 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolving Context-Aware Recommender Systems With Users in Mind
Jul 30, 2020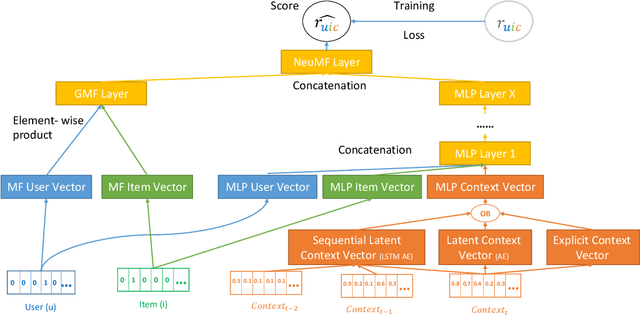

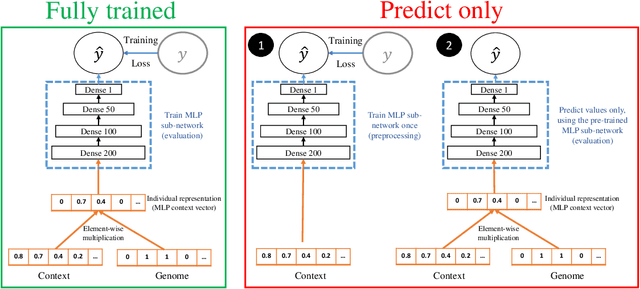
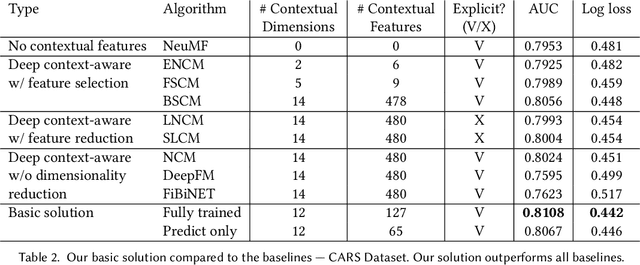
A context-aware recommender system (CARS) applies sensing and analysis of user context to provide personalized services. The contextual information can be driven from sensors in order to improve the accuracy of the recommendations. Yet, generating accurate recommendations is not enough to constitute a useful system from the users' perspective, since certain contextual information may cause different issues, such as draining the user's battery, privacy issues, and more. Adding high-dimensional contextual information may increase both the dimensionality and sparsity of the model. Previous studies suggest reducing the amount of contextual information by selecting the most suitable contextual information using a domain knowledge. Another solution is compressing it into a denser latent space, thus disrupting the ability to explain the recommendation item to the user, and damaging users' trust. In this paper we present an approach for selecting low-dimensional subsets of the contextual information and incorporating them explicitly within CARS. Specifically, we present a novel feature-selection algorithm, based on genetic algorithms (GA), that outperforms SOTA dimensional-reduction CARS algorithms, improves the accuracy and the explainability of the recommendations, and allows for controlling user aspects, such as privacy and battery consumption. Furthermore, we exploit the top subsets that are generated along the evolutionary process, by learning multiple deep context-aware models and applying a stacking technique on them, thus improving the accuracy while remaining at the explicit space. We evaluated our approach on two high-dimensional context-aware datasets driven from smartphones. An empirical analysis of our results validates that our proposed approach outperforms SOTA CARS models while improving transparency and explainability to the user.
