 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Risk Minimization for High-Dimensional Treatments
May 26, 2026Predicting the effect of interventions with many possible variations, e.g., therapeutic content that affects mental health outcomes or an earnings call transcript that drives movement in share price, is useful across several domains. However, classical causal estimators tend to assume that all possible interventions are observed, which is infeasible when interventions vary widely, for instance, in the space of all text strings. We adapt a well-known approach of recasting causal inference as a learning problem, to address high-dimensional treatment spaces. Specifically, under standard assumptions like no unobserved confounding, we show that causal error decomposes into a series of moment-balancing errors of increasing order, and design objectives that directly improve causal estimation. We also show how to project the effect of a high-dimensional treatment onto lower-dimensional treatment attributes, which allows a single model to answer several causal questions without additional attribute-specific training. We empirically evaluate our estimators in settings with high-dimensional continuous, discrete, and text treatments, the last of which used a semi-synthetic dataset of Amazon Reviews. Our experiments demonstrate the benefit of higher-order balance error optimization and competitive performance of projected causal estimates with attribute-specific estimators.
De Jure: Iterative LLM Self-Refinement for Structured Extraction of Regulatory Rules
Apr 02, 2026Regulatory documents encode legally binding obligations that LLM-based systems must respect. Yet converting dense, hierarchically structured legal text into machine-readable rules remains a costly, expert-intensive process. We present De Jure, a fully automated, domain-agnostic pipeline for extracting structured regulatory rules from raw documents, requiring no human annotation, domain-specific prompting, or annotated gold data. De Jure operates through four sequential stages: normalization of source documents into structured Markdown; LLM-driven semantic decomposition into structured rule units; multi-criteria LLM-as-a-judge evaluation across 19 dimensions spanning metadata, definitions, and rule semantics; and iterative repair of low-scoring extractions within a bounded regeneration budget, where upstream components are repaired before rule units are evaluated. We evaluate De Jure across four models on three regulatory corpora spanning finance, healthcare, and AI governance. On the finance domain, De Jure yields consistent and monotonic improvement in extraction quality, reaching peak performance within three judge-guided iterations. De Jure generalizes effectively to healthcare and AI governance, maintaining high performance across both open- and closed-source models. In a downstream compliance question-answering evaluation via RAG, responses grounded in De Jure extracted rules are preferred over prior work in 73.8% of cases at single-rule retrieval depth, rising to 84.0% under broader retrieval, confirming that extraction fidelity translates directly into downstream utility. These results demonstrate that explicit, interpretable evaluation criteria can substitute for human annotation in complex regulatory domains, offering a scalable and auditable path toward regulation-grounded LLM alignment.
Adapting Natural Language Processing Models Across Jurisdictions: A pilot Study in Canadian Cancer Registries
Jan 02, 2026Population-based cancer registries depend on pathology reports as their primary diagnostic source, yet manual abstraction is resource-intensive and contributes to delays in cancer data. While transformer-based NLP systems have improved registry workflows, their ability to generalize across jurisdictions with differing reporting conventions remains poorly understood. We present the first cross-provincial evaluation of adapting BCCRTron, a domain-adapted transformer model developed at the British Columbia Cancer Registry, alongside GatorTron, a biomedical transformer model, for cancer surveillance in Canada. Our training dataset consisted of approximately 104,000 and 22,000 de-identified pathology reports from the Newfoundland & Labrador Cancer Registry (NLCR) for Tier 1 (cancer vs. non-cancer) and Tier 2 (reportable vs. non-reportable) tasks, respectively. Both models were fine-tuned using complementary synoptic and diagnosis focused report section input pipelines. Across NLCR test sets, the adapted models maintained high performance, demonstrating transformers pretrained in one jurisdiction can be localized to another with modest fine-tuning. To improve sensitivity, we combined the two models using a conservative OR-ensemble achieving a Tier 1 recall of 0.99 and reduced missed cancers to 24, compared with 48 and 54 for the standalone models. For Tier 2, the ensemble achieved 0.99 recall and reduced missed reportable cancers to 33, compared with 54 and 46 for the individual models. These findings demonstrate that an ensemble combining complementary text representations substantially reduce missed cancers and improve error coverage in cancer-registry NLP. We implement a privacy-preserving workflow in which only model weights are shared between provinces, supporting interoperable NLP infrastructure and a future pan-Canadian foundation model for cancer pathology and registry workflows.
Small or Large? Zero-Shot or Finetuned? Guiding Language Model Choice for Specialized Applications in Healthcare
Apr 29, 2025
This study aims to guide language model selection by investigating: 1) the necessity of finetuning versus zero-shot usage, 2) the benefits of domain-adjacent versus generic pretrained models, 3) the value of further domain-specific pretraining, and 4) the continued relevance of Small Language Models (SLMs) compared to Large Language Models (LLMs) for specific tasks. Using electronic pathology reports from the British Columbia Cancer Registry (BCCR), three classification scenarios with varying difficulty and data size are evaluated. Models include various SLMs and an LLM. SLMs are evaluated both zero-shot and finetuned; the LLM is evaluated zero-shot only. Finetuning significantly improved SLM performance across all scenarios compared to their zero-shot results. The zero-shot LLM outperformed zero-shot SLMs but was consistently outperformed by finetuned SLMs. Domain-adjacent SLMs generally performed better than the generic SLM after finetuning, especially on harder tasks. Further domain-specific pretraining yielded modest gains on easier tasks but significant improvements on the complex, data-scarce task. The results highlight the critical role of finetuning for SLMs in specialized domains, enabling them to surpass zero-shot LLM performance on targeted classification tasks. Pretraining on domain-adjacent or domain-specific data provides further advantages, particularly for complex problems or limited finetuning data. While LLMs offer strong zero-shot capabilities, their performance on these specific tasks did not match that of appropriately finetuned SLMs. In the era of LLMs, SLMs remain relevant and effective, offering a potentially superior performance-resource trade-off compared to LLMs.
Leveraging Language Models for Automated Patient Record Linkage
Apr 21, 2025



