 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Representativeness in Accessibility Datasets: A Meta-Analysis
Jul 16, 2022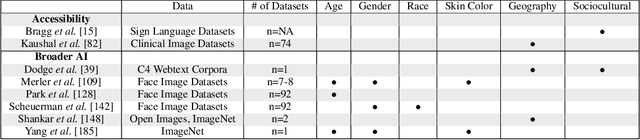
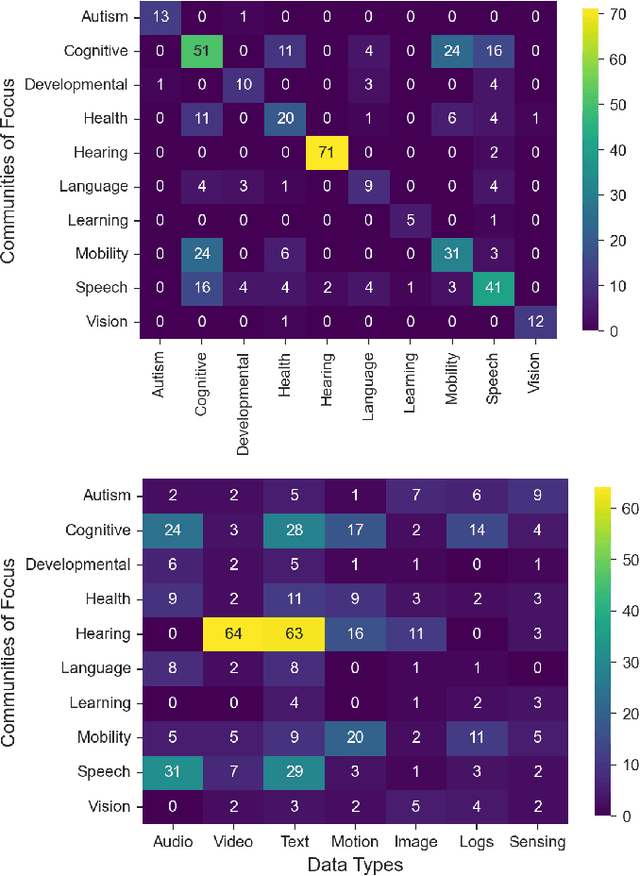
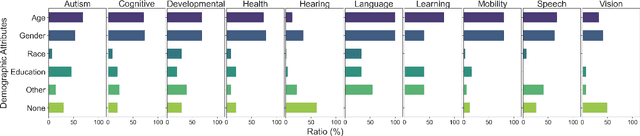
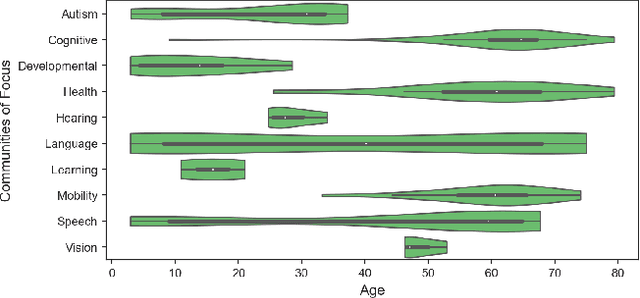
As data-driven systems are increasingly deployed at scale, ethical concerns have arisen around unfair and discriminatory outcomes for historically marginalized groups that are underrepresented in training data. In response, work around AI fairness and inclusion has called for datasets that are representative of various demographic groups.In this paper, we contribute an analysis of the representativeness of age, gender, and race & ethnicity in accessibility datasets - datasets sourced from people with disabilities and older adults - that can potentially play an important role in mitigating bias for inclusive AI-infused applications. We examine the current state of representation within datasets sourced by people with disabilities by reviewing publicly-available information of 190 datasets, we call these accessibility datasets. We find that accessibility datasets represent diverse ages, but have gender and race representation gaps. Additionally, we investigate how the sensitive and complex nature of demographic variables makes classification difficult and inconsistent (e.g., gender, race & ethnicity), with the source of labeling often unknown. By reflecting on the current challenges and opportunities for representation of disabled data contributors, we hope our effort expands the space of possibility for greater inclusion of marginalized communities in AI-infused systems.
