 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymptotics of Ridge(less) Regression under General Source Condition
Jun 11, 2020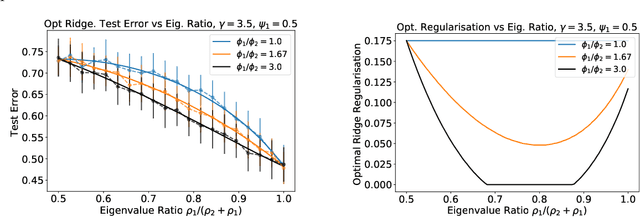
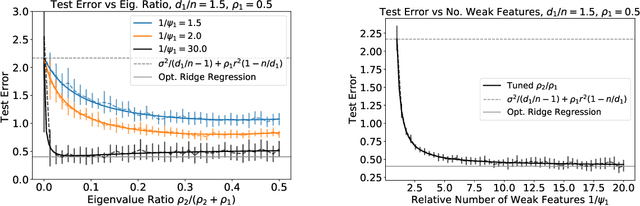
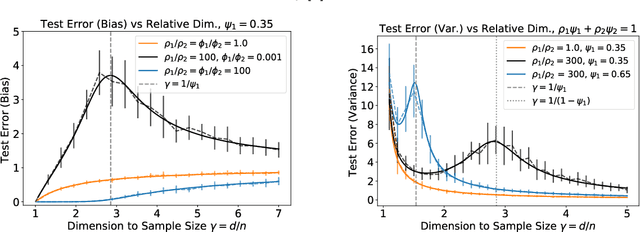
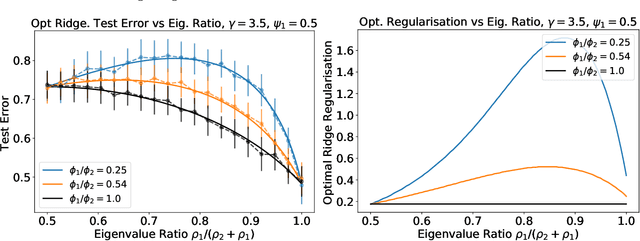
We analyze the prediction performance of ridge and ridgeless regression when both the number and the dimension of the data go to infinity. In particular, we consider a general setting introducing prior assumptions characterizing "easy" and "hard" learning problems. In this setting, we show that ridgeless (zero regularisation) regression is optimal for easy problems with a high signal to noise. Furthermore, we show that additional descents in the ridgeless bias and variance learning curve can occur beyond the interpolating threshold, verifying recent empirical observations. More generally, we show how a variety of learning curves are possible depending on the problem at hand. From a technical point of view, characterising the influence of prior assumptions requires extending previous applications of random matrix theory to study ridge regression.
Hyperbolic Manifold Regression
May 28, 2020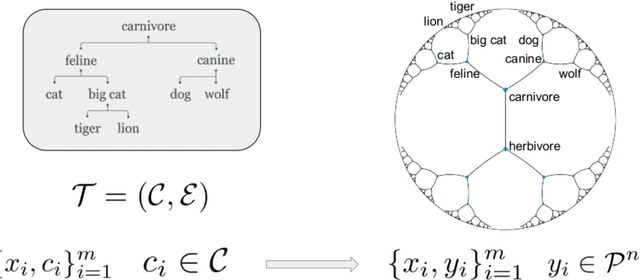
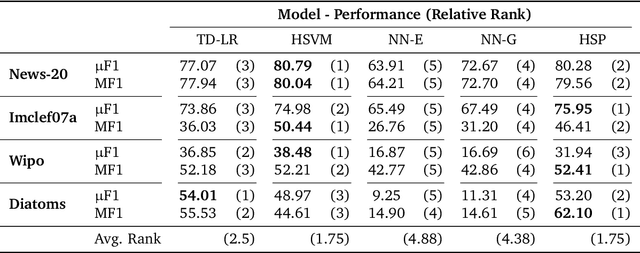
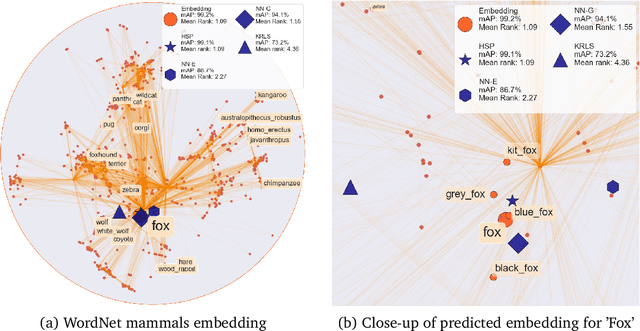
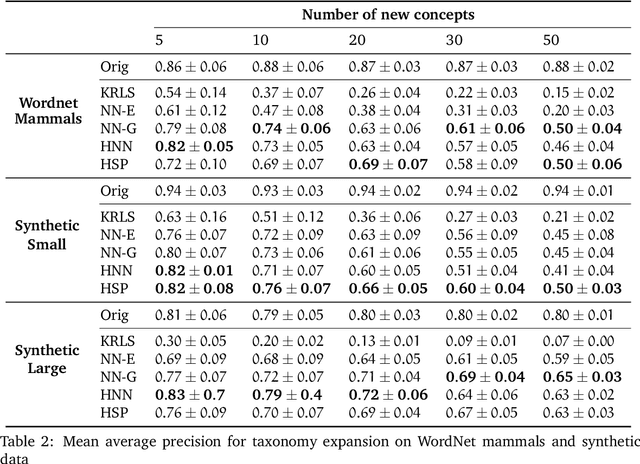
Geometric representation learning has recently shown great promise in several machine learning settings, ranging from relational learning to language processing and generative models. In this work, we consider the problem of performing manifold-valued regression onto an hyperbolic space as an intermediate component for a number of relevant machine learning applications. In particular, by formulating the problem of predicting nodes of a tree as a manifold regression task