 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReLU soothes the NTK condition number and accelerates optimization for wide neural networks
May 15, 2023Rectified linear unit (ReLU), as a non-linear activation function, is well known to improve the expressivity of neural networks such that any continuous function can be approximated to arbitrary precision by a sufficiently wide neural network. In this work, we present another interesting and important feature of ReLU activation function. We show that ReLU leads to: {\it better separation} for similar data, and {\it better conditioning} of neural tangent kernel (NTK), which are closely related. Comparing with linear neural networks, we show that a ReLU activated wide neural network at random initialization has a larger angle separation for similar data in the feature space of model gradient, and has a smaller condition number for NTK. Note that, for a linear neural network, the data separation and NTK condition number always remain the same as in the case of a linear model. Furthermore, we show that a deeper ReLU network (i.e., with more ReLU activation operations), has a smaller NTK condition number than a shallower one. Our results imply that ReLU activation, as well as the depth of ReLU network, helps improve the gradient descent convergence rate, which is closely related to the NTK condition number.
Cut your Losses with Squentropy
Feb 08, 2023Nearly all practical neural models for classification are trained using cross-entropy loss. Yet this ubiquitous choice is supported by little theoretical or empirical evidence. Recent work (Hui & Belkin, 2020) suggests that training using the (rescaled) square loss is often superior in terms of the classification accuracy. In this paper we propose the "squentropy" loss, which is the sum of two terms: the cross-entropy loss and the average square loss over the incorrect classes. We provide an extensive set of experiments on multi-class classification problems showing that the squentropy loss outperforms both the pure cross entropy and rescaled square losses in terms of the classification accuracy. We also demonstrate that it provides significantly better model calibration than either of these alternative losses and, furthermore, has less variance with respect to the random initialization. Additionally, in contrast to the square loss, squentropy loss can typically be trained using exactly the same optimization parameters, including the learning rate, as the standard cross-entropy loss, making it a true "plug-and-play" replacement. Finally, unlike the rescaled square loss, multiclass squentropy contains no parameters that need to be adjusted.
Limitations of Neural Collapse for Understanding Generalization in Deep Learning
Feb 17, 2022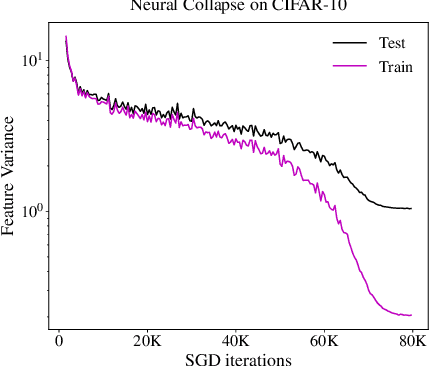
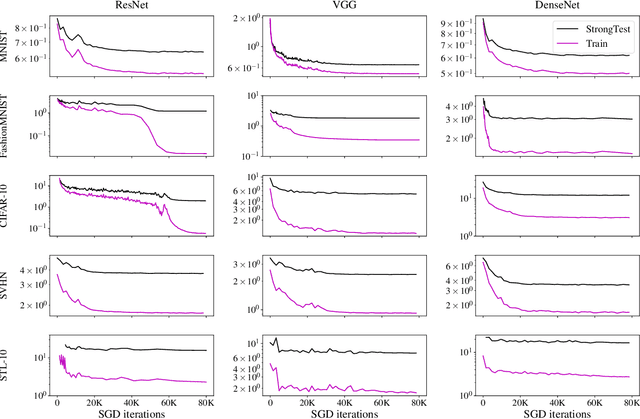
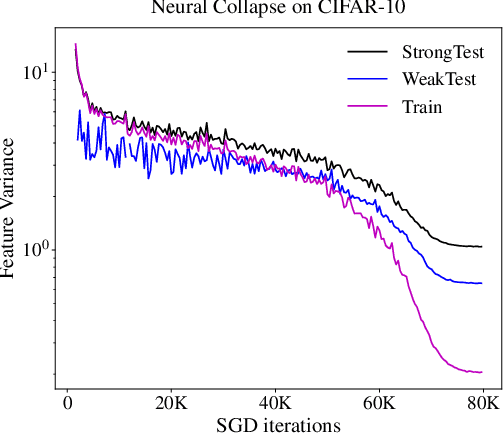
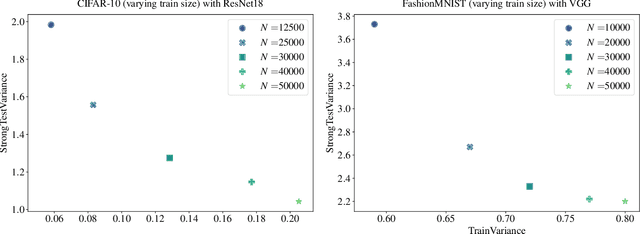
