 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Parallelization of 5G-PUSCH on a Scalable RISC-V Many-core Processor
Oct 17, 2022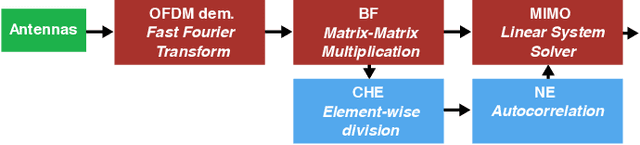
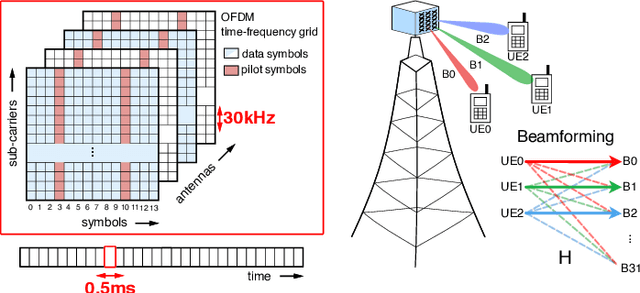
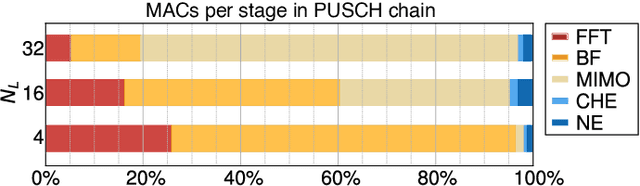
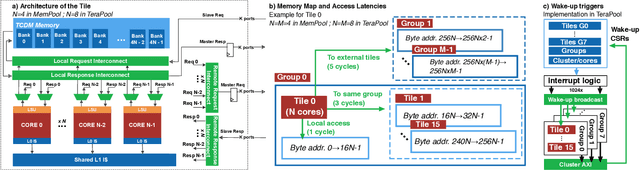
5G Radio access network disaggregation and softwarization pose challenges in terms of computational performance to the processing units. At the physical layer level, the baseband processing computational effort is typically offloaded to specialized hardware accelerators. However, the trend toward software-defined radio-access networks demands flexible, programmable architectures. In this paper, we explore the software design, parallelization and optimization of the key kernels of the lower physical layer (PHY) for physical uplink shared channel (PUSCH) reception on MemPool and TeraPool, two manycore systems having respectively 256 and 1024 small and efficient RISC-V cores with a large shared L1 data memory. PUSCH processing is demanding and strictly time-constrained, it represents a challenge for the baseband processors, and it is also common to most of the uplink channels. Our analysis thus generalizes to the entire lower PHY of the uplink receiver at gNodeB (gNB). Based on the evaluation of the computational effort (in multiply-accumulate operations) required by the PUSCH algorithmic stages, we focus on the parallel implementation of the dominant kernels, namely fast Fourier transform, matrix-matrix multiplication, and matrix decomposition kernels for the solution of linear systems. Our optimized parallel kernels achieve respectively on MemPool and TeraPool speedups of 211, 225, 158, and 762, 880, 722, at high utilization (0.81, 0.89, 0.71, and 0.74, 0.88, 0.71), comparable a single-core serial execution, moving a step closer toward a full-software PUSCH implementation.
