 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdgeNeRF: Edge-Guided Regularization for Neural Radiance Fields from Sparse Views
Jan 04, 2026Neural Radiance Fields (NeRF) achieve remarkable performance in dense multi-view scenarios, but their reconstruction quality degrades significantly under sparse inputs due to geometric artifacts. Existing methods utilize global depth regularization to mitigate artifacts, leading to the loss of geometric boundary details. To address this problem, we propose EdgeNeRF, an edge-guided sparse-view 3D reconstruction algorithm. Our method leverages the prior that abrupt changes in depth and normals generate edges. Specifically, we first extract edges from input images, then apply depth and normal regularization constraints to non-edge regions, enhancing geometric consistency while preserving high-frequency details at boundaries. Experiments on LLFF and DTU datasets demonstrate EdgeNeRF's superior performance, particularly in retaining sharp geometric boundaries and suppressing artifacts. Additionally, the proposed edge-guided depth regularization module can be seamlessly integrated into other methods in a plug-and-play manner, significantly improving their performance without substantially increasing training time. Code is available at https://github.com/skyhigh404/edgenerf.
Naive Gabor Networks
Dec 09, 2019
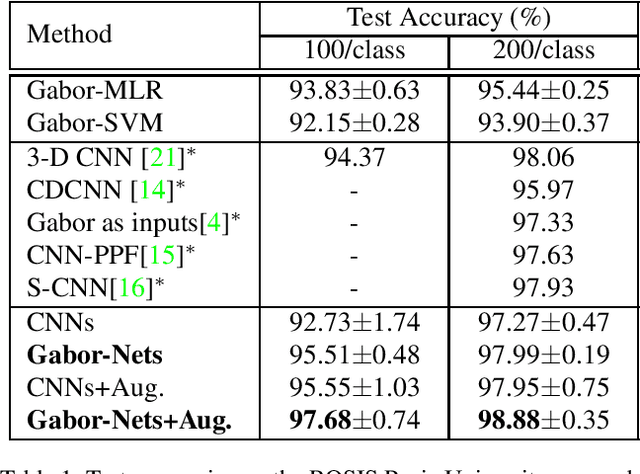
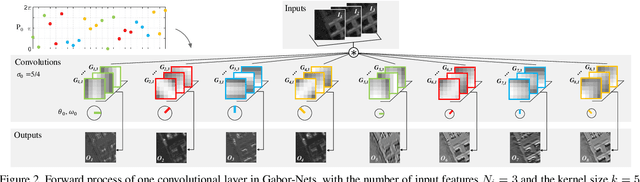
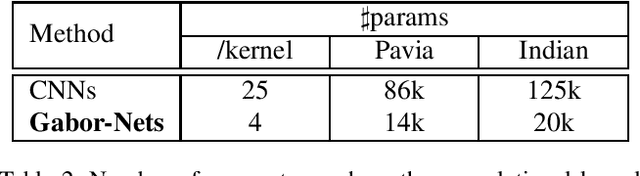
In this paper, we introduce naive Gabor Networks or Gabor-Nets which, for the first time in the literature, design and learn convolutional kernels strictly in the form of Gabor filters, aiming to reduce the number of parameters and constrain the solution space for convolutional neural networks (CNNs). In comparison with other Gabor-based methods, Gabor-Nets exploit the phase offset of the sinusoid harmonic to control the frequency characteristics of Gabor kernels, being able to adjust the convolutional kernels in accordance with the data from a frequency perspective. Furthermore, a fast 1-D decomposition of the Gabor kernel is implemented, bringing the original quadratic computational complexity of 2-D convolutions to a linear one. We evaluated our newly developed Gabor-Nets on two remotely sensed hyperspectral benchmarks, showing that our model architecture can significantly improve the convergence speed and the performance of CNNs, particularly when very limited training samples are available.