 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManifold Structured Prediction
Jun 26, 2018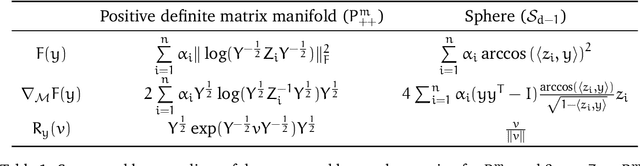

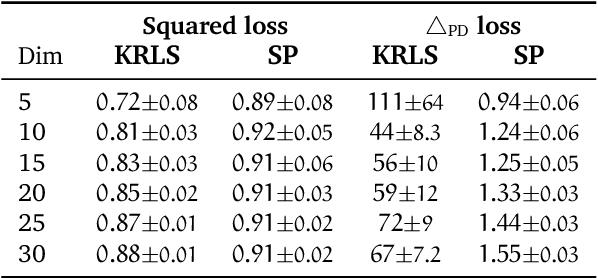
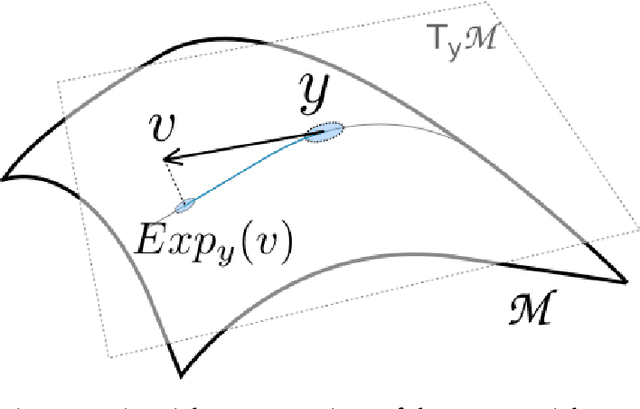
Structured prediction provides a general framework to deal with supervised problems where the outputs have semantically rich structure. While classical approaches consider finite, albeit potentially huge, output spaces, in this paper we discuss how structured prediction can be extended to a continuous scenario. Specifically, we study a structured prediction approach to manifold valued regression. We characterize a class of problems for which the considered approach is statistically consistent and study how geometric optimization can be used to compute the corresponding estimator. Promising experimental results on both simulated and real data complete our study.
Dirichlet-based Gaussian Processes for Large-scale Calibrated Classification
May 28, 2018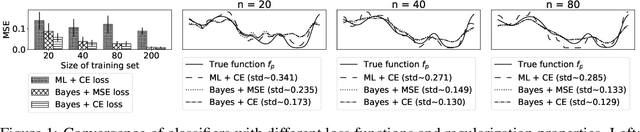
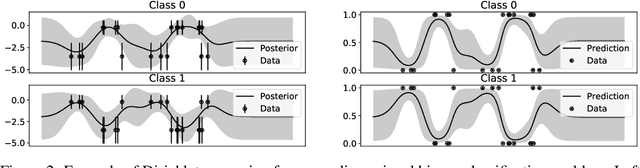
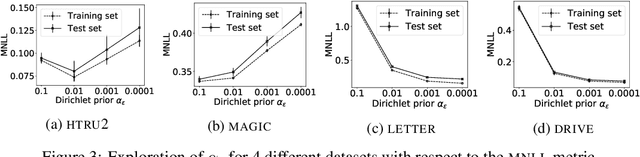
In this paper, we study the problem of deriving fast and accurate classification algorithms with uncertainty quantification. Gaussian process classification provides a principled approach, but the corresponding computational burden is hardly sustainable in large-scale problems and devising efficient alternatives is a challenge. In this work, we investigate if and how Gaussian process regression directly applied to the classification labels can be used to tackle this question. While in this case training time is remarkably faster, predictions need be calibrated for classification and uncertainty estimation. To this aim, we propose a novel approach based on interpreting the labels as the output of a Dirichlet distribution. Extensive experimental results show that the proposed approach provides essentially the same accuracy and uncertainty quantification of Gaussian process classification while requiring only a fraction of computational resources.