An Energy-Efficient Spiking Neural Network for Finger Velocity Decoding for Implantable Brain-Machine Interface
Oct 07, 2022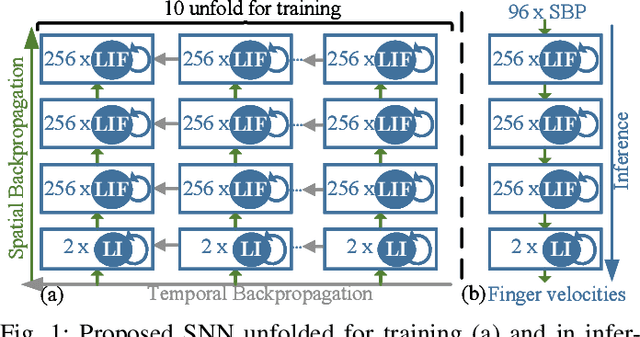
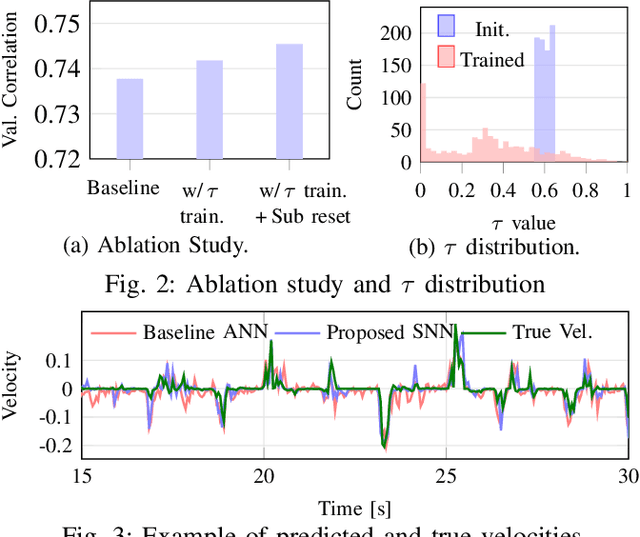
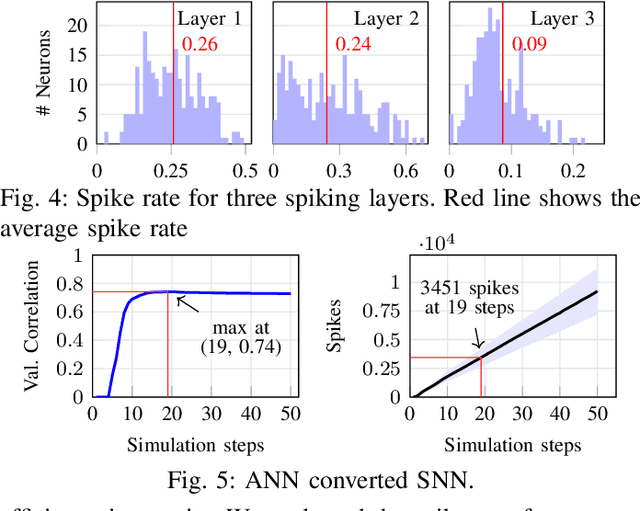
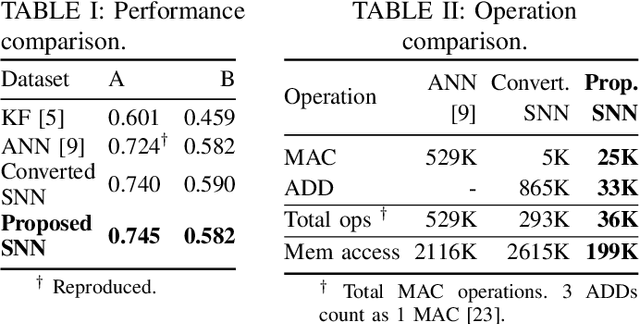
Brain-machine interfaces (BMIs) are promising for motor rehabilitation and mobility augmentation. High-accuracy and low-power algorithms are required to achieve implantable BMI systems. In this paper, we propose a novel spiking neural network (SNN) decoder for implantable BMI regression tasks. The SNN is trained with enhanced spatio-temporal backpropagation to fully leverage its ability in handling temporal problems. The proposed SNN decoder achieves the same level of correlation coefficient as the state-of-the-art ANN decoder in offline finger velocity decoding tasks, while it requires only 6.8% of the computation operations and 9.4% of the memory access.