Objective: Healthcare data fragmentation presents a major challenge for linking patient data, necessitating robust record linkage to integrate patient records from diverse sources. This study investigates the feasibility of leveraging language models for automated patient record linkage, focusing on two key tasks: blocking and matching. Materials and Methods: We utilized real-world healthcare data from the Missouri Cancer Registry and Research Center, linking patient records from two independent sources using probabilistic linkage as a baseline. A transformer-based model, RoBERTa, was fine-tuned for blocking using sentence embeddings. For matching, several language models were experimented under fine-tuned and zero-shot settings, assessing their performance against ground truth labels. Results: The fine-tuned blocking model achieved a 92% reduction in the number of candidate pairs while maintaining near-perfect recall. In the matching task, fine-tuned Mistral-7B achieved the best performance with only 6 incorrect predictions. Among zero-shot models, Mistral-Small-24B performed best, with a total of 55 incorrect predictions. Discussion: Fine-tuned language models achieved strong performance in patient record blocking and matching with minimal errors. However, they remain less accurate and efficient than a hybrid rule-based and probabilistic approach for blocking. Additionally, reasoning models like DeepSeek-R1 are impractical for large-scale record linkage due to high computational costs. Conclusion: This study highlights the potential of language models for automating patient record linkage, offering improved efficiency by eliminating the manual efforts required to perform patient record linkage. Overall, language models offer a scalable solution that can enhance data integration, reduce manual effort, and support disease surveillance and research.
A Clinical Trial Design Approach to Auditing Language Models in Healthcare Setting
Nov 11, 2024We present an audit mechanism for language models, with a focus on models deployed in the healthcare setting. Our proposed mechanism takes inspiration from clinical trial design where we posit the language model audit as a single blind equivalence trial, with the comparison of interest being the subject matter experts. We show that using our proposed method, we can follow principled sample size and power calculations, leading to the requirement of sampling minimum number of records while maintaining the audit integrity and statistical soundness. Finally, we provide a real-world example of the audit used in a production environment in a large-scale public health network.
Differentially Private Ensemble Classifiers for Data Streams
Dec 09, 2021



