 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEcoThink: A Green Adaptive Inference Framework for Sustainable and Accessible Agents
Mar 26, 2026As the Web transitions from static retrieval to generative interaction, the escalating environmental footprint of Large Language Models (LLMs) presents a critical sustainability challenge. Current paradigms indiscriminately apply computation-intensive strategies like Chain-of-Thought (CoT) to billions of daily queries, causing LLM overthinking, a redundancy that amplifies carbon emissions and operational barriers. This inefficiency directly undermines UN Sustainable Development Goals 13 (Climate Action) and 10 (Reduced Inequalities) by hindering equitable AI access in resource-constrained regions. To address this, we introduce EcoThink, an energy-aware adaptive inference framework designed to reconcile high-performance AI intelligence with environmental responsibility. EcoThink employs a lightweight, distillation-based router to dynamically assess query complexity, skipping unnecessary reasoning for factoid retrieval while reserving deep computation for complex logic. Extensive evaluations across 9 diverse benchmarks demonstrate that EcoThink reduces inference energy by 40.4% on average (up to 81.9% for web knowledge retrieval) without statistically significant performance loss. By mitigating algorithmic waste, EcoThink offers a scalable path toward a sustainable, inclusive, and energy-efficient generative AI Agent.
Zero-Resource Knowledge-Grounded Dialogue Generation
Aug 29, 2020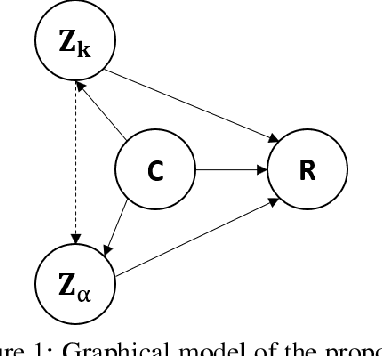
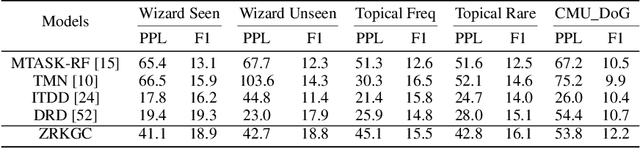

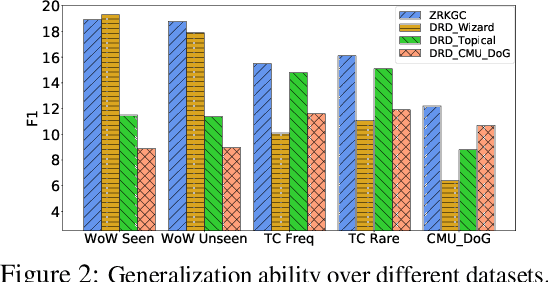
While neural conversation models have shown great potentials towards generating informative and engaging responses via introducing external knowledge, learning such a model often requires knowledge-grounded dialogues that are difficult to obtain. To overcome the data challenge and reduce the cost of building a knowledge-grounded dialogue system, we explore the problem under a zero-resource setting by assuming no context-knowledge-response triples are needed for training. To this end, we propose representing the knowledge that bridges a context and a response and the way that the knowledge is expressed as latent variables, and devise a variational approach that can effectively estimate a generation model from a dialogue corpus and a knowledge corpus that are independent with each other. Evaluation results on three benchmarks of knowledge-grounded dialogue generation indicate that our model can achieve comparable performance with state-of-the-art methods that rely on knowledge-grounded dialogues for training, and exhibits a good generalization ability over different topics and different datasets.