 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Curved Monopole Antenna for HF Radar with Enhanced Gain and Bandwidth
Mar 08, 2026This paper presents the design and simulation of a new curved monopole antenna optimized for skywave HF radar applications, with a systematic investigation of the effects of curvature and fixed-section length on antenna performance. The proposed design achieves improved impedance matching, broader bandwidth, and enhanced realized gain compared to a conventional quarter-wavelength monopole at 15 MHz. Parametric analysis shows that fully bending the monopole degrades performance, whereas introducing a straight section and carefully optimizing the curvature enables a 18.5% gain increase and a 400 kHz bandwidth expansion. The single-element design is further extended to a 12-element linear array with 0.45λ spacing (where λ is the wavelength), demonstrating stable embedded-element behavior and improved low-to- moderate elevation gain for skywave over-the-horizon radar operation. At θ = 30°, the proposed array achieves 14.04 dBi compared to 13.11 dBi for the reference array, corresponding to 24% gain enhancement, which is significant in high-power HF radar systems. These results confirm that the proposed curved monopole antenna provides a compact, broadband, and scalable solution for next-generation HF radar arrays.
Selective Attention Federated Learning: Improving Privacy and Efficiency for Clinical Text Classification
Apr 16, 2025



Federated Learning (FL) faces major challenges regarding communication overhead and model privacy when training large language models (LLMs), especially in healthcare applications. To address these, we introduce Selective Attention Federated Learning (SAFL), a novel approach that dynamically fine-tunes only those transformer layers identified as attention-critical. By employing attention patterns to determine layer importance, SAFL significantly reduces communication bandwidth and enhances differential privacy resilience. Evaluations on clinical NLP benchmarks (i2b2 Clinical Concept Extraction and MIMIC-III discharge summaries) demonstrate that SAFL achieves competitive performance with centralized models while substantially improving communication efficiency and privacy preservation.
Federated Learning with Layer Skipping: Efficient Training of Large Language Models for Healthcare NLP
Apr 13, 2025



Federated learning (FL) enables collaborative model training across organizations without sharing raw data, addressing crucial privacy concerns in healthcare natural language processing (NLP). However, training large language models (LLMs) in federated settings faces significant challenges, including communication overhead and data heterogeneity. We propose Layer-Skipping Federated Learning, where only selected layers of a pre-trained LLM are fine-tuned across clients while others remain frozen. Applied to LLaMA 3.2-1B, our approach reduces communication costs by approximately 70% while maintaining performance within 2% of centralized training. We evaluate our method on clinical NER and classification tasks using i2b2 and MIMIC-III datasets. Our experiments demonstrate that Layer-Skipping FL outperforms competitive baselines, handles non-IID clinical data distributions effectively, and shows robustness when combined with differential privacy. This approach represents a practical solution for privacy-preserving collaborative learning in healthcare NLP.
Confidence interval estimation of mixed oil length with conditional diffusion model
Jun 19, 2024



Accurately estimating the mixed oil length plays a big role in the economic benefit for oil pipeline network. While various proposed methods have tried to predict the mixed oil length, they often exhibit an extremely high probability (around 50\%) of underestimating it. This is attributed to their failure to consider the statistical variability inherent in the estimated length of mixed oil. To address such issues, we propose to use the conditional diffusion model to learn the distribution of the mixed oil length given pipeline features. Subsequently, we design a confidence interval estimation for the length of the mixed oil based on the pseudo-samples generated by the learned diffusion model. To our knowledge, we are the first to present an estimation scheme for confidence interval of the oil-mixing length that considers statistical variability, thereby reducing the possibility of underestimating it. When employing the upper bound of the interval as a reference for excluding the mixed oil, the probability of underestimation can be as minimal as 5\%, a substantial reduction compared to 50\%. Furthermore, utilizing the mean of the generated pseudo samples as the estimator for the mixed oil length enhances prediction accuracy by at least 10\% compared to commonly used methods.
Combining Topic Modeling with Grounded Theory: Case Studies of Project Collaboration
Jun 28, 2022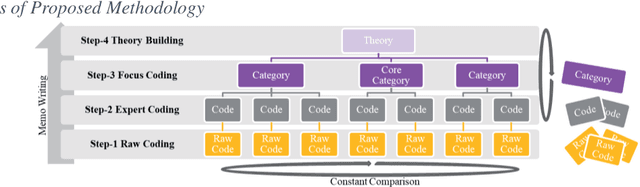
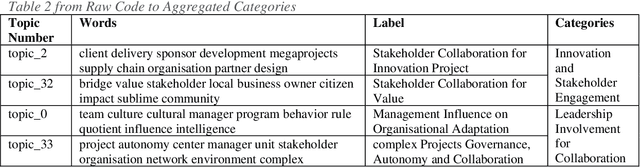
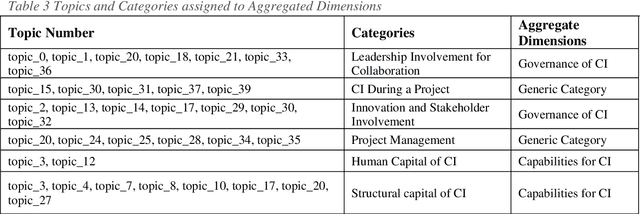
This paper proposes an Artificial Intelligence (AI) Grounded Theory for management studies. We argue that this novel and rigorous approach that embeds topic modelling will lead to the latent knowledge to be found. We illustrate this abductive method using 51 case studies of collaborative innovation published by Project Management Institute (PMI). Initial results are presented and discussed that include 40 topics, 6 categories, 4 of which are core categories, and two new theories of project collaboration.