A framework for optimizing COVID-19 testing policy using a Multi Armed Bandit approach
Jul 28, 2020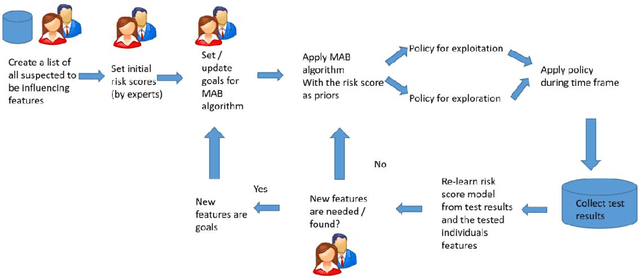
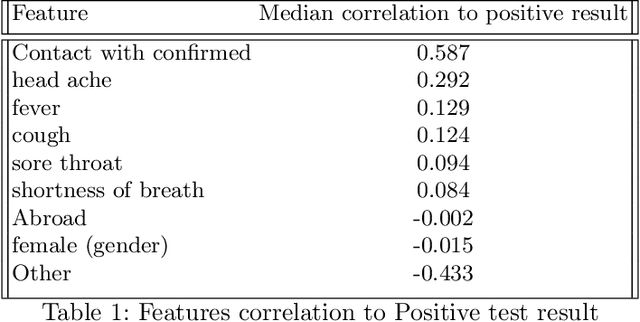
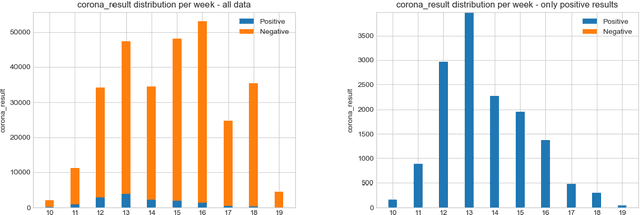
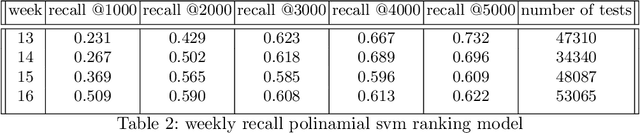
Testing is an important part of tackling the COVID-19 pandemic. Availability of testing is a bottleneck due to constrained resources and effective prioritization of individuals is necessary. Here, we discuss the impact of different prioritization policies on COVID-19 patient discovery and the ability of governments and health organizations to use the results for effective decision making. We suggest a framework for testing that balances the maximal discovery of positive individuals with the need for population-based surveillance aimed at understanding disease spread and characteristics. This framework draws from similar approaches to prioritization in the domain of cyber-security based on ranking individuals using a risk score and then reserving a portion of the capacity for random sampling. This approach is an application of Multi-Armed-Bandits maximizing exploration/exploitation of the underlying distribution. We find that individuals can be ranked for effective testing using a few simple features, and that ranking them using such models we can capture 65% (CI: 64.7%-68.3%) of the positive individuals using less than 20% of the testing capacity or 92.1% (CI: 91.1%-93.2%) of positives individuals using 70% of the capacity, allowing reserving a significant portion of the tests for population studies. Our approach allows experts and decision-makers to tailor the resulting policies as needed allowing transparency into the ranking policy and the ability to understand the disease spread in the population and react quickly and in an informed manner.
Iterative Boosting Deep Neural Networks for Predicting Click-Through Rate
Jul 26, 2020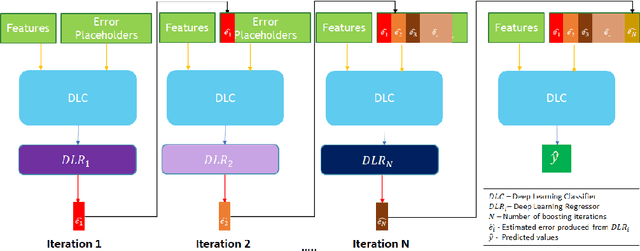


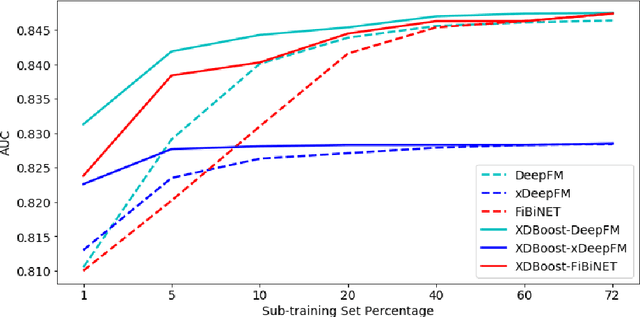
The click-through rate (CTR) reflects the ratio of clicks on a specific item to its total number of views. It has significant impact on websites' advertising revenue. Learning sophisticated models to understand and predict user behavior is essential for maximizing the CTR in recommendation systems. Recent works have suggested new methods that replace the expensive and time-consuming feature engineering process with a variety of deep learning (DL) classifiers capable of capturing complicated patterns from raw data; these methods have shown significant improvement on the CTR prediction task. While DL techniques can learn intricate user behavior patterns, it relies on a vast amount of data and does not perform as well when there is a limited amount of data. We propose XDBoost, a new DL method for capturing complex patterns that requires just a limited amount of raw data. XDBoost is an iterative three-stage neural network model influenced by the traditional machine learning boosting mechanism. XDBoost's components operate sequentially similar to boosting; However, unlike conventional boosting, XDBoost does not sum the predictions generated by its components. Instead, it utilizes these predictions as new artificial features and enhances CTR prediction by retraining the model using these features. Comprehensive experiments conducted to illustrate the effectiveness of XDBoost on two datasets demonstrated its ability to outperform existing state-of-the-art (SOTA) models for CTR prediction.