RUAD: unsupervised anomaly detection in HPC systems
Aug 28, 2022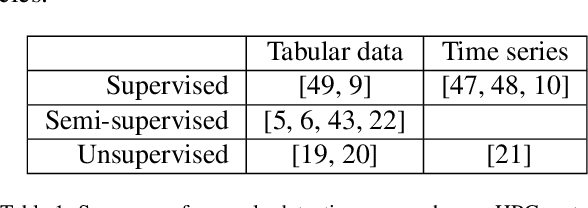
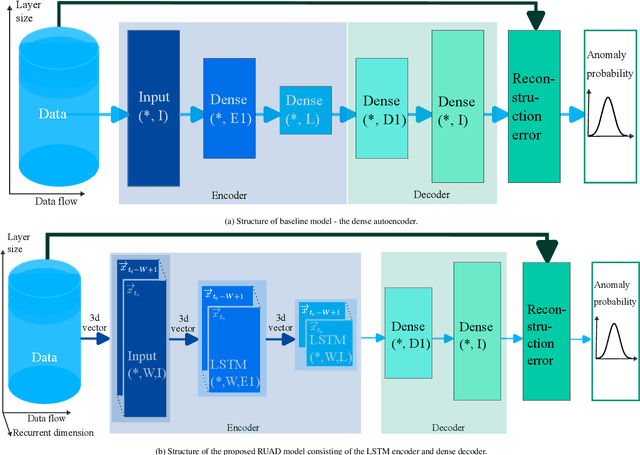


The increasing complexity of modern high-performance computing (HPC) systems necessitates the introduction of automated and data-driven methodologies to support system administrators' effort toward increasing the system's availability. Anomaly detection is an integral part of improving the availability as it eases the system administrator's burden and reduces the time between an anomaly and its resolution. However, current state-of-the-art (SoA) approaches to anomaly detection are supervised and semi-supervised, so they require a human-labelled dataset with anomalies - this is often impractical to collect in production HPC systems. Unsupervised anomaly detection approaches based on clustering, aimed at alleviating the need for accurate anomaly data, have so far shown poor performance. In this work, we overcome these limitations by proposing RUAD, a novel Recurrent Unsupervised Anomaly Detection model. RUAD achieves better results than the current semi-supervised and unsupervised SoA approaches. This is achieved by considering temporal dependencies in the data and including long-short term memory cells in the model architecture. The proposed approach is assessed on a complete ten-month history of a Tier-0 system (Marconi100 from CINECA with 980 nodes). RUAD achieves an area under the curve (AUC) of 0.763 in semi-supervised training and an AUC of 0.767 in unsupervised training, which improves upon the SoA approach that achieves an AUC of 0.747 in semi-supervised training and an AUC of 0.734 in unsupervised training. It also vastly outperforms the current SoA unsupervised anomaly detection approach based on clustering, achieving the AUC of 0.548.
Robust and Efficient Depth-based Obstacle Avoidance for Autonomous Miniaturized UAVs
Aug 26, 2022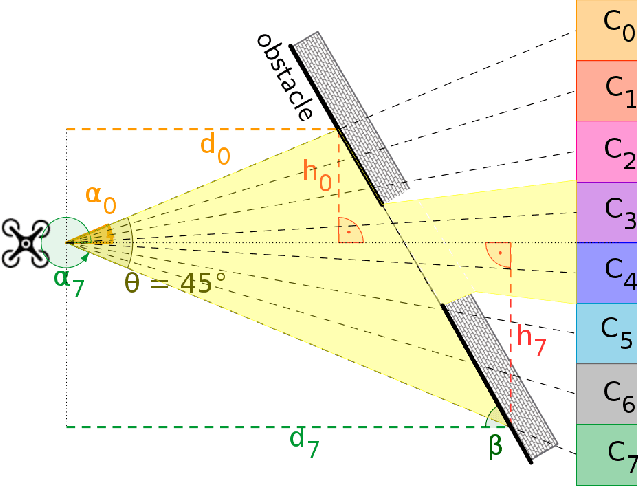
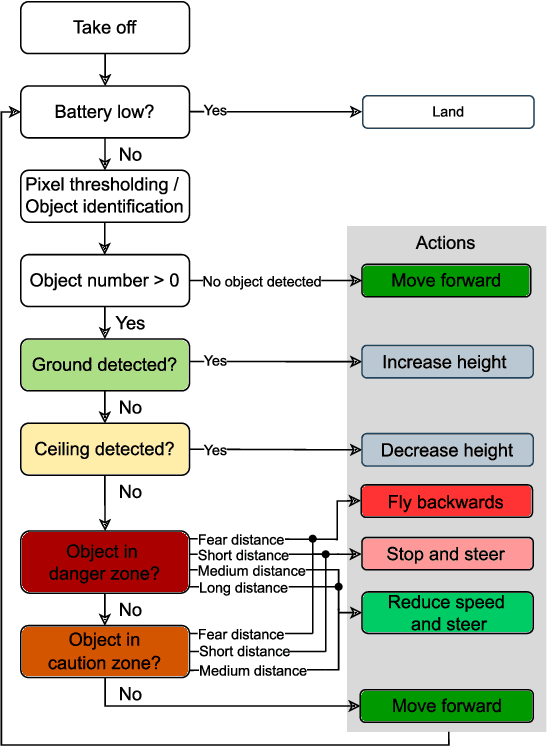
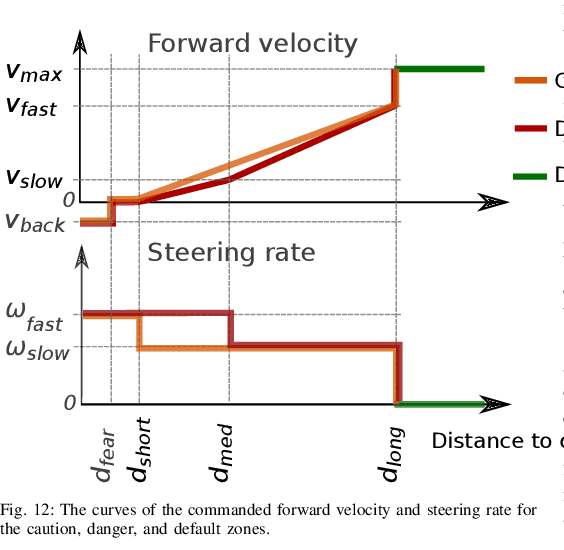
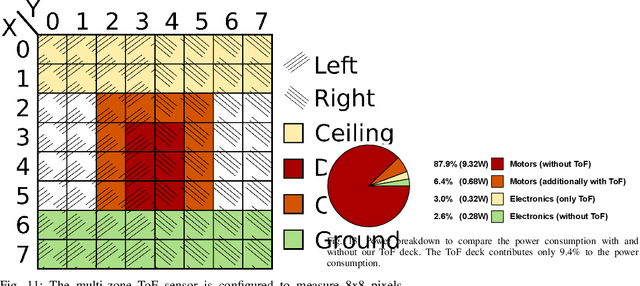