Generalization Properties of Doubly Stochastic Learning Algorithms
Mar 08, 2018Doubly stochastic learning algorithms are scalable kernel methods that perform very well in practice. However, their generalization properties are not well understood and their analysis is challenging since the corresponding learning sequence may not be in the hypothesis space induced by the kernel. In this paper, we provide an in-depth theoretical analysis for different variants of doubly stochastic learning algorithms within the setting of nonparametric regression in a reproducing kernel Hilbert space and considering the square loss. Particularly, we derive convergence results on the generalization error for the studied algorithms either with or without an explicit penalty term. To the best of our knowledge, the derived results for the unregularized variants are the first of this kind, while the results for the regularized variants improve those in the literature. The novelties in our proof are a sample error bound that requires controlling the trace norm of a cumulative operator, and a refined analysis of bounding initial error.
Iterate averaging as regularization for stochastic gradient descent
Feb 22, 2018We propose and analyze a variant of the classic Polyak-Ruppert averaging scheme, broadly used in stochastic gradient methods. Rather than a uniform average of the iterates, we consider a weighted average, with weights decaying in a geometric fashion. In the context of linear least squares regression, we show that this averaging scheme has a the same regularizing effect, and indeed is asymptotically equivalent, to ridge regression. In particular, we derive finite-sample bounds for the proposed approach that match the best known results for regularized stochastic gradient methods.
NYTRO: When Subsampling Meets Early Stopping
Jan 31, 2018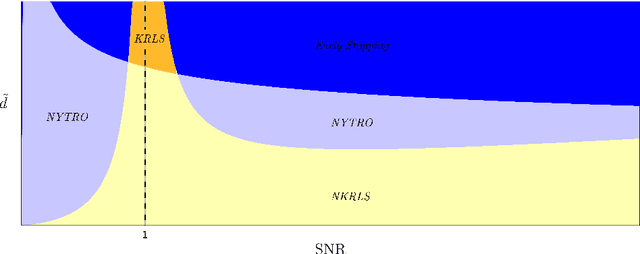
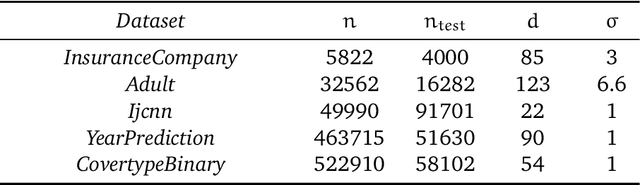
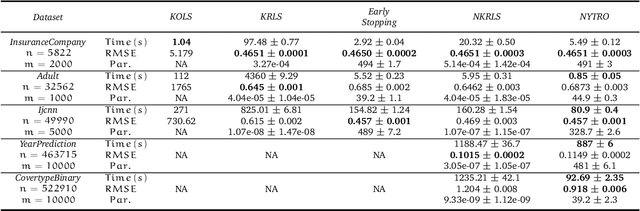
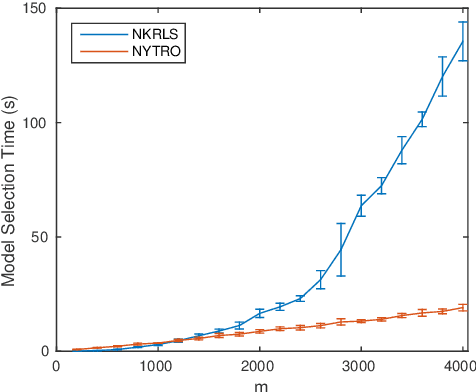
Early stopping is a well known approach to reduce the time complexity for performing training and model selection of large scale learning machines. On the other hand, memory/space (rather than time) complexity is the main constraint in many applications, and randomized subsampling techniques have been proposed to tackle this issue. In this paper we ask whether early stopping and subsampling ideas can be combined in a fruitful way. We consider the question in a least squares regression setting and propose a form of randomized iterative regularization based on early stopping and subsampling. In this context, we analyze the statistical and computational properties of the proposed method. Theoretical results are complemented and validated by a thorough experimental analysis.
