 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoverning Evolving Memory in LLM Agents: Risks, Mechanisms, and the Stability and Safety Governed Memory (SSGM) Framework
Mar 12, 2026Long-term memory has emerged as a foundational component of autonomous Large Language Model (LLM) agents, enabling continuous adaptation, lifelong multimodal learning, and sophisticated reasoning. However, as memory systems transition from static retrieval databases to dynamic, agentic mechanisms, critical concerns regarding memory governance, semantic drift, and privacy vulnerabilities have surfaced. While recent surveys have focused extensively on memory retrieval efficiency, they largely overlook the emergent risks of memory corruption in highly dynamic environments. To address these emerging challenges, we propose the Stability and Safety-Governed Memory (SSGM) framework, a conceptual governance architecture. SSGM decouples memory evolution from execution by enforcing consistency verification, temporal decay modeling, and dynamic access control prior to any memory consolidation. Through formal analysis and architectural decomposition, we show how SSGM can mitigate topology-induced knowledge leakage where sensitive contexts are solidified into long-term storage, and help prevent semantic drift where knowledge degrades through iterative summarization. Ultimately, this work provides a comprehensive taxonomy of memory corruption risks and establishes a robust governance paradigm for deploying safe, persistent, and reliable agentic memory systems.
Active Learning for Chinese Word Segmentation in Medical Text
Aug 22, 2019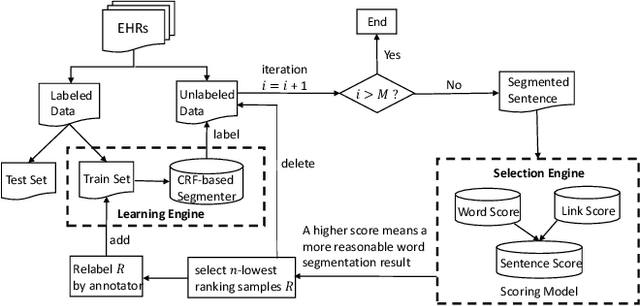
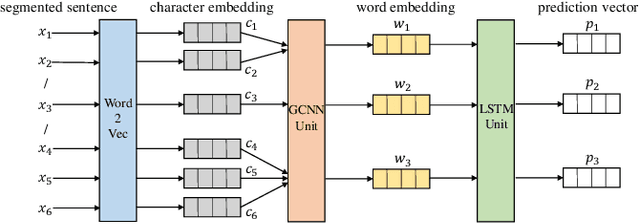
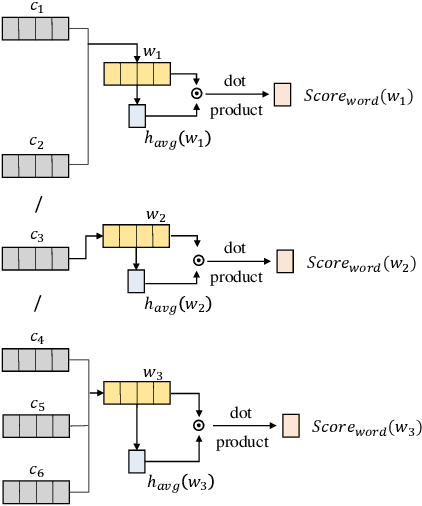
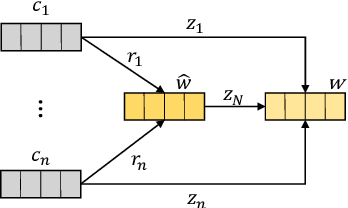
Electronic health records (EHRs) stored in hospital information systems completely reflect the patients' diagnosis and treatment processes, which are essential to clinical data mining. Chinese word segmentation (CWS) is a fundamental and important task for Chinese natural language processing. Currently, most state-of-the-art CWS methods greatly depend on large-scale manually-annotated data, which is a very time-consuming and expensive work, specially for the annotation in medical field. In this paper, we present an active learning method for CWS in medical text. To effectively utilize complete segmentation history, a new scoring model in sampling strategy is proposed, which combines information entropy with neural network. Besides, to capture interactions between adjacent characters, K-means clustering features are additionally added in word segmenter. We experimentally evaluate our proposed CWS method in medical text, experimental results based on EHRs collected from the Shuguang Hospital Affiliated to Shanghai University of Traditional Chinese Medicine show that our proposed method outperforms other reference methods, which can effectively save the cost of manual annotation.