in the hyperbolic space, we propose a novel perspective on two challenging tasks: 1) hierarchical classification via label embeddings and 2) taxonomy extension of hyperbolic representations. To address the regression problem we consider previous methods as well as proposing two novel approaches that are computationally more advantageous: a parametric deep learning model that is informed by the geodesics of the target space and a non-parametric kernel-method for which we also prove excess risk bounds. Our experiments show that the strategy of leveraging the hyperbolic geometry is promising. In particular, in the taxonomy expansion setting, we find that the hyperbolic-based estimators significantly outperform methods performing regression in the ambient Euclidean space.
Constructing fast approximate eigenspaces with application to the fast graph Fourier transforms
Mar 20, 2020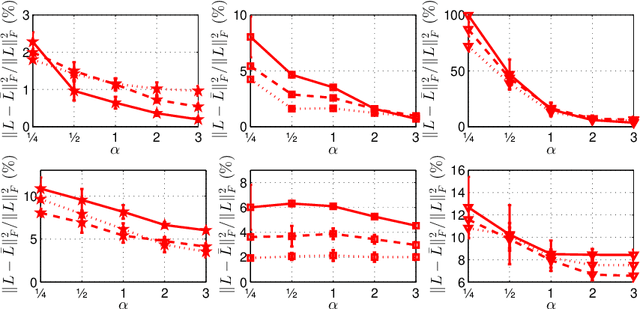
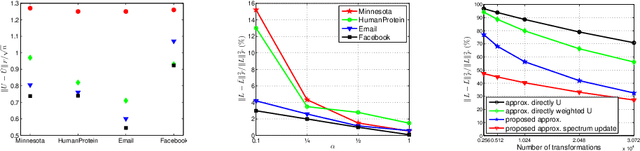
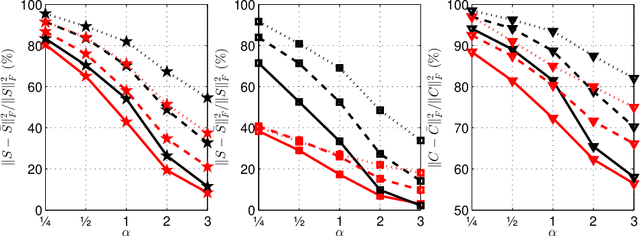
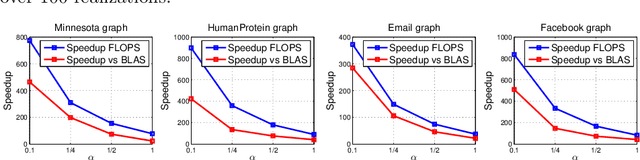
We investigate numerically efficient approximations of eigenspaces associated to symmetric and general matrices. The eigenspaces are factored into a fixed number of fundamental components that can be efficiently manipulated (we consider extended orthogonal Givens or scaling and shear transformations). The number of these components controls the trade-off between approximation accuracy and the computational complexity of projecting on the eigenspaces. We write minimization problems for the single fundamental components and provide closed-form solutions. Then we propose algorithms that iterative update all these components until convergence. We show results on random matrices and an application on the approximation of graph Fourier transforms for directed and undirected graphs.