The recent work of Papyan, Han, & Donoho (2020) presented an intriguing "Neural Collapse" phenomenon, showing a structural property of interpolating classifiers in the late stage of training. This opened a rich area of exploration studying this phenomenon. Our motivation is to study the upper limits of this research program: How far will understanding Neural Collapse take us in understanding deep learning? First, we investigate its role in generalization. We refine the Neural Collapse conjecture into two separate conjectures: collapse on the train set (an optimization property) and collapse on the test distribution (a generalization property). We find that while Neural Collapse often occurs on the train set, it does not occur on the test set. We thus conclude that Neural Collapse is primarily an optimization phenomenon, with as-yet-unclear connections to generalization. Second, we investigate the role of Neural Collapse in feature learning. We show simple, realistic experiments where training longer leads to worse last-layer features, as measured by transfer-performance on a downstream task. This suggests that neural collapse is not always desirable for representation learning, as previously claimed. Finally, we give preliminary evidence of a "cascading collapse" phenomenon, wherein some form of Neural Collapse occurs not only for the last layer, but in earlier layers as well. We hope our work encourages the community to continue the rich line of Neural Collapse research, while also considering its inherent limitations.
Evaluation of Neural Architectures Trained with Square Loss vs Cross-Entropy in Classification Tasks
Jun 12, 2020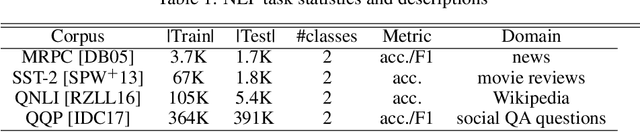
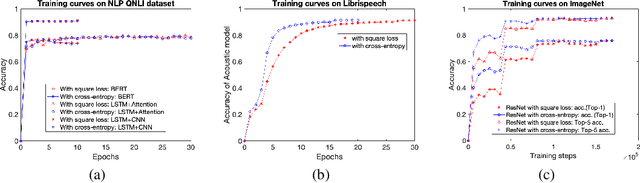
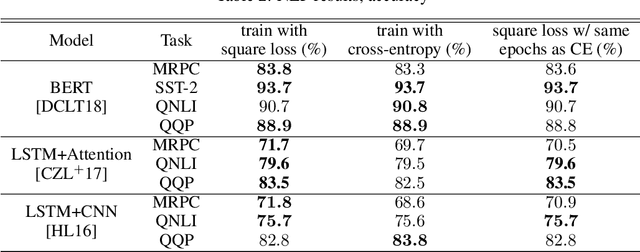
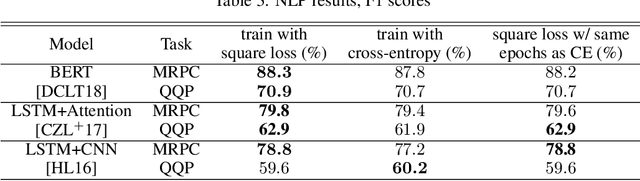
Modern neural architectures for classification tasks are trained using the cross-entropy loss, which is believed to be empirically superior to the square loss. In this work we provide evidence indicating that this belief may not be well-founded. We explore several major neural architectures and a range of standard benchmark datasets for NLP, automatic speech recognition (ASR) and computer vision tasks to show that these architectures, with the same hyper-parameter settings as reported in the literature, perform comparably or better when trained with the square loss, even after equalizing computational resources. Indeed, we observe that the square loss produces better results in the dominant majority of NLP and ASR experiments. Cross-entropy appears to have a slight edge on computer vision tasks. We argue that there is little compelling empirical or theoretical evidence indicating a clear-cut advantage to the cross-entropy loss. Indeed, in our experiments, performance on nearly all non-vision tasks can be improved, sometimes significantly, by switching to the square loss. We posit that training using the square loss for classification needs to be a part of best practices of modern deep learning on equal footing with cross-entropy.