Nano-size drones hold enormous potential to explore unknown and complex environments. Their small size makes them agile and safe for operation close to humans and allows them to navigate through narrow spaces. However, their tiny size and payload restrict the possibilities for on-board computation and sensing, making fully autonomous flight extremely challenging. The first step towards full autonomy is reliable obstacle avoidance, which has proven to be technically challenging by itself in a generic indoor environment. Current approaches utilize vision-based or 1-dimensional sensors to support nano-drone perception algorithms. This work presents a lightweight obstacle avoidance system based on a novel millimeter form factor 64 pixels multi-zone Time-of-Flight (ToF) sensor and a generalized model-free control policy. Reported in-field tests are based on the Crazyflie 2.1, extended by a custom multi-zone ToF deck, featuring a total flight mass of 35g. The algorithm only uses 0.3% of the on-board processing power (210uS execution time) with a frame rate of 15fps, providing an excellent foundation for many future applications. Less than 10% of the total drone power is needed to operate the proposed perception system, including both lifting and operating the sensor. The presented autonomous nano-size drone reaches 100% reliability at 0.5m/s in a generic and previously unexplored indoor environment. The proposed system is released open-source with an extensive dataset including ToF and gray-scale camera data, coupled with UAV position ground truth from motion capture.
In-memory Realization of In-situ Few-shot Continual Learning with a Dynamically Evolving Explicit Memory
Jul 14, 2022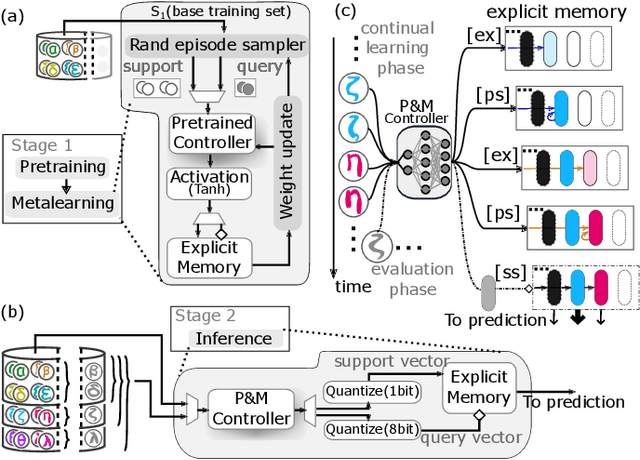
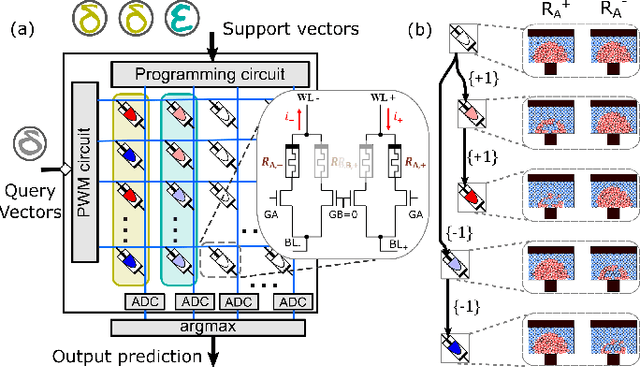
Continually learning new classes from a few training examples without forgetting previous old classes demands a flexible architecture with an inevitably growing portion of storage, in which new examples and classes can be incrementally stored and efficiently retrieved. One viable architectural solution is to tightly couple a stationary deep neural network to a dynamically evolving explicit memory (EM). As the centerpiece of this architecture, we propose an EM unit that leverages energy-efficient in-memory compute (IMC) cores during