Near-linear Time Gaussian Process Optimization with Adaptive Batching and Resparsification
Feb 26, 2020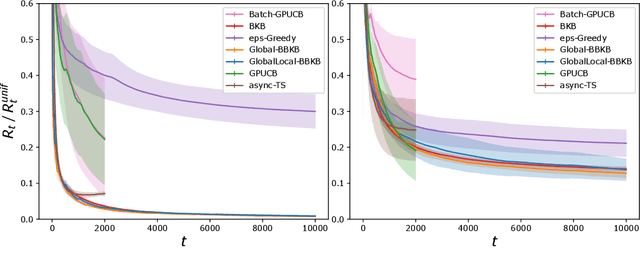
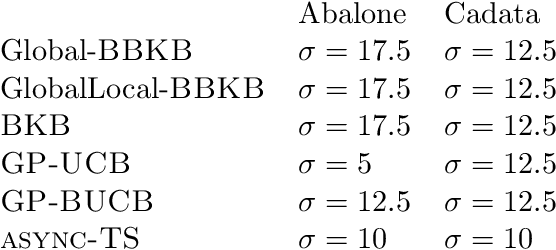
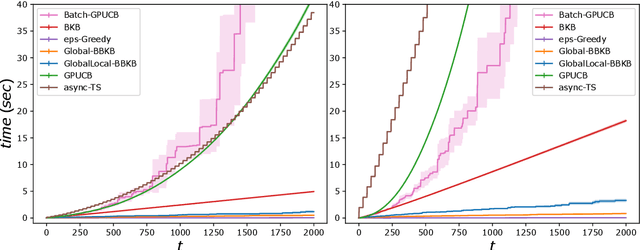
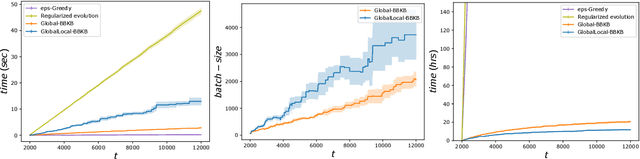
Gaussian processes (GP) are one of the most successful frameworks to model uncertainty. However, GP optimization (e.g., GP-UCB) suffers from major scalability issues. Experimental time grows linearly with the number of evaluations, unless candidates are selected in batches (e.g., using GP-BUCB) and evaluated in parallel. Furthermore, computational cost is often prohibitive since algorithms such as GP-BUCB require a time at least quadratic in the number of dimensions and iterations to select each batch. In this paper, we introduce BBKB (Batch Budgeted Kernel Bandits), the first no-regret GP optimization algorithm that provably runs in near-linear time and selects candidates in batches. This is obtained with a new guarantee for the tracking of the posterior variances that allows BBKB to choose increasingly larger batches, improving over GP-BUCB. Moreover, we show that the same bound can be used to adaptively delay costly updates to the sparse GP approximation used by BBKB, achieving a near-constant per-step amortized cost. These findings are then confirmed in several experiments, where BBKB is much faster than state-of-the-art methods.
A General Framework for Consistent Structured Prediction with Implicit Loss Embeddings
Feb 13, 2020

We propose and analyze a novel theoretical and algorithmic framework for structured prediction. While so far the term has referred to discrete output spaces, here we consider more general settings, such as manifolds or spaces of probability measures. We define structured prediction as a problem where the output space lacks a vectorial structure. We identify and study a large class of loss functions that implicitly defines a suitable geometry on the problem. The latter is the key to develop an algorithmic framework amenable to a sharp statistical analysis and yielding efficient computations. When dealing with output spaces with infinite cardinality, a suitable implicit formulation of the estimator is shown to be crucial.