Adversarial Learning in the Cyber Security Domain
Jul 05, 2020
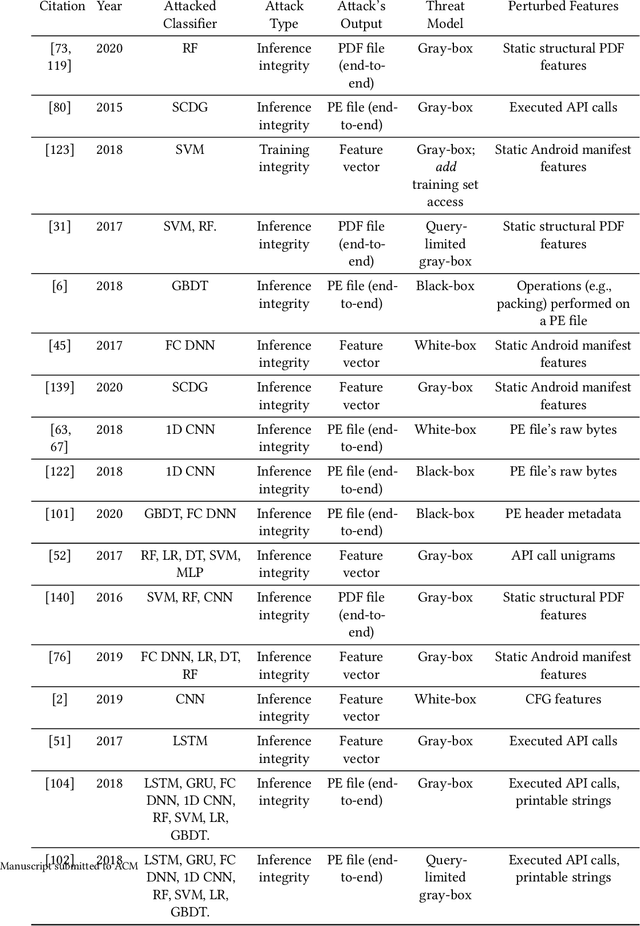
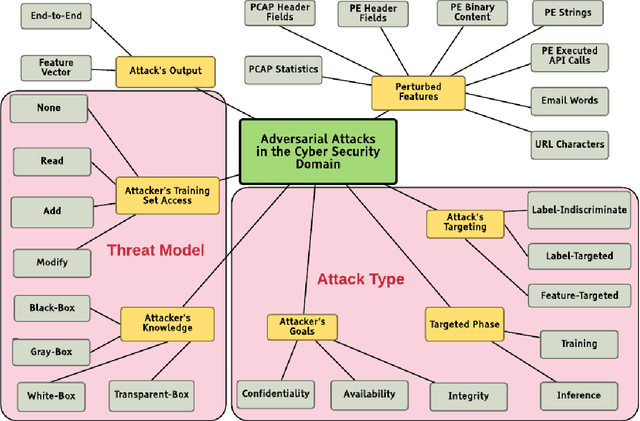
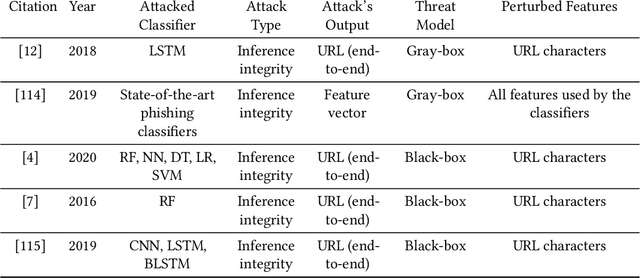
In recent years, machine learning algorithms, and more specially, deep learning algorithms, have been widely used in many fields, including cyber security. However, machine learning systems are vulnerable to adversarial attacks, and this limits the application of machine learning, especially in non-stationary, adversarial environments, such as the cyber security domain, where actual adversaries (e.g., malware developers) exist. This paper comprehensively summarizes the latest research on adversarial attacks against security solutions that are based on machine learning techniques and presents the risks they pose to cyber security solutions. First, we discuss the unique challenges of implementing end-to-end adversarial attacks in the cyber security domain. Following that, we define a unified taxonomy, where the adversarial attack methods are characterized based on their stage of occurrence, and the attacker's goals and capabilities. Then, we categorize the applications of adversarial attack techniques in the cyber security domain. Finally, we use our taxonomy