Learning from continuous data streams via classification/regression is prevalent in many domains. Adapting to evolving data characteristics (concept drift) while protecting data owners' private information is an open challenge. We present a differentially private ensemble solution to this problem with two distinguishing features: it allows an \textit{unbounded} number of ensemble updates to deal with the potentially never-ending data streams under a fixed privacy budget, and it is \textit{model agnostic}, in that it treats any pre-trained differentially private classification/regression model as a black-box. Our method outperforms competitors on real-world and simulated datasets for varying settings of privacy, concept drift, and data distribution.
The Differentially Private Lottery Ticket Mechanism
Feb 16, 2020
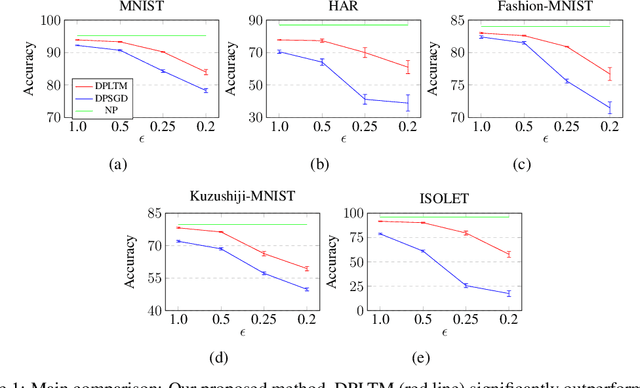
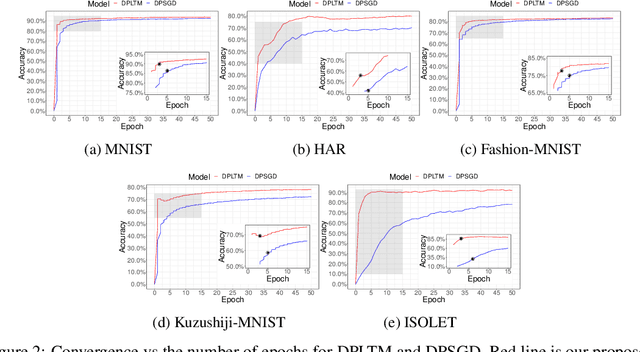
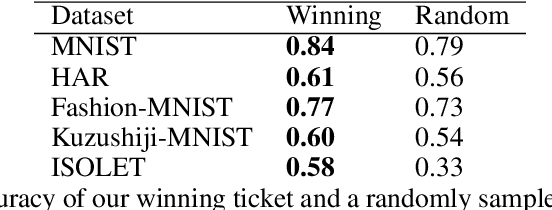
We propose the differentially private lottery ticket mechanism (DPLTM). An end-to-end differentially private training paradigm based on the lottery ticket hypothesis. Using "high-quality winners", selected via our custom score function, DPLTM significantly improves the privacy-utility trade-off over the state-of-the-art. We show that DPLTM converges faster, allowing for early stopping with reduced privacy budget consumption. We further show that the tickets from DPLTM are transferable across datasets, domains, and architectures. Our extensive evaluation on several public datasets provides evidence to our claims.
Differentially Private Survival Function Estimation
Oct 04, 2019

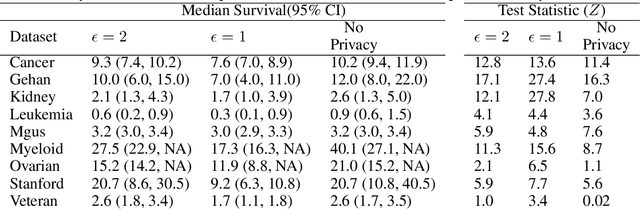

Survival function estimation is used in many disciplines, but it is most common in medical analytics in the form of the Kaplan-Meier estimator. Sensitive data (patient records) is used in the estimation without any explicit control on the information leakage, which is a significant privacy concern. We propose a first differentially private estimator of the survival function and show that it can be easily extended to provide differentially private confidence intervals and test statistics without spending any extra privacy budget. We further provide extensions for differentially private estimation of the competing risk cumulative incidence function. Using nine real-life clinical datasets, we provide empirical evidence that our proposed method provides good utility while simultaneously providing strong privacy guarantees.
CrowdMI: Multiple Imputation via Crowdsourcing
Feb 23, 2018


Can humans impute missing data with similar proficiency as machines? This is the question we aim to answer in this paper. We present a novel idea of converting observations with missing data in to a survey questionnaire, which is presented to crowdworkers for completion. We replicate a multiple imputation framework by having multiple unique crowdworkers complete our questionnaire. Experimental results demonstrate that using our method, it is possible to generate valid imputations for qualitative and quantitative missing data, with results comparable to imputations generated by complex statistical models.