 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Thompson Sampling for Contextual Bandits
Oct 27, 2013Thompson Sampling, one of the oldest heuristics for solving multi-armed bandits, has recently been shown to demonstrate state-of-the-art performance. The empirical success has led to great interests in theoretical understanding of this heuristic. In this paper, we approach this problem in a way very different from existing efforts. In particular, motivated by the connection between Thompson Sampling and exponentiated updates, we propose a new family of algorithms called Generalized Thompson Sampling in the expert-learning framework, which includes Thompson Sampling as a special case. Similar to most expert-learning algorithms, Generalized Thompson Sampling uses a loss function to adjust the experts' weights. General regret bounds are derived, which are also instantiated to two important loss functions: square loss and logarithmic loss. In contrast to existing bounds, our results apply to quite general contextual bandits. More importantly, they quantify the effect of the "prior" distribution on the regret bounds.
Sample Complexity of Multi-task Reinforcement Learning
Sep 26, 2013
Transferring knowledge across a sequence of reinforcement-learning tasks is challenging, and has a number of important applications. Though there is encouraging empirical evidence that transfer can improve performance in subsequent reinforcement-learning tasks, there has been very little theoretical analysis. In this paper, we introduce a new multi-task algorithm for a sequence of reinforcement-learning tasks when each task is sampled independently from (an unknown) distribution over a finite set of Markov decision processes whose parameters are initially unknown. For this setting, we prove under certain assumptions that the per-task sample complexity of exploration is reduced significantly due to transfer compared to standard single-task algorithms. Our multi-task algorithm also has the desired characteristic that it is guaranteed not to exhibit negative transfer: in the worst case its per-task sample complexity is comparable to the corresponding single-task algorithm.
Sample-efficient Nonstationary Policy Evaluation for Contextual Bandits
Oct 16, 2012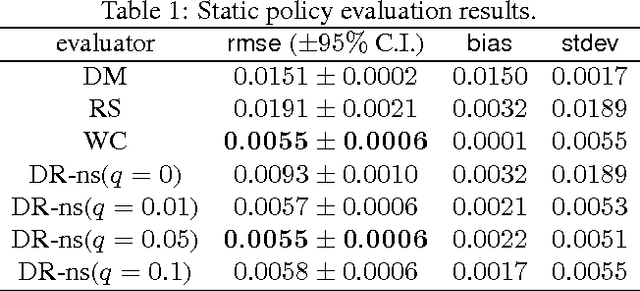
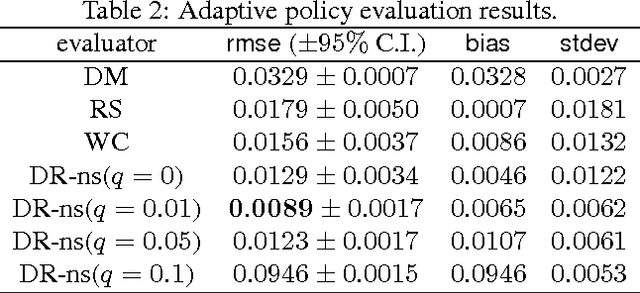
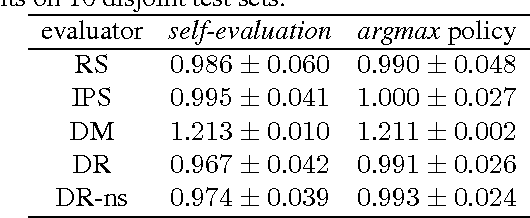
We present and prove properties of a new offline policy evaluator for an exploration learning setting which is superior to previous evaluators. In particular, it simultaneously and correctly incorporates techniques from importance weighting, doubly robust evaluation, and nonstationary policy evaluation approaches. In addition, our approach allows generating longer histories by careful control of a bias-variance tradeoff, and further decreases variance by incorporating information about randomness of the target policy. Empirical evidence from synthetic and realworld exploration learning problems shows the new evaluator successfully unifies previous approaches and uses information an order of magnitude more efficiently.