to shed light on gaps in the cyber security domain that have already been addressed in other adversarial learning domains and discuss their impact on future adversarial learning trends in the cyber security domain.
PIVEN: A Deep Neural Network for Prediction Intervals with Specific Value Prediction
Jun 09, 2020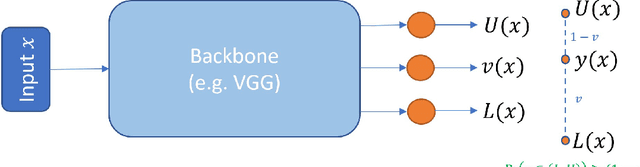
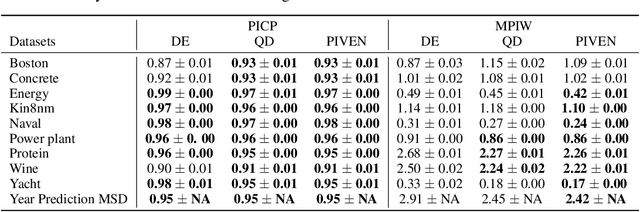
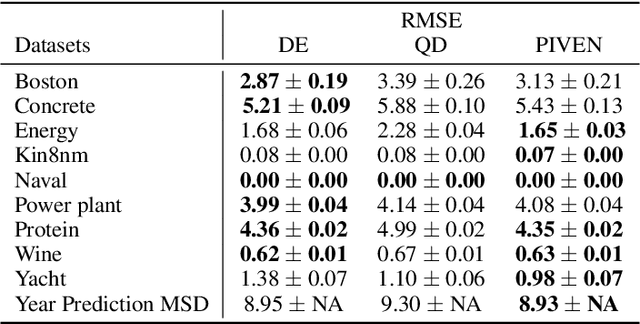
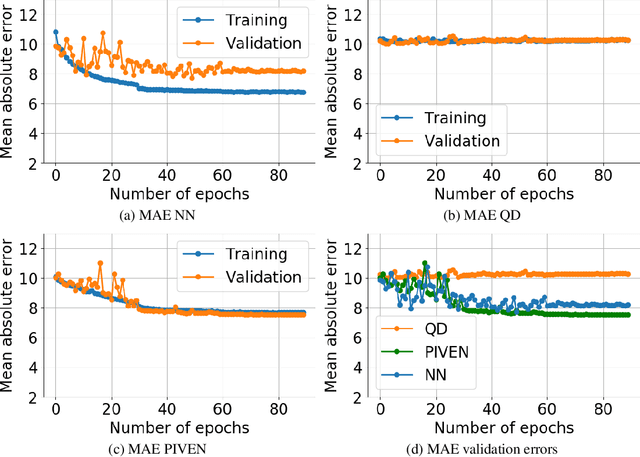
Improving the robustness of neural nets in regression tasks is key to their application in multiple domains. Deep learning-based approaches aim to achieve this goal either by improving the manner in which they produce their prediction of specific values (i.e., point prediction), or by producing prediction intervals (PIs) that quantify uncertainty. We present PIVEN, a deep neural network for producing both a PI and a prediction of specific values. Benchmark experiments show that our approach produces tighter uncertainty bounds than the current state-of-the-art approach for producing PIs, while managing to maintain comparable performance to the state-of-the-art approach for specific value-prediction. Additional evaluation on large image datasets further support our conclusions.