Multi-Scale Vector Quantization with Reconstruction Trees
Sep 04, 2019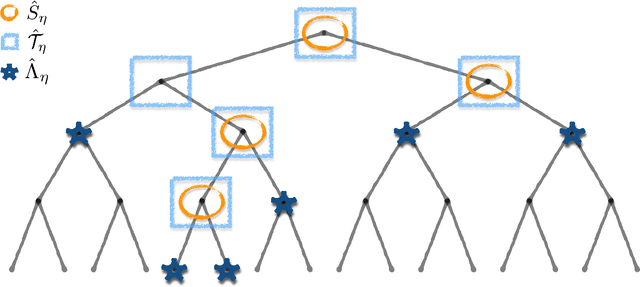
We propose and study a multi-scale approach to vector quantization. We develop an algorithm, dubbed reconstruction trees, inspired by decision trees. Here the objective is parsimonious reconstruction of unsupervised data, rather than classification. Contrasted to more standard vector quantization methods, such as K-means, the proposed approach leverages a family of given partitions, to quickly explore the data in a coarse to fine-- multi-scale-- fashion. Our main technical contribution is an analysis of the expected distortion achieved by the proposed algorithm, when the data are assumed to be sampled from a fixed unknown distribution. In this context, we derive both asymptotic and finite sample results under suitable regularity assumptions on the distribution. As a special case, we consider the setting where the data generating distribution is supported on a compact Riemannian sub-manifold. Tools from differential geometry and concentration of measure are useful in our analysis.
Statistical and Computational Trade-Offs in Kernel K-Means
Aug 27, 2019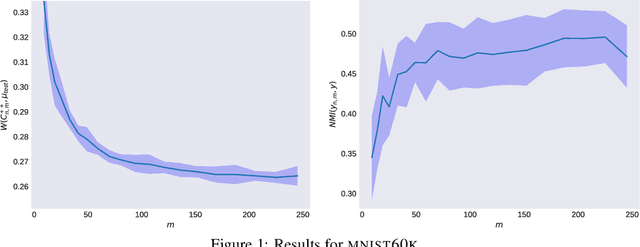
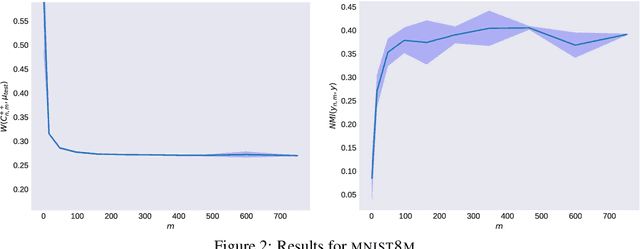
We investigate the efficiency of k-means in terms of both statistical and computational requirements. More precisely, we study a Nystr\"om approach to kernel k-means. We analyze the statistical properties of the proposed method and show that it achieves the same accuracy of exact kernel k-means with only a fraction of computations. Indeed, we prove under basic assumptions that sampling $\sqrt{n}$ Nystr\"om landmarks allows to greatly reduce computational costs without incurring in any loss of accuracy. To the best of our knowledge this is the first result of this kind for unsupervised learning.
Fast approximation of orthogonal matrices and application to PCA
Jul 18, 2019
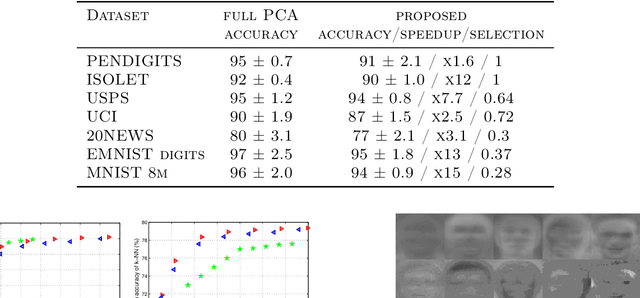
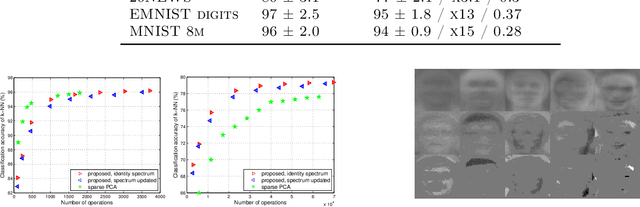
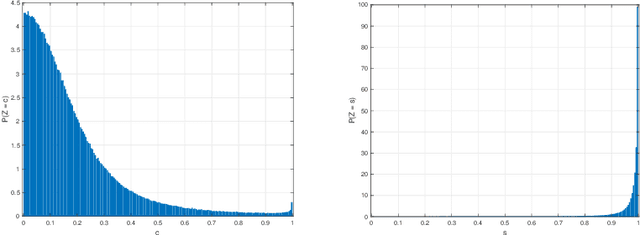
We study the problem of approximating orthogonal matrices so that their application is numerically fast and yet accurate. We find an approximation by solving an optimization problem over a set of structured matrices, that we call Givens transformations, including Givens rotations as a special case. We propose an efficient greedy algorithm to solve such a problem and show that it strikes a balance between approximation accuracy and speed of computation. The proposed approach is relevant in spectral methods and we illustrate its application to PCA.