FALKON: An Optimal Large Scale Kernel Method
Jan 31, 2018
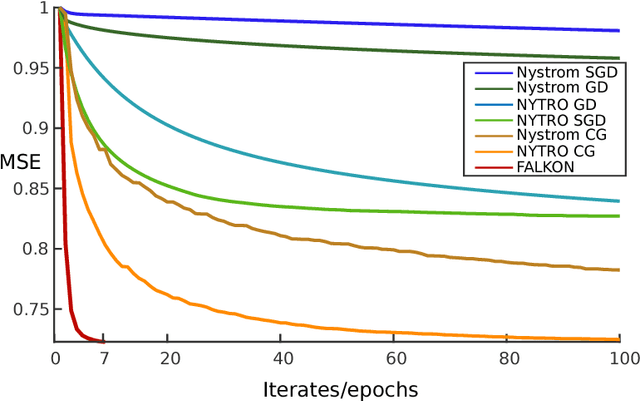
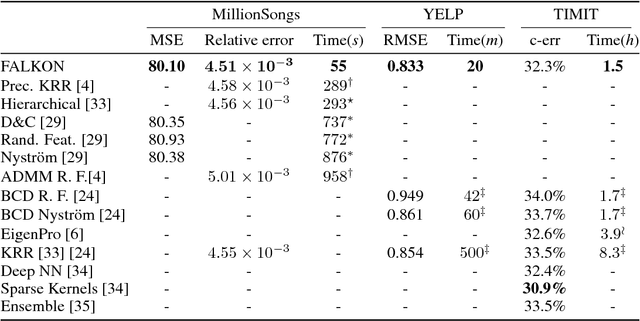
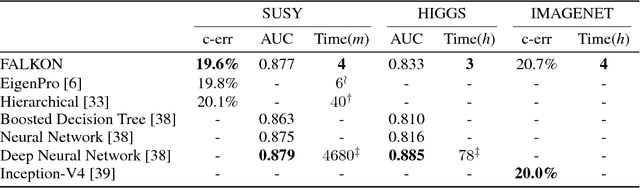
Kernel methods provide a principled way to perform non linear, nonparametric learning. They rely on solid functional analytic foundations and enjoy optimal statistical properties. However, at least in their basic form, they have limited applicability in large scale scenarios because of stringent computational requirements in terms of time and especially memory. In this paper, we take a substantial step in scaling up kernel methods, proposing FALKON, a novel algorithm that allows to efficiently process millions of points. FALKON is derived combining several algorithmic principles, namely stochastic subsampling, iterative solvers and preconditioning. Our theoretical analysis shows that optimal statistical accuracy is achieved requiring essentially $O(n)$ memory and $O(n\sqrt{n})$ time. An extensive experimental analysis on large scale datasets shows that, even with a single machine, FALKON outperforms previous state of the art solutions, which exploit parallel/distributed architectures.
Generalization Properties of Learning with Random Features
Jan 31, 2018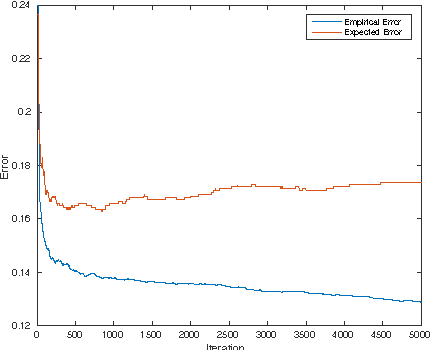

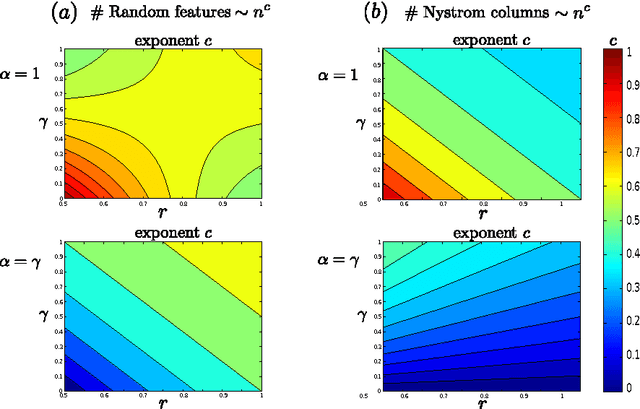
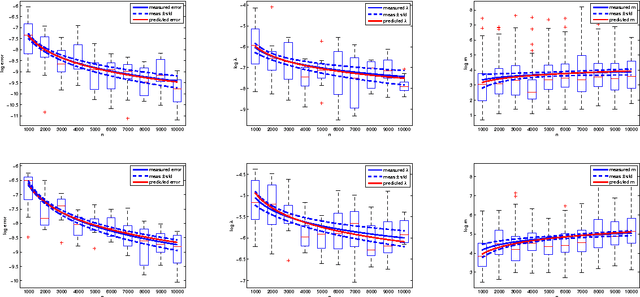
We study the generalization properties of ridge regression with random features in the statistical learning framework. We show for the first time that $O(1/\sqrt{n})$ learning bounds can be achieved with only $O(\sqrt{n}\log n)$ random features rather than $O({n})$ as suggested by previous results. Further, we prove faster learning rates and show that they might require more random features, unless they are sampled according to a possibly problem dependent distribution. Our results shed light on the statistical computational trade-offs in large scale kernelized learning, showing the potential effectiveness of random features in reducing the computational complexity while keeping optimal generalization properties.
