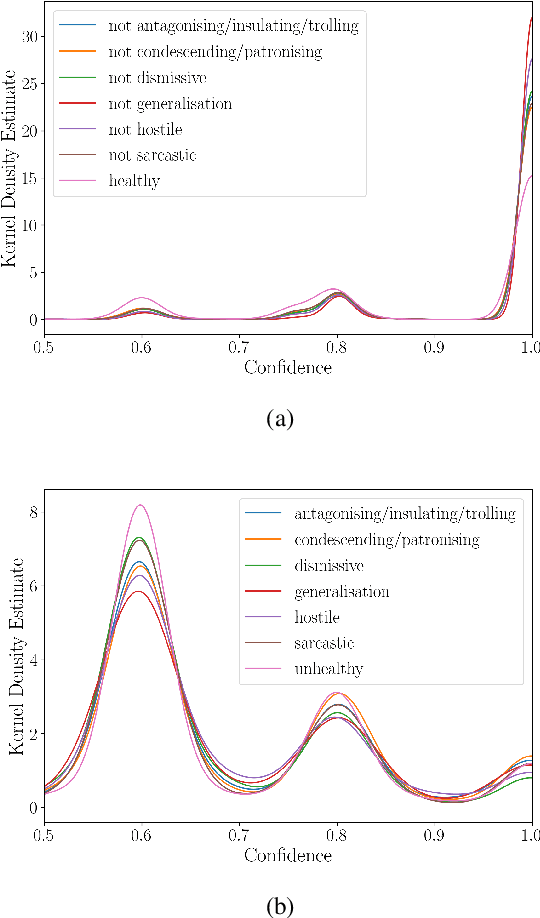

We present a new dataset of approximately 44000 comments labeled by crowdworkers. Each comment is labelled as either 'healthy' or 'unhealthy', in addition to binary labels for the presence of six potentially 'unhealthy' sub-attributes: (1) hostile; (2) antagonistic, insulting, provocative or trolling; (3) dismissive; (4) condescending or patronising; (5) sarcastic; and/or (6) an unfair generalisation. Each label also has an associated confidence score. We argue that there is a need for datasets which enable research based on a broad notion of 'unhealthy online conversation'. We build this typology to encompass a substantial proportion of the individual comments which contribute to unhealthy online conversation. For some of these attributes, this is the first publicly available dataset of this scale. We explore the quality of the dataset, present some summary statistics and initial models to illustrate the utility of this data, and highlight limitations and directions for further research.
Toxicity Detection: Does Context Really Matter?
Jun 01, 2020
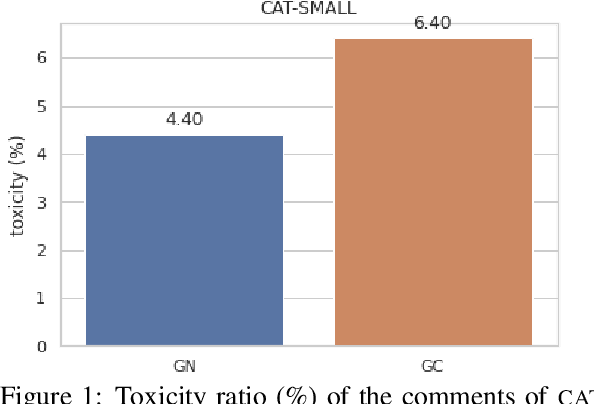

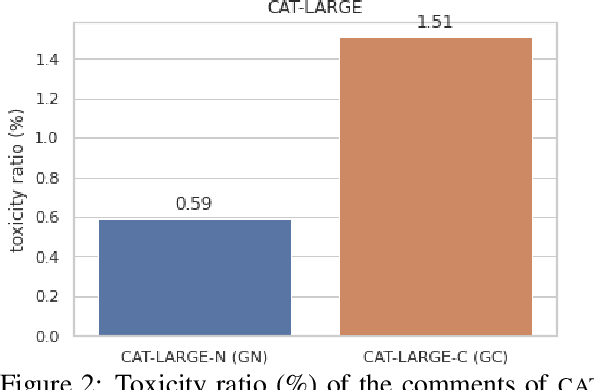
Moderation is crucial to promoting healthy on-line discussions. Although several `toxicity' detection datasets and models have been published, most of them ignore the context of the posts, implicitly assuming that comments maybe judged independently. We investigate this assumption by focusing on two questions: (a) does context affect the human judgement, and (b) does conditioning on context improve performance of toxicity detection systems? We experiment with Wikipedia conversations, limiting the notion of context to the previous post in the thread and the discussion title. We find that context can both amplify or mitigate the perceived toxicity of posts. Moreover, a small but significant subset of manually labeled posts (5% in one of our experiments) end up having the opposite toxicity labels if the annotators are not provided with context. Surprisingly, we also find no evidence that context actually improves the performance of toxicity classifiers, having tried a range of classifiers and mechanisms to make them context aware. This points to the need for larger datasets of comments annotated in context. We make our code and data publicly available.