Incremental Model-based Learners With Formal Learning-Time Guarantees
Jun 27, 2012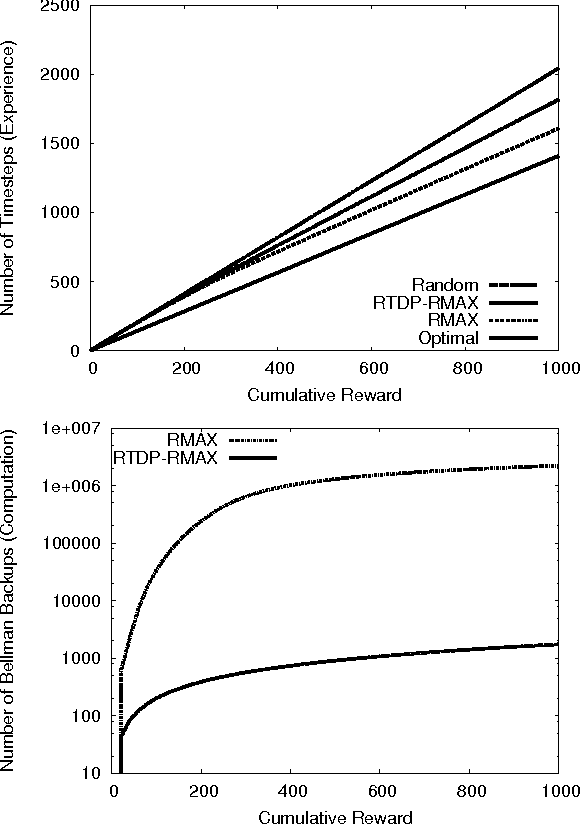
Model-based learning algorithms have been shown to use experience efficiently when learning to solve Markov Decision Processes (MDPs) with finite state and action spaces. However, their high computational cost due to repeatedly solving an internal model inhibits their use in large-scale problems. We propose a method based on real-time dynamic programming (RTDP) to speed up two model-based algorithms, RMAX and MBIE (model-based interval estimation), resulting in computationally much faster algorithms with little loss compared to existing bounds. Specifically, our two new learning algorithms, RTDP-RMAX and RTDP-IE, have considerably smaller computational demands than RMAX and MBIE. We develop a general theoretical framework that allows us to prove that both are efficient learners in a PAC (probably approximately correct) sense. We also present an experimental evaluation of these new algorithms that helps quantify the tradeoff between computational and experience demands.
CORL: A Continuous-state Offset-dynamics Reinforcement Learner
Jun 13, 2012

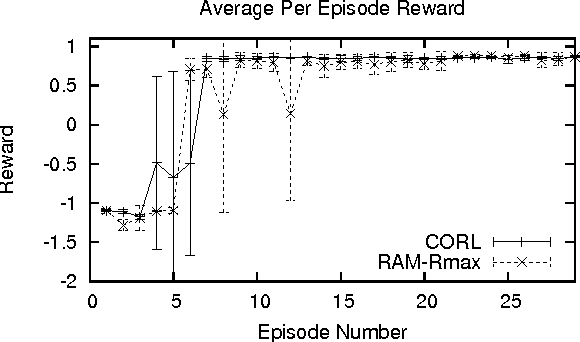
Continuous state spaces and stochastic, switching dynamics characterize a number of rich, realworld domains, such as robot navigation across varying terrain. We describe a reinforcementlearning algorithm for learning in these domains and prove for certain environments the algorithm is probably approximately correct with a sample complexity that scales polynomially with the state-space dimension. Unfortunately, no optimal planning techniques exist in general for such problems; instead we use fitted value iteration to solve the learned MDP, and include the error due to approximate planning in our bounds. Finally, we report an experiment using a robotic car driving over varying terrain to demonstrate that these dynamics representations adequately capture real-world dynamics and that our algorithm can be used to efficiently solve such problems.
A Bayesian Sampling Approach to Exploration in Reinforcement Learning