Theory of Deep Learning III: explaining the non-overfitting puzzle
Jan 16, 2018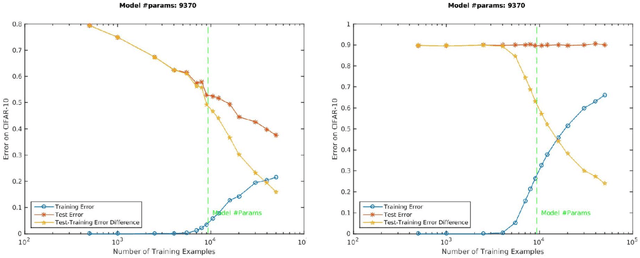
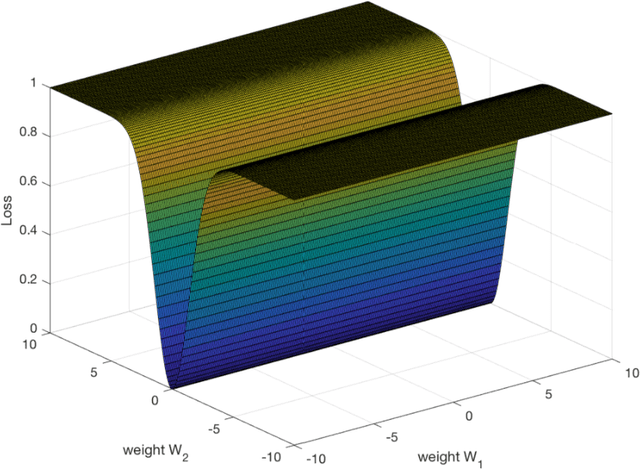
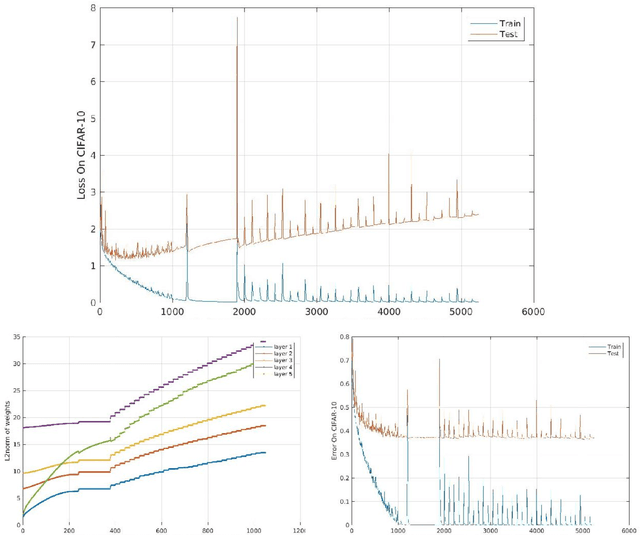
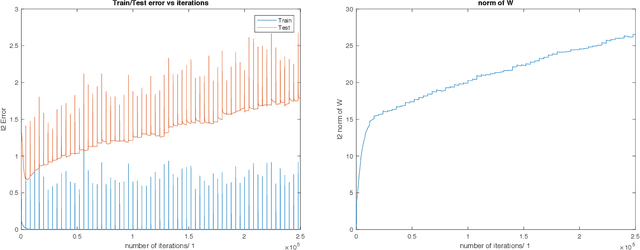
A main puzzle of deep networks revolves around the absence of overfitting despite large overparametrization and despite the large capacity demonstrated by zero training error on randomly labeled data. In this note, we show that the dynamics associated to gradient descent minimization of nonlinear networks is topologically equivalent, near the asymptotically stable minima of the empirical error, to linear gradient system in a quadratic potential with a degenerate (for square loss) or almost degenerate (for logistic or crossentropy loss) Hessian. The proposition depends on the qualitative theory of dynamical systems and is supported by numerical results. Our main propositions extend to deep nonlinear networks two properties of gradient descent for linear networks, that have been recently established (1) to be key to their generalization properties: 1. Gradient descent enforces a form of implicit regularization controlled by the number of iterations, and asymptotically converges to the minimum norm solution for appropriate initial conditions of gradient descent. This implies that there is usually an optimum early stopping that avoids overfitting of the loss. This property, valid for the square loss and many other loss functions, is relevant especially for regression. 2. For classification, the asymptotic convergence to the minimum norm solution implies convergence to the maximum margin solution which guarantees good classification error for "low noise" datasets. This property holds for loss functions such as the logistic and cross-entropy loss independently of the initial conditions. The robustness to overparametrization has suggestive implications for the robustness of the architecture of deep convolutional networks with respect to the curse of dimensionality.