Automatic Machine Learning Derived from Scholarly Big Data
Mar 06, 2020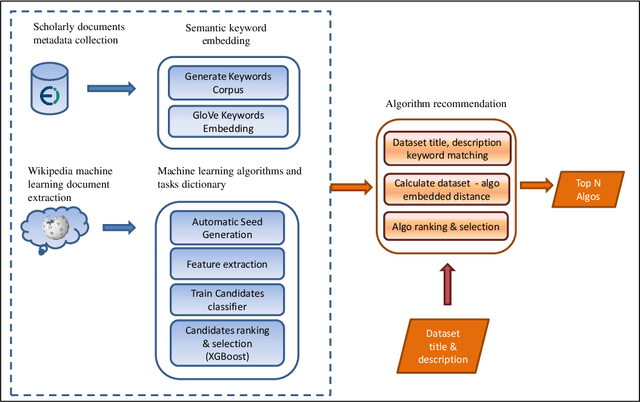
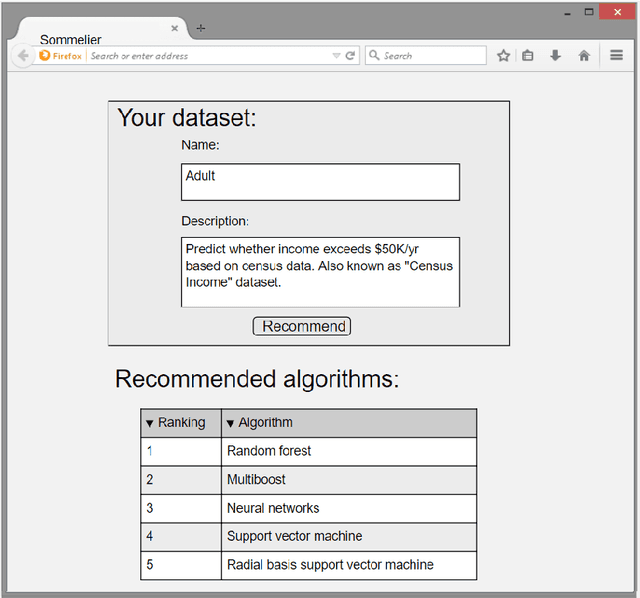

One of the challenging aspects of applying machine learning is the need to identify the algorithms that will perform best for a given dataset. This process can be difficult, time consuming and often requires a great deal of domain knowledge. We present Sommelier, an expert system for recommending the machine learning algorithms that should be applied on a previously unseen dataset. Sommelier is based on word embedding representations of the domain knowledge extracted from a large corpus of academic publications. When presented with a new dataset and its problem description, Sommelier leverages a recommendation model trained on the word embedding representation to provide a ranked list of the most relevant algorithms to be used on the dataset. We demonstrate Sommelier's effectiveness by conducting an extensive evaluation on 121 publicly available datasets and 53 classification algorithms. The top algorithms recommended for each dataset by Sommelier were able to achieve on average 97.7% of the optimal accuracy of all surveyed algorithms.