Temporal Action Proposal Generation with Background Constraint
Dec 15, 2021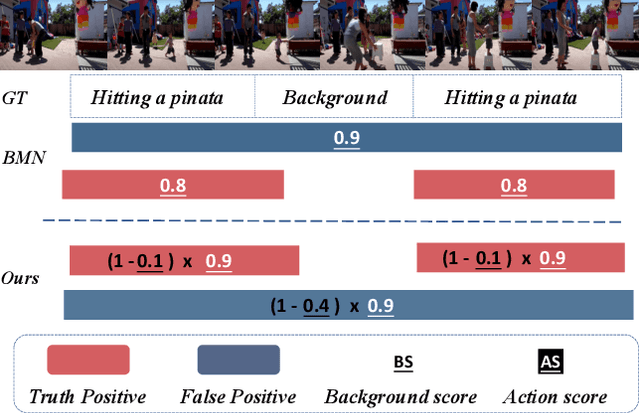
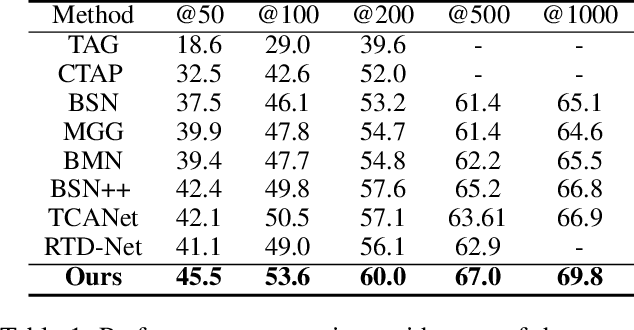
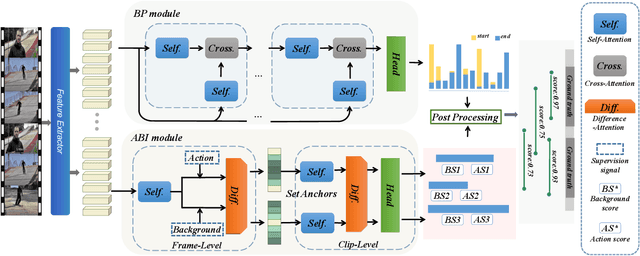
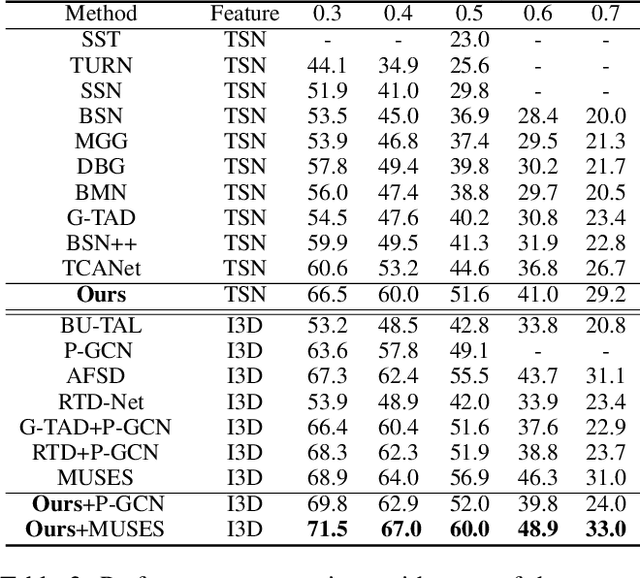
Temporal action proposal generation (TAPG) is a challenging task that aims to locate action instances in untrimmed videos with temporal boundaries. To evaluate the confidence of proposals, the existing works typically predict action score of proposals that are supervised by the temporal Intersection-over-Union (tIoU) between proposal and the ground-truth. In this paper, we innovatively propose a general auxiliary Background Constraint idea to further suppress low-quality proposals, by utilizing the background prediction score to restrict the confidence of proposals. In this way, the Background Constraint concept can be easily plug-and-played into existing TAPG methods (e.g., BMN, GTAD). From this perspective, we propose the Background Constraint Network (BCNet) to further take advantage of the rich information of action and background. Specifically, we introduce an Action-Background Interaction module for reliable confidence evaluation, which models the inconsistency between action and background by attention mechanisms at the frame and clip levels. Extensive experiments are conducted on two popular benchmarks, i.e., ActivityNet-1.3 and THUMOS14. The results demonstrate that our method outperforms state-of-the-art methods. Equipped with the existing action classifier, our method also achieves remarkable performance on the temporal action localization task.