Optimal Rates for Multi-pass Stochastic Gradient Methods
Oct 21, 2017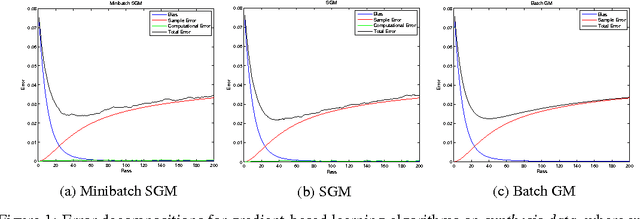
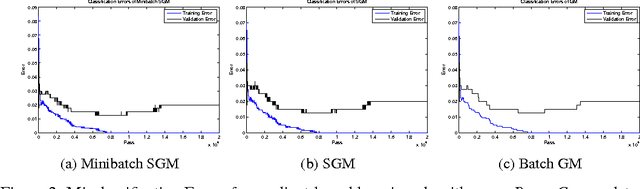
We analyze the learning properties of the stochastic gradient method when multiple passes over the data and mini-batches are allowed. We study how regularization properties are controlled by the step-size, the number of passes and the mini-batch size. In particular, we consider the square loss and show that for a universal step-size choice, the number of passes acts as a regularization parameter, and optimal finite sample bounds can be achieved by early-stopping. Moreover, we show that larger step-sizes are allowed when considering mini-batches. Our analysis is based on a unifying approach, encompassing both batch and stochastic gradient methods as special cases. As a byproduct, we derive optimal convergence results for batch gradient methods (even in the non-attainable cases).
Optimal Rates for Learning with Nyström Stochastic Gradient Methods
Oct 21, 2017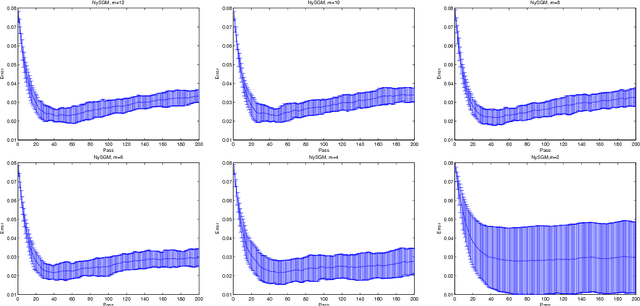
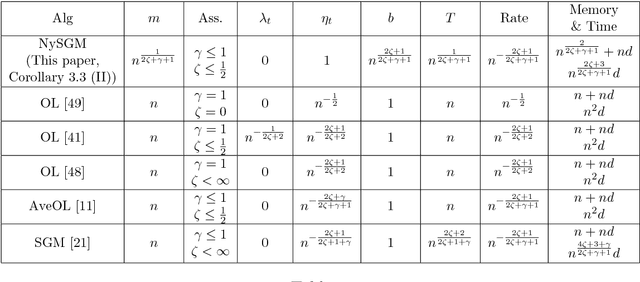
In the setting of nonparametric regression, we propose and study a combination of stochastic gradient methods with Nystr\"om subsampling, allowing multiple passes over the data and mini-batches. Generalization error bounds for the studied algorithm are provided. Particularly, optimal learning rates are derived considering different possible choices of the step-size, the mini-batch size, the number of iterations/passes, and the subsampling level. In comparison with state-of-the-art algorithms such as the classic stochastic gradient methods and kernel ridge regression with Nystr\"om, the studied algorithm has advantages on the computational complexity, while achieving the same optimal learning rates. Moreover, our results indicate that using mini-batches can reduce the total computational cost while achieving the same optimal statistical results.