Gain with no Pain: Efficient Kernel-PCA by Nyström Sampling
Jul 11, 2019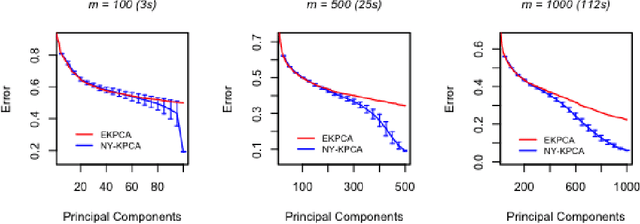
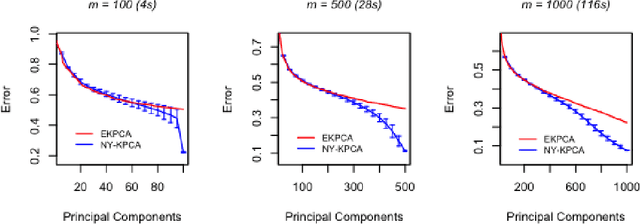
In this paper, we propose and study a Nystr\"om based approach to efficient large scale kernel principal component analysis (PCA). The latter is a natural nonlinear extension of classical PCA based on considering a nonlinear feature map or the corresponding kernel. Like other kernel approaches, kernel PCA enjoys good mathematical and statistical properties but, numerically, it scales poorly with the sample size. Our analysis shows that Nystr\"om sampling greatly improves computational efficiency without incurring any loss of statistical accuracy. While similar effects have been observed in supervised learning, this is the first such result for PCA. Our theoretical findings, which are also illustrated by numerical results, are based on a combination of analytic and concentration of measure techniques. Our study is more broadly motivated by the question of understanding the interplay between statistical and computational requirements for learning.
Implicit Regularization of Accelerated Methods in Hilbert Spaces
May 31, 2019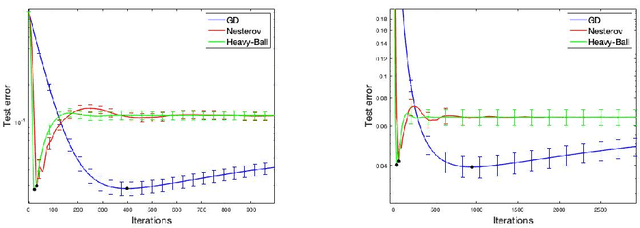
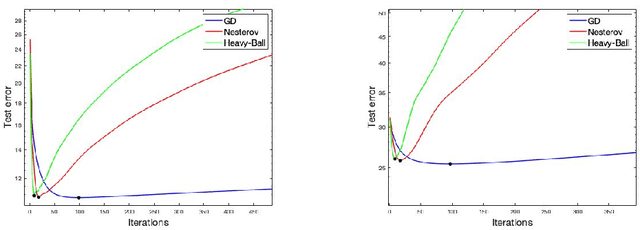
We study learning properties of accelerated gradient descent methods for linear least-squares in Hilbert spaces. We analyze the implicit regularization properties of Nesterov acceleration and a variant of heavy-ball in terms of corresponding learning error bounds. Our results show that acceleration can provides faster bias decay than gradient descent, but also suffers of a more unstable behavior. As a result acceleration cannot be in general expected to improve learning accuracy with respect to gradient descent, but rather to achieve the same accuracy with reduced computations. Our theoretical results are validated by numerical simulations. Our analysis is based on studying suitable polynomials induced by the accelerated dynamics and combining spectral techniques with concentration inequalities.