Temporal Action Proposal Generation with Transformers
May 25, 2021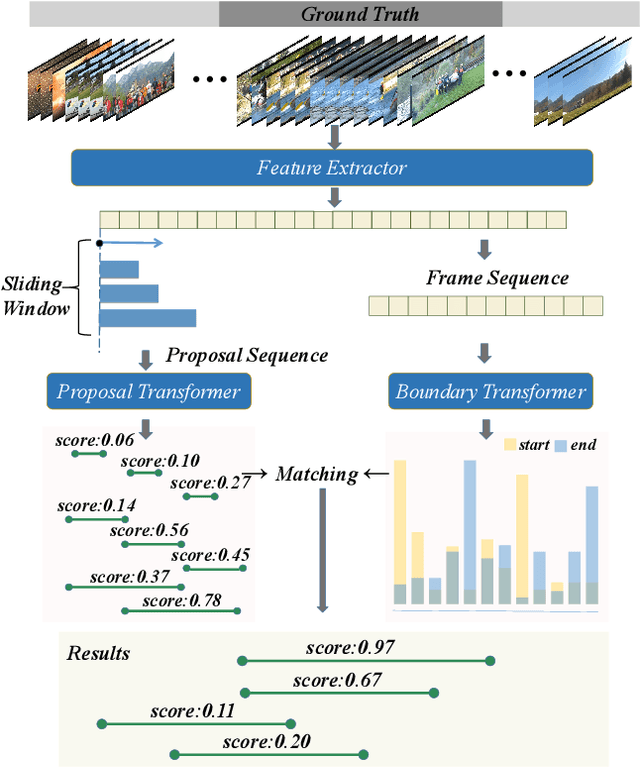
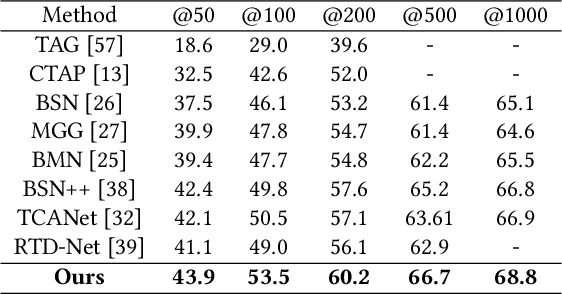
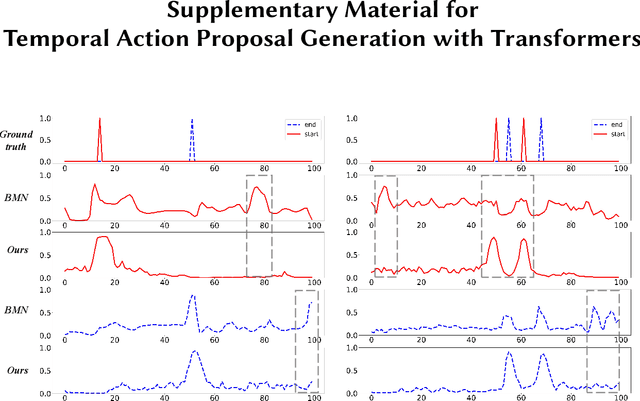
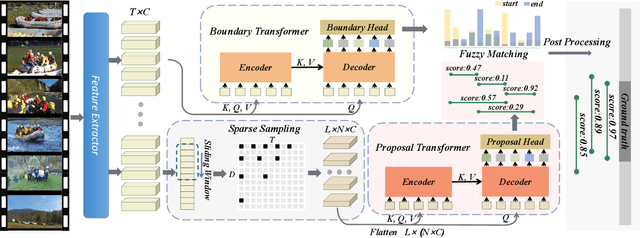
Transformer networks are effective at modeling long-range contextual information and have recently demonstrated exemplary performance in the natural language processing domain. Conventionally, the temporal action proposal generation (TAPG) task is divided into two main sub-tasks: boundary prediction and proposal confidence prediction, which rely on the frame-level dependencies and proposal-level relationships separately. To capture the dependencies at different levels of granularity, this paper intuitively presents a unified temporal action proposal generation framework with original Transformers, called TAPG Transformer, which consists of a Boundary Transformer and a Proposal Transformer. Specifically, the Boundary Transformer captures long-term temporal dependencies to predict precise boundary information and the Proposal Transformer learns the rich inter-proposal relationships for reliable confidence evaluation. Extensive experiments are conducted on two popular benchmarks: ActivityNet-1.3 and THUMOS14, and the results demonstrate that TAPG Transformer outperforms state-of-the-art methods. Equipped with the existing action classifier, our method achieves remarkable performance on the temporal action localization task. Codes and models will be available.