 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
CondSeg: Ellipse Estimation of Pupil and Iris via Conditioned Segmentation
Aug 30, 2024



Parsing of eye components (i.e. pupil, iris and sclera) is fundamental for eye tracking and gaze estimation for AR/VR products. Mainstream approaches tackle this problem as a multi-class segmentation task, providing only visible part of pupil/iris, other methods regress elliptical parameters using human-annotated full pupil/iris parameters. In this paper, we consider two priors: projected full pupil/iris circle can be modelled with ellipses (ellipse prior), and the visibility of pupil/iris is controlled by openness of eye-region (condition prior), and design a novel method CondSeg to estimate elliptical parameters of pupil/iris directly from segmentation labels, without explicitly annotating full ellipses, and use eye-region mask to control the visibility of estimated pupil/iris ellipses. Conditioned segmentation loss is used to optimize the parameters by transforming parameterized ellipses into pixel-wise soft masks in a differentiable way. Our method is tested on public datasets (OpenEDS-2019/-2020) and shows competitive results on segmentation metrics, and provides accurate elliptical parameters for further applications of eye tracking simultaneously.
End-To-End Face Detection and Recognition
Mar 31, 2017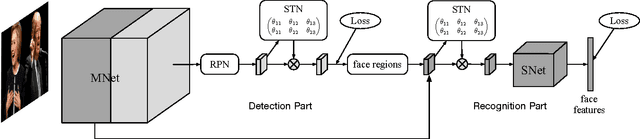
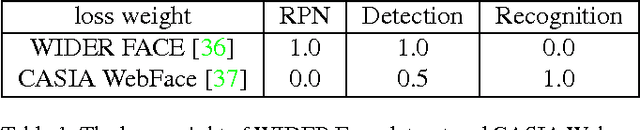
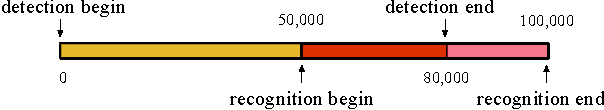

Plenty of face detection and recognition methods have been proposed and got delightful results in decades. Common face recognition pipeline consists of: 1) face detection, 2) face alignment, 3) feature extraction, 4) similarity calculation, which are separated and independent from each other. The separated face analyzing stages lead the model redundant calculation and are hard for end-to-end training. In this paper, we proposed a novel end-to-end trainable convolutional network framework for face detection and recognition, in which a geometric transformation matrix was directly learned to align the faces, instead of predicting the facial landmarks. In training stage, our single CNN model is supervised only by face bounding boxes and personal identities, which are publicly available from WIDER FACE \cite{Yang2016} dataset and CASIA-WebFace \cite{Yi2014} dataset. Tested on Face Detection Dataset and Benchmark (FDDB) \cite{Jain2010} dataset and Labeled Face in the Wild (LFW) \cite{Huang2007} dataset, we have achieved 89.24\% recall for face detection task and 98.63\% verification accuracy for face recognition task simultaneously, which are comparable to state-of-the-art results.