Kernel Machines Beat Deep Neural Networks on Mask-based Single-channel Speech Enhancement
Nov 06, 2018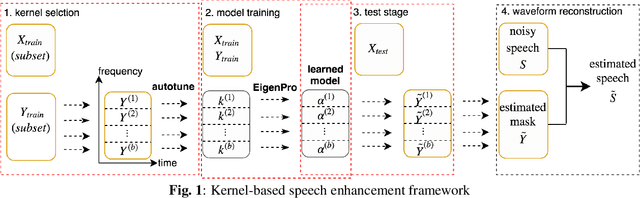
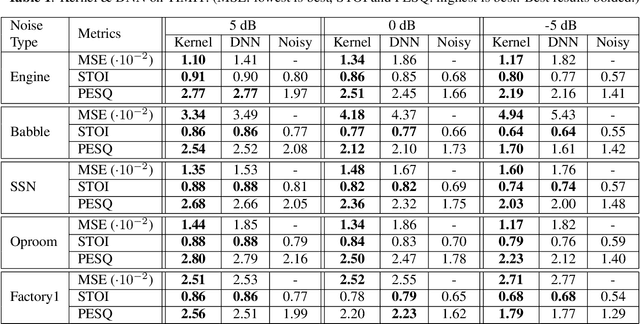
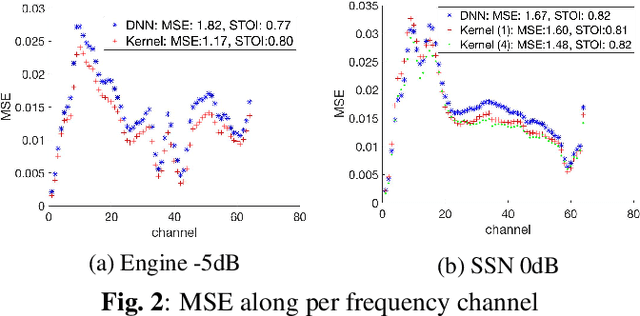
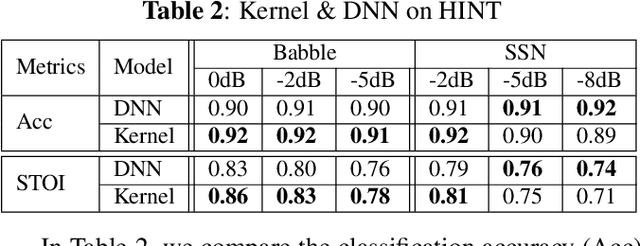
We apply a fast kernel method for mask-based single-channel speech enhancement. Specifically, our method solves a kernel regression problem associated to a non-smooth kernel function (exponential power kernel) with a highly efficient iterative method (EigenPro). Due to the simplicity of this method, its hyper-parameters such as kernel bandwidth can be automatically and efficiently selected using line search with subsamples of training data. We observe an empirical correlation between the regression loss (mean square error) and regular metrics for speech enhancement. This observation justifies our training target and motivates us to achieve lower regression loss by training separate kernel model per frequency subband. We compare our method with the state-of-the-art deep neural networks on mask-based HINT and TIMIT. Experimental results show that our kernel method consistently outperforms deep neural networks while requiring less training time.