PrivGen: Preserving Privacy of Sequences Through Data Generation
Feb 23, 2020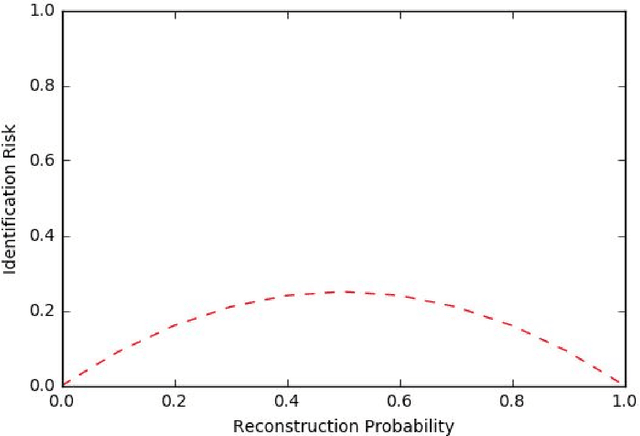

Sequential data is everywhere, and it can serve as a basis for research that will lead to improved processes. For example, road infrastructure can be improved by identifying bottlenecks in GPS data, or early diagnosis can be improved by analyzing patterns of disease progression in medical data. The main obstacle is that access and use of such data is usually limited or not permitted at all due to concerns about violating user privacy, and rightly so. Anonymizing sequence data is not a simple task, since a user creates an almost unique signature over time. Existing anonymization methods reduce the quality of information in order to maintain the level of anonymity required. Damage to quality may disrupt patterns that appear in the original data and impair the preservation of various characteristics. Since in many cases the researcher does not need the data as is and instead is only interested in the patterns that exist in the data, we propose PrivGen, an innovative method for generating data that maintains patterns and characteristics of the source data. We demonstrate that the data generation mechanism significantly limits the risk of privacy infringement. Evaluating our method with real-world datasets shows that its generated data preserves many characteristics of the data, including the sequential model, as trained based on the source data. This suggests that the data generated by our method could be used in place of actual data for various types of analysis, maintaining user privacy and the data's integrity at the same time.
Sequence Preserving Network Traffic Generation
Feb 23, 2020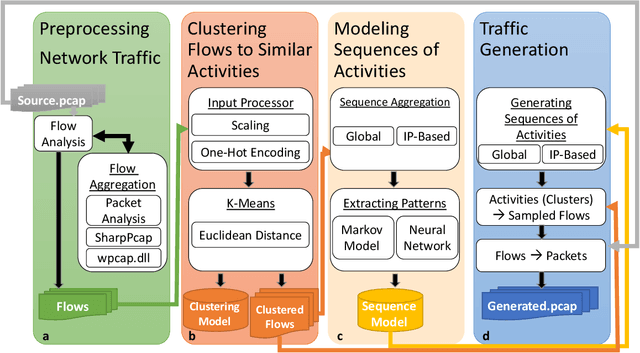


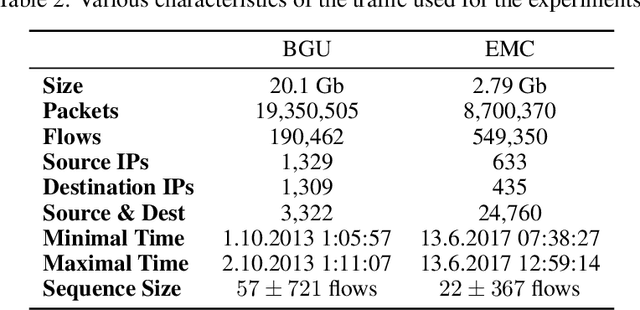
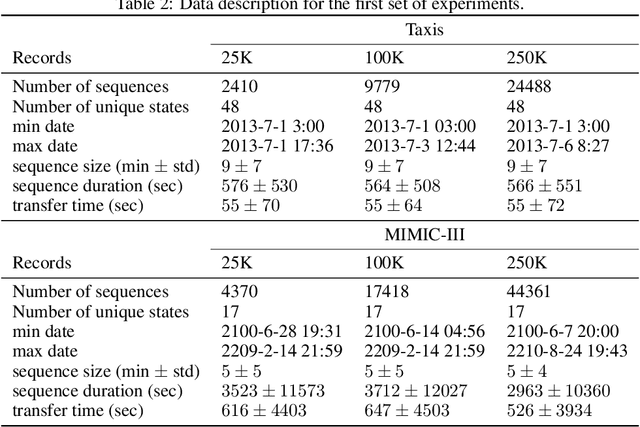
We present the Network Traffic Generator (NTG), a framework for perturbing recorded network traffic with the purpose of generating diverse but realistic background traffic for network simulation and what-if analysis in enterprise environments. The framework preserves many characteristics of the original traffic recorded in an enterprise, as well as sequences of network activities. Using the proposed framework, the original traffic flows are profiled using 200 cross-protocol features. The traffic is aggregated into flows of packets between IP pairs and clustered into groups of similar network activities. Sequences of network activities are then extracted. We examined two methods for extracting sequences of activities: a Markov model and a neural language model. Finally, new traffic is generated using the extracted model. We developed a prototype of the framework and conducted extensive experiments based on two real network traffic collections. Hypothesis testing was used to examine the difference between the distribution of original and generated features, showing that 30-100\% of the extracted features were preserved. Small differences between n-gram perplexities in sequences of network activities in the original and generated traffic, indicate that sequences of network activities were well preserved.