the course of continual learning operations. We demonstrate for the first time how the EM unit can physically superpose multiple training examples, expand to accommodate unseen classes, and perform similarity search during inference, using operations on an IMC core based on phase-change memory (PCM). Specifically, the physical superposition of a few encoded training examples is realized via in-situ progressive crystallization of PCM devices. The classification accuracy achieved on the IMC core remains within a range of 1.28%--2.5% compared to that of the state-of-the-art full-precision baseline software model on both the CIFAR-100 and miniImageNet datasets when continually learning 40 novel classes (from only five examples per class) on top of 60 old classes.
Channel-wise Mixed-precision Assignment for DNN Inference on Constrained Edge Nodes
Jun 17, 2022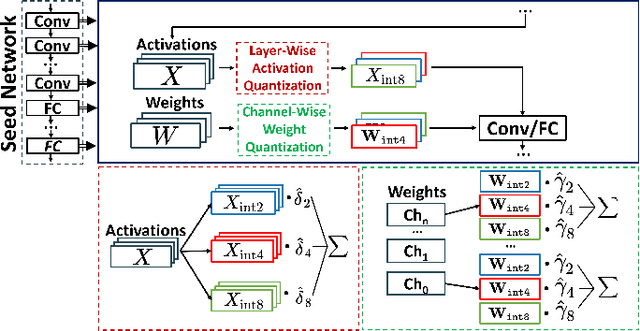
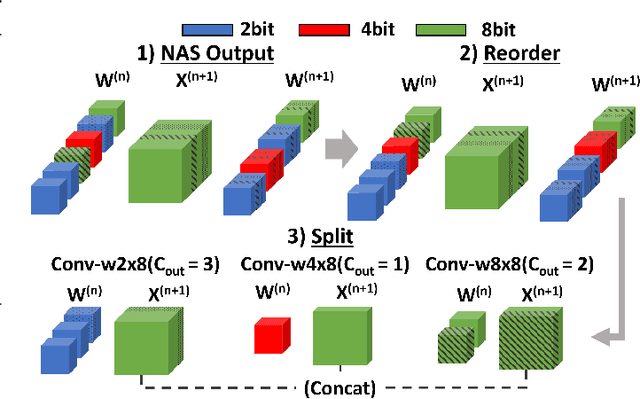
Quantization is widely employed in both cloud and edge systems to reduce the memory occupation, latency, and energy consumption of deep neural networks. In particular, mixed-precision quantization, i.e., the use of different bit-widths for different portions of the network, has been shown to provide excellent efficiency gains with limited accuracy drops, especially with optimized bit-width assignments determined by automated Neural Architecture Search (NAS) tools. State-of-the-art mixed-precision works layer-wise, i.e., it uses different bit-widths for the weights and activations tensors of each network layer. In this work, we widen the search space, proposing a novel NAS that selects the bit-width of each weight tensor channel independently. This gives the tool the additional flexibility of assigning a higher precision only to the weights associated with the most informative features. Testing on the MLPerf Tiny benchmark suite, we obtain a rich collection of Pareto-optimal models in the accuracy vs model size and accuracy vs energy spaces. When deployed on the MPIC RISC-V edge processor, our networks reduce the memory and energy for inference by up to 63% and 27% respectively compared to a layer-wise approach, for the same accuracy.
