 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysReflect-VLA: Physical Feasibility and Self-Reflective Regulation for Reliable Vision-Language-Action Policies
Jun 25, 2026Long-horizon robotic manipulation is highly sensitive to physically infeasible transitions, contact-induced disturbances, and the lack of effective self-correction during execution. Although Vision-Language-Action (VLA) models provide strong task grounding through multimodal learning, they typically generate actions in a feed-forward manner without explicitly checking physical feasibility or diagnosing execution errors online. We present PhysReflect-VLA, a plug-and-play execution-time reliability framework that augments VLA policies with physical feasibility evaluation and structured self-reflection in a closed-loop control pipeline. A Feasibility Operator evaluates whether candidate actions induce dynamically consistent state transitions; an Action Explanation Operator verifies transition coherence; and an LLM-based Reflection Module analyzes state discrepancies to generate corrective guidance for subsequent actions. A two-stage training procedure stabilizes feasibility modeling and integrates reflection into the control loop. Experiments on multi-stage, contact-rich real-world manipulation tasks show consistent improvements in stage-wise stability and overall task success compared with representative VLA baselines with an average gain of 5.4\%. Ablation results further indicate that feasibility checking and reflection-based correction both contribute to improved execution robustness. These results highlight the importance of embedding physical consistency checks and online self-reflection for reliable long-horizon robotic manipulation.
PAMAE: Phase-Aware-MoE Action Experts Towards Reliable Flow-Matching Vision-Language-Action Policies
Jun 25, 2026Reliable action generation for multi-stage robotic manipulation remains challenging for Vision-Language-Action (VLA) models. While existing flow-matching VLA policies offer strong multimodal grounding and generalization, they typically employ a single shared action expert, limiting their ability to capture phase-specific control patterns across distinct execution stages. We propose a plug-and-play Phase-Aware Mixture-of-Experts Action Module (PAMAE), as a step towards more reliable phase-consistent action generation. PAMAE replaces the original flow-matching action expert with a sparse expert mixture while preserving the pretrained VLA backbone. PAMAE introduces a phase-aware router that leverages execution-phase cues to allocate action generation across experts, supported by a lightweight phase prediction head and a routing alignment objective. To stabilize specialization, we adopt a two-stage training scheme that first warms up the expert module under the standard flow-matching loss and then optimizes phase-consistent routing under auxiliary supervision. On multi-stage manipulation simulation tasks, PAMAE improves task success by up to \textbf{9.2\%} over strong VLA baselines. Further ablations show that both phase-supervised routing and staged optimization are essential for the observed gains. Our results highlight phase-consistent expert allocation as an effective mechanism for improving the reliability and action quality of flow-matching VLA policies.
From MAS to MARS: Coordination Failures and Reasoning Trade-offs in Hierarchical Multi-Agent Robotic Systems within a Healthcare Scenario
Aug 06, 2025Multi-agent robotic systems (MARS) build upon multi-agent systems by integrating physical and task-related constraints, increasing the complexity of action execution and agent coordination. However, despite the availability of advanced multi-agent frameworks, their real-world deployment on robots remains limited, hindering the advancement of MARS research in practice. To bridge this gap, we conducted two studies to investigate performance trade-offs of hierarchical multi-agent frameworks in a simulated real-world multi-robot healthcare scenario. In Study 1, using CrewAI, we iteratively refine the system's knowledge base, to systematically identify and categorize coordination failures (e.g., tool access violations, lack of timely handling of failure reports) not resolvable by providing contextual knowledge alone. In Study 2, using AutoGen, we evaluate a redesigned bidirectional communication structure and further measure the trade-offs between reasoning and non-reasoning models operating within the same robotic team setting. Drawing from our empirical findings, we emphasize the tension between autonomy and stability and the importance of edge-case testing to improve system reliability and safety for future real-world deployment. Supplementary materials, including codes, task agent setup, trace outputs, and annotated examples of coordination failures and reasoning behaviors, are available at: https://byc-sophie.github.io/mas-to-mars/.
Error Controlled Actor-Critic
Sep 07, 2021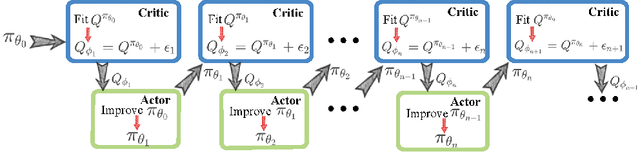
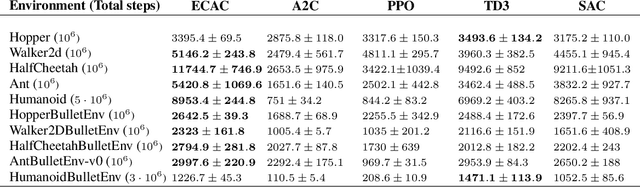
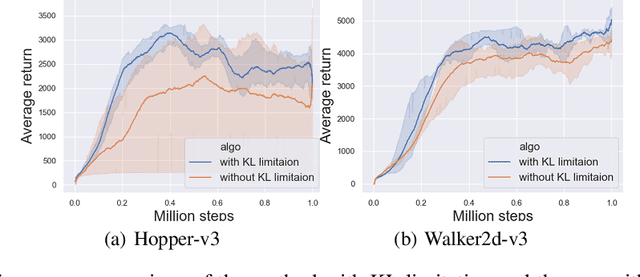

On error of value function inevitably causes an overestimation phenomenon and has a negative impact on the convergence of the algorithms. To mitigate the negative effects of the approximation error, we propose Error Controlled Actor-critic which ensures confining the approximation error in value function. We present an analysis of how the approximation error can hinder the optimization process of actor-critic methods.Then, we derive an upper boundary of the approximation error of Q function approximator and find that the error can be lowered by restricting on the KL-divergence between every two consecutive policies when training the policy. The results of experiments on a range of continuous control tasks demonstrate that the proposed actor-critic algorithm apparently reduces the approximation error and significantly outperforms other model-free RL algorithms.