RankML: a Meta Learning-Based Approach for Pre-Ranking Machine Learning Pipelines
Nov 20, 2019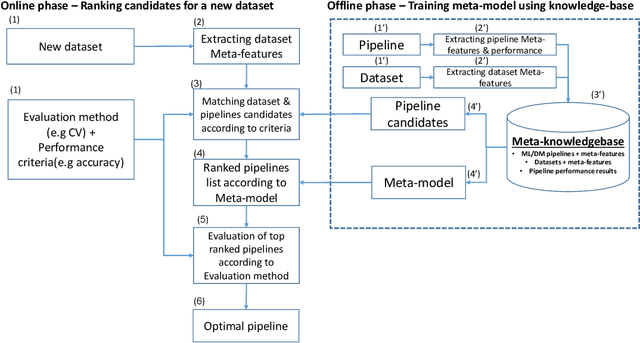
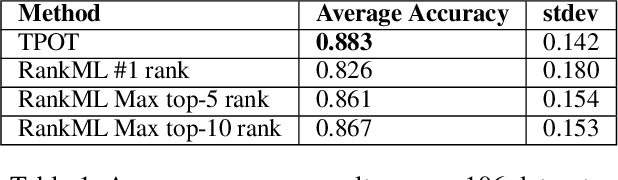
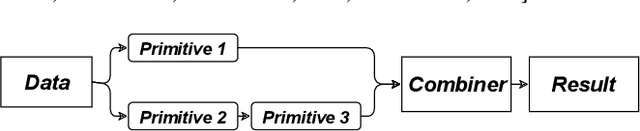
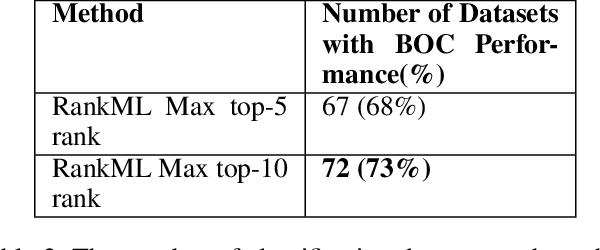
The explosion of digital data has created multiple opportunities for organizations and individuals to leverage machine learning (ML) to transform the way they operate. However, the shortage of experts in the field of machine learning -- data scientists -- is often a setback to the use of ML. In an attempt to alleviate this shortage, multiple approaches for the automation of machine learning have been proposed in recent years. While these approaches are effective, they often require a great deal of time and computing resources. In this study, we propose RankML, a meta-learning based approach for predicting the performance of whole machine learning pipelines. Given a previously-unseen dataset, a performance metric, and a set of candidate pipelines, RankML immediately produces a ranked list of all pipelines based on their predicted performance. Extensive evaluation on 244 datasets, both in regression and classification tasks, shows that our approach either outperforms or is comparable to state-of-the-art, computationally heavy approaches while requiring a fraction of the time and computational cost.
