 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVOODOO XP: Expressive One-Shot Head Reenactment for VR Telepresence
May 28, 2024We introduce VOODOO XP: a 3D-aware one-shot head reenactment method that can generate highly expressive facial expressions from any input driver video and a single 2D portrait. Our solution is real-time, view-consistent, and can be instantly used without calibration or fine-tuning. We demonstrate our solution on a monocular video setting and an end-to-end VR telepresence system for two-way communication. Compared to 2D head reenactment methods, 3D-aware approaches aim to preserve the identity of the subject and ensure view-consistent facial geometry for novel camera poses, which makes them suitable for immersive applications. While various facial disentanglement techniques have been introduced, cutting-edge 3D-aware neural reenactment techniques still lack expressiveness and fail to reproduce complex and fine-scale facial expressions. We present a novel cross-reenactment architecture that directly transfers the driver's facial expressions to transformer blocks of the input source's 3D lifting module. We show that highly effective disentanglement is possible using an innovative multi-stage self-supervision approach, which is based on a coarse-to-fine strategy, combined with an explicit face neutralization and 3D lifted frontalization during its initial training stage. We further integrate our novel head reenactment solution into an accessible high-fidelity VR telepresence system, where any person can instantly build a personalized neural head avatar from any photo and bring it to life using the headset. We demonstrate state-of-the-art performance in terms of expressiveness and likeness preservation on a large set of diverse subjects and capture conditions.
VOODOO 3D: Volumetric Portrait Disentanglement for One-Shot 3D Head Reenactment
Dec 07, 2023



We present a 3D-aware one-shot head reenactment method based on a fully volumetric neural disentanglement framework for source appearance and driver expressions. Our method is real-time and produces high-fidelity and view-consistent output, suitable for 3D teleconferencing systems based on holographic displays. Existing cutting-edge 3D-aware reenactment methods often use neural radiance fields or 3D meshes to produce view-consistent appearance encoding, but, at the same time, they rely on linear face models, such as 3DMM, to achieve its disentanglement with facial expressions. As a result, their reenactment results often exhibit identity leakage from the driver or have unnatural expressions. To address these problems, we propose a neural self-supervised disentanglement approach that lifts both the source image and driver video frame into a shared 3D volumetric representation based on tri-planes. This representation can then be freely manipulated with expression tri-planes extracted from the driving images and rendered from an arbitrary view using neural radiance fields. We achieve this disentanglement via self-supervised learning on a large in-the-wild video dataset. We further introduce a highly effective fine-tuning approach to improve the generalizability of the 3D lifting using the same real-world data. We demonstrate state-of-the-art performance on a wide range of datasets, and also showcase high-quality 3D-aware head reenactment on highly challenging and diverse subjects, including non-frontal head poses and complex expressions for both source and driver.
Toward Realistic Single-View 3D Object Reconstruction with Unsupervised Learning from Multiple Images
Sep 07, 2021
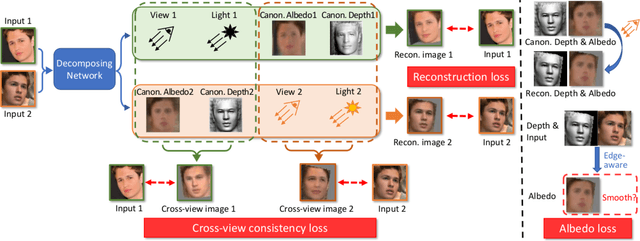
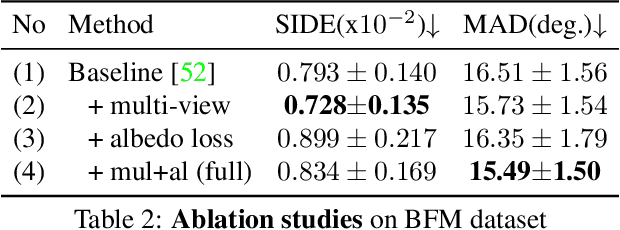

Recovering the 3D structure of an object from a single image is a challenging task due to its ill-posed nature. One approach is to utilize the plentiful photos of the same object category to learn a strong 3D shape prior for the object. This approach has successfully been demonstrated by a recent work of Wu et al. (2020), which obtained impressive 3D reconstruction networks with unsupervised learning. However, their algorithm is only applicable to symmetric objects. In this paper, we eliminate the symmetry requirement with a novel unsupervised algorithm that can learn a 3D reconstruction network from a multi-image dataset. Our algorithm is more general and covers the symmetry-required scenario as a special case. Besides, we employ a novel albedo loss that improves the reconstructed details and realisticity. Our method surpasses the previous work in both quality and robustness, as shown in experiments on datasets of various structures, including single-view, multi-view, image-collection, and video sets.