Multi-Complexity-Loss DNAS for Energy-Efficient and Memory-Constrained Deep Neural Networks
Jun 01, 2022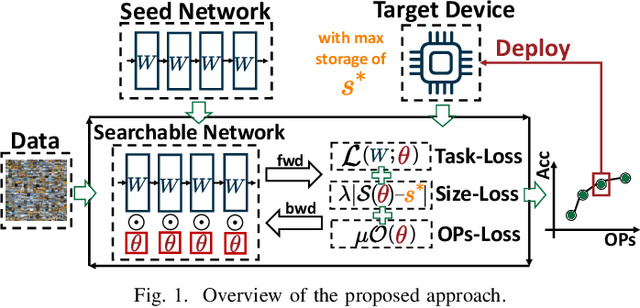
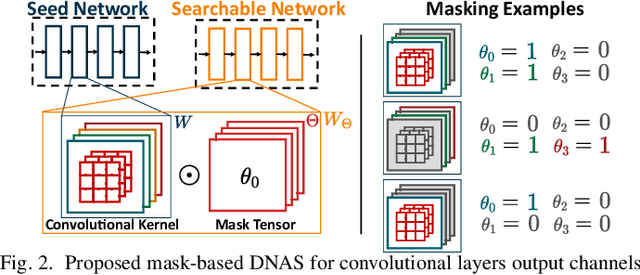
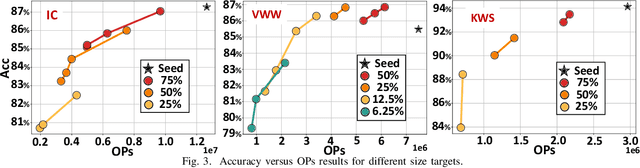
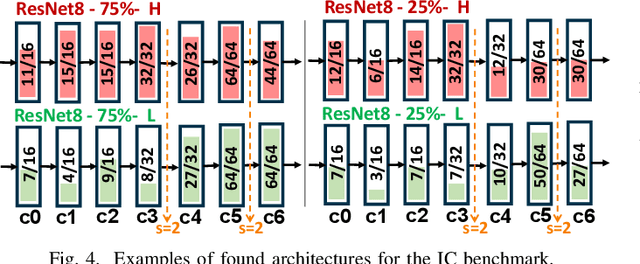
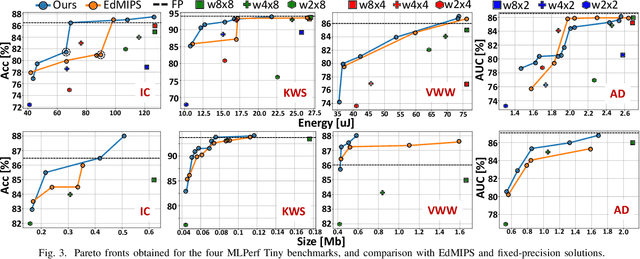
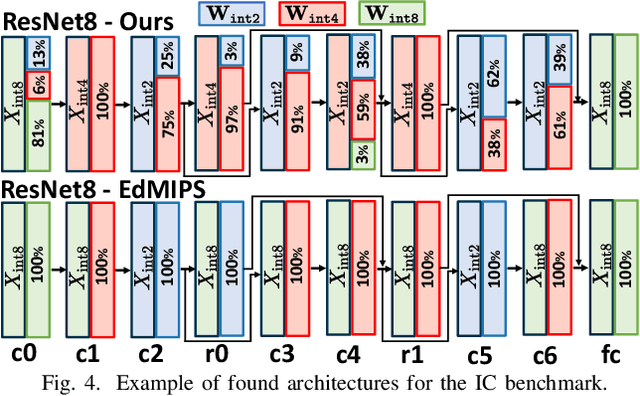
Neural Architecture Search (NAS) is increasingly popular to automatically explore the accuracy versus computational complexity trade-off of Deep Learning (DL) architectures. When targeting tiny edge devices, the main challenge for DL deployment is matching the tight memory constraints, hence most NAS algorithms consider model size as the complexity metric. Other methods reduce the energy or latency of DL models by trading off accuracy and number of inference operations. Energy and memory are rarely considered simultaneously, in particular by low-search-cost Differentiable NAS (DNAS) solutions. We overcome this limitation proposing the first DNAS that directly addresses the most realistic scenario from a designer's perspective: the co-optimization of accuracy and energy (or latency) under a memory constraint, determined by the target HW. We do so by combining two complexity-dependent loss functions during training, with independent strength. Testing on three edge-relevant tasks from the MLPerf Tiny benchmark suite, we obtain rich Pareto sets of architectures in the energy vs. accuracy space, with memory footprints constraints spanning from 75% to 6.25% of the baseline networks. When deployed on a commercial edge device, the STM NUCLEO-H743ZI2, our networks span a range of 2.18x in energy consumption and 4.04% in accuracy for the same memory constraint, and reduce energy by up to 2.2x with negligible accuracy drop with respect to the baseline.
Adaptive Random Forests for Energy-Efficient Inference on Microcontrollers
May 27, 2022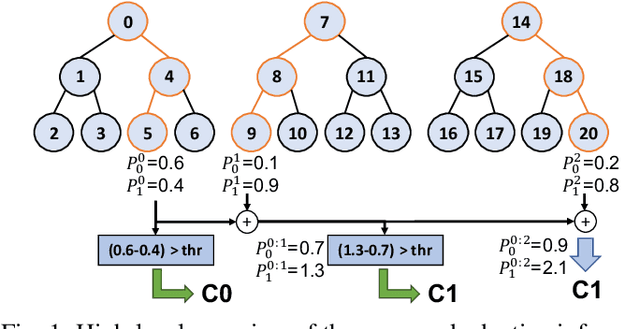
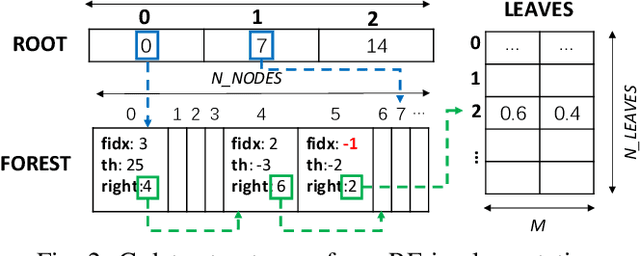
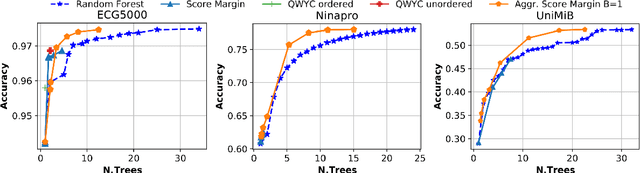
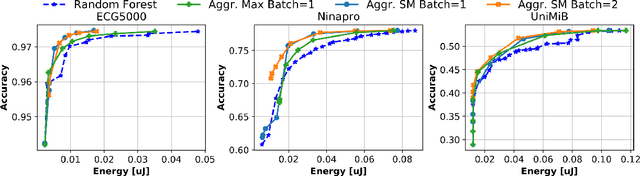
Random Forests (RFs) are widely used Machine Learning models in low-power embedded devices, due to their hardware friendly operation and high accuracy on practically relevant tasks. The accuracy of a RF often increases with the number of internal weak learners (decision trees), but at the cost of a proportional increase in inference latency and energy consumption. Such costs can be mitigated considering that, in most applications, inputs are not all equally difficult to classify. Therefore, a large RF is often necessary only for (few) hard inputs, and wasteful for easier ones. In this work, we propose an early-stopping mechanism for RFs, which terminates the inference as soon as a high-enough classification confidence is reached, reducing the number of weak learners executed for easy inputs. The early-stopping confidence threshold can be controlled at runtime, in order to favor either energy saving or accuracy. We apply our method to three different embedded classification tasks, on a single-core RISC-V microcontroller, achieving an energy reduction from 38% to more than 90% with a drop of less than 0.5% in accuracy. We also show that our approach outperforms previous adaptive ML methods for RFs.
