 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Design Space Exploration for optimised Deployment of DNN on Arm Cortex-A CPUs
Paper and Code
Jun 09, 2020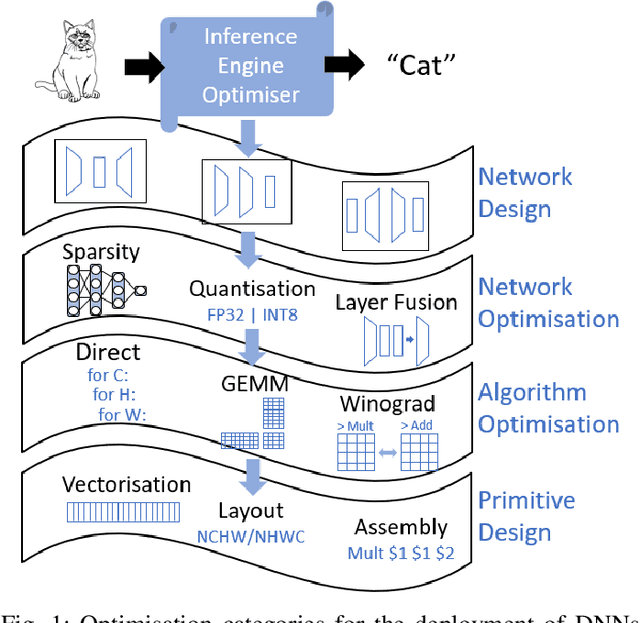
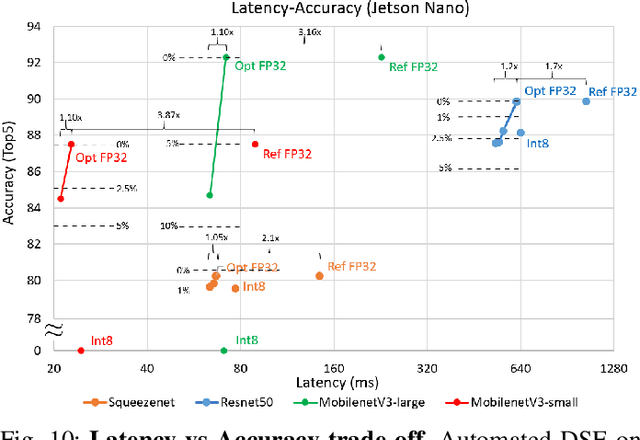
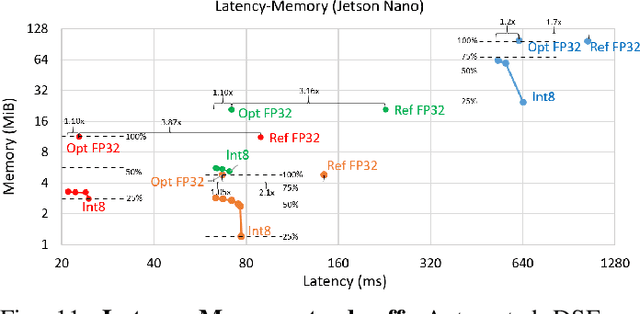
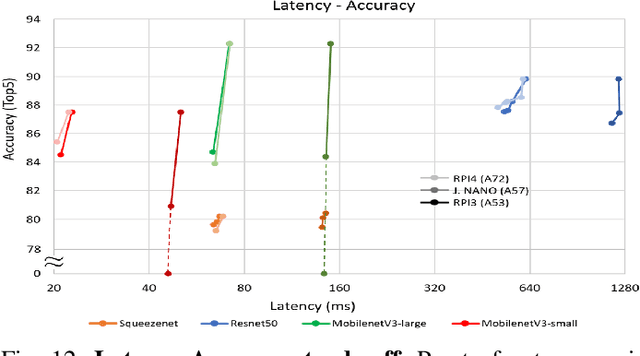
The spread of deep learning on embedded devices has prompted the development of numerous methods to optimise the deployment of deep neural networks (DNN). Works have mainly focused on: i) efficient DNN architectures, ii) network optimisation techniques such as pruning and quantisation, iii) optimised algorithms to speed up the execution of the most computational intensive layers and, iv) dedicated hardware to accelerate the data flow and computation. However, there is a lack of research on the combination of these methods as the space of approaches becomes too large to test and obtain a globally optimised solution, which leads to suboptimal deployment in terms of latency, accuracy, and memory. In this work, we first detail and analyse the methods to improve the deployment of DNNs across the different levels of software optimisation. Building on this knowledge, we present an automated exploration framework to ease the deployment of DNNs for industrial applications by automatically exploring the design space and learning an optimised solution that speeds up the performance and reduces the memory on embedded CPU platforms. The framework relies on a Reinforcement Learning -based search that, combined with a deep learning inference framework, enables the deployment of DNN implementations to obtain empirical measurements on embedded AI applications. Thus, we present a set of results for state-of-the-art DNNs on a range of Arm Cortex-A CPU platforms achieving up to 4x improvement in performance and over 2x reduction in memory with negligible loss in accuracy with respect to the BLAS floating-point implementation.