 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2026 Challenge on Single Image Reflection Removal in the Wild: Datasets, Results, and Methods
Apr 11, 2026In this paper, we review the NTIRE 2026 challenge on single-image reflection removal (SIRR) in the Wild. SIRR is a fundamental task in image restoration. Despite progress in academic research, most methods are tested on synthetic images or limited real-world images, creating a gap in real-world applications. In this challenge, we provide participants with the OpenRR-5k dataset, which requires them to process real-world images that cover a range of reflection scenarios and intensities, with the goal of generating clean images without reflections. The challenge attracted more than 100 registrations, with 11 of them participating in the final testing phase. The top-ranked methods advanced the state-of-the-art reflection removal performance and earned unanimous recognition from the five experts in the field. The proposed OpenRR-5k dataset is available at https://huggingface.co/datasets/qiuzhangTiTi/OpenRR-5k, and the homepage of this challenge is at https://github.com/caijie0620/OpenRR-5k. Due to page limitations, this article only presents partial content; the full report and detailed analyses are available in the extended arXiv version.
NTIRE 2025 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 20, 2025This paper presents the NTIRE 2025 image super-resolution ($\times$4) challenge, one of the associated competitions of the 10th NTIRE Workshop at CVPR 2025. The challenge aims to recover high-resolution (HR) images from low-resolution (LR) counterparts generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective network designs or solutions that achieve state-of-the-art SR performance. To reflect the dual objectives of image SR research, the challenge includes two sub-tracks: (1) a restoration track, emphasizes pixel-wise accuracy and ranks submissions based on PSNR; (2) a perceptual track, focuses on visual realism and ranks results by a perceptual score. A total of 286 participants registered for the competition, with 25 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, the main results, and methods of each team. The challenge serves as a benchmark to advance the state of the art and foster progress in image SR.
STN: Scalable Tensorizing Networks via Structure-Aware Training and Adaptive Compression
May 30, 2022
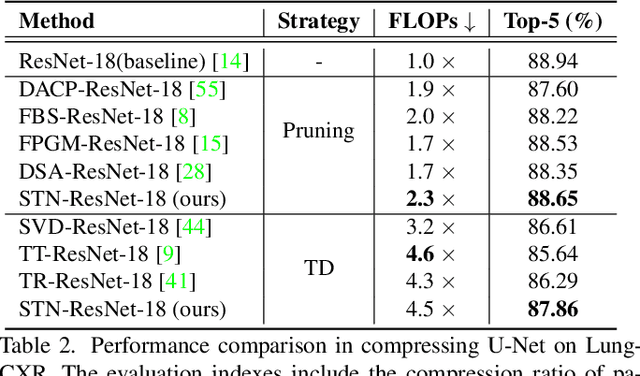


Deep neural networks (DNNs) have delivered a remarkable performance in many tasks of computer vision. However, over-parameterized representations of popular architectures dramatically increase their computational complexity and storage costs, and hinder their availability in edge devices with constrained resources. Regardless of many tensor decomposition (TD) methods that have been well-studied for compressing DNNs to learn compact representations, they suffer from non-negligible performance degradation in practice. In this paper, we propose Scalable Tensorizing Networks (STN), which dynamically and adaptively adjust the model size and decomposition structure without retraining. First, we account for compression during training by adding a low-rank regularizer to guarantee networks' desired low-rank characteristics in full tensor format. Then, considering network layers exhibit various low-rank structures, STN is obtained by a data-driven adaptive TD approach, for which the topological structure of decomposition per layer is learned from the pre-trained model, and the ranks are selected appropriately under specified storage constraints. As a result, STN is compatible with arbitrary network architectures and achieves higher compression performance and flexibility over other tensorizing versions. Comprehensive experiments on several popular architectures and benchmarks substantiate the superiority of our model towards improving parameter efficiency.