* Published in: 2021 IFIP/IEEE 29th International Conference on Very Large Scale Integration (VLSI-SoC), 2021
On-Demand Redundancy Grouping: Selectable Soft-Error Tolerance for a Multicore Cluster
May 25, 2022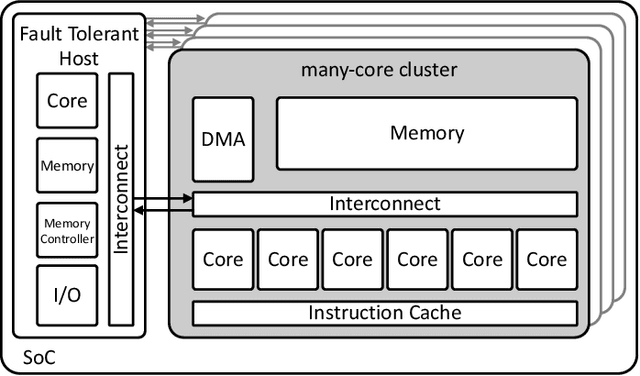
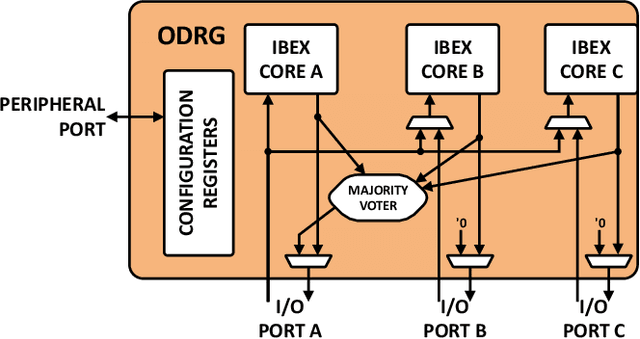
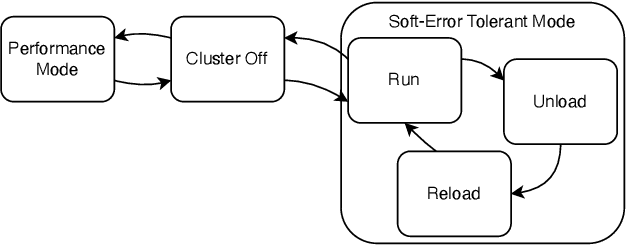
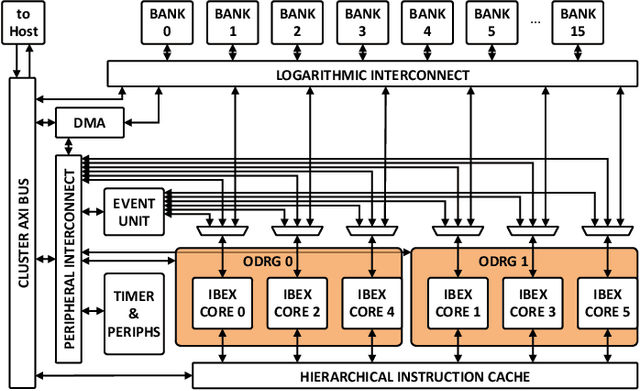
With the shrinking of technology nodes and the use of parallel processor clusters in hostile and critical environments, such as space, run-time faults caused by radiation are a serious cross-cutting concern, also impacting architectural design. This paper introduces an architectural approach to run-time configurable soft-error tolerance at the core level, augmenting a six-core open-source RISC-V cluster with a novel On-Demand Redundancy Grouping (ODRG) scheme. ODRG allows the cluster to operate either as two fault-tolerant cores, or six individual cores for high-performance, with limited overhead to switch between these modes during run-time. The ODRG unit adds less than 11% of a core's area for a three-core group, or a total of 1% of the cluster area, and shows negligible timing increase, which compares favorably to a commercial state-of-the-art implementation, and is 2.5$\times$ faster in fault recovery re-synchronization. Furthermore, unlike other implementations, when redundancy is not necessary, the ODRG approach allows the redundant cores to be used for independent computation, allowing up to 2.96$\times$ increase in performance for selected applications.
Reducing Neural Architecture Search Spaces with Training-Free Statistics and Computational Graph Clustering
Apr 29, 2022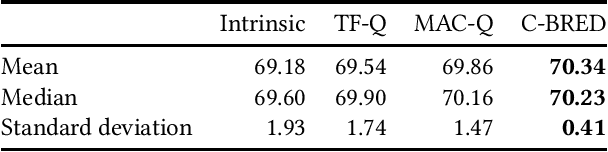
The computational demands of neural architecture search (NAS) algorithms are usually directly proportional to the size of their target search spaces. Thus, limiting the search to high-quality subsets can greatly reduce the computational load of NAS algorithms. In this paper, we present Clustering-Based REDuction (C-BRED), a new technique to reduce the size of NAS search spaces. C-BRED reduces a NAS space by clustering the computational graphs associated with its architectures and selecting the most promising cluster using proxy statistics correlated with network accuracy. When considering the NAS-Bench-201 (NB201) data set and the CIFAR-100 task, C-BRED selects a subset with 70% average accuracy instead of the whole space's 64% average accuracy.