DeepLine: AutoML Tool for Pipelines Generation using Deep Reinforcement Learning and Hierarchical Actions Filtering
Oct 31, 2019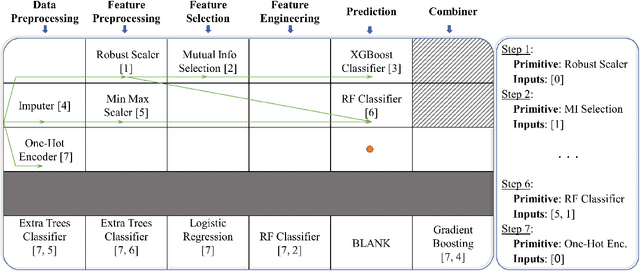
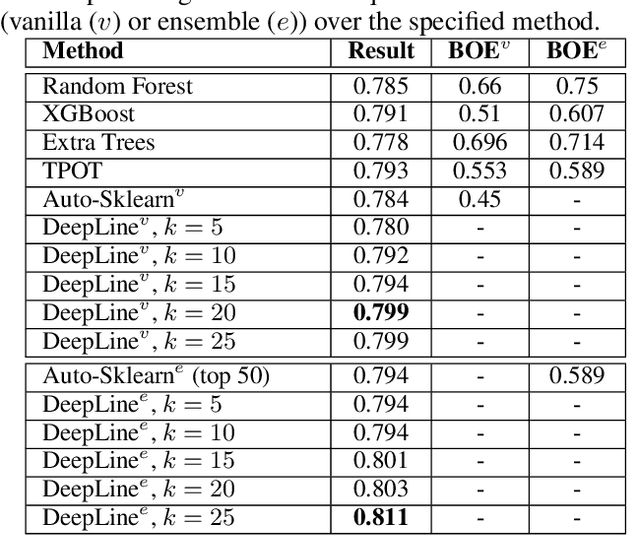
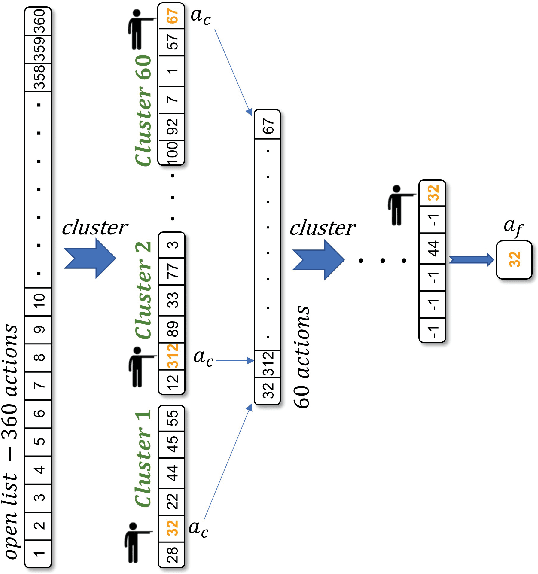
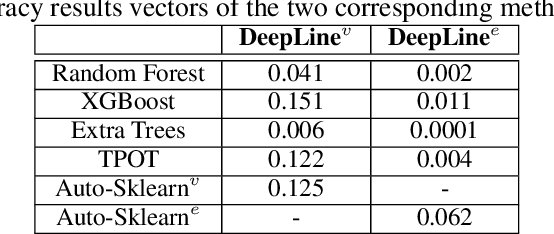
Automatic machine learning (AutoML) is an area of research aimed at automating machine learning (ML) activities that currently require human experts. One of the most challenging tasks in this field is the automatic generation of end-to-end ML pipelines: combining multiple types of ML algorithms into a single architecture used for end-to-end analysis of previously-unseen data. This task has two challenging aspects: the first is the need to explore a large search space of algorithms and pipeline architectures. The second challenge is the computational cost of training and evaluating multiple pipelines. In this study we present DeepLine, a reinforcement learning based approach for automatic pipeline generation. Our proposed approach utilizes an efficient representation of the search space and leverages past knowledge gained from previously-analyzed datasets to make the problem more tractable. Additionally, we propose a novel hierarchical-actions algorithm that serves as a plugin, mediating the environment-agent interaction in deep reinforcement learning problems. The plugin significantly speeds up the training process of our model. Evaluation on 56 datasets shows that DeepLine outperforms state-of-the-art approaches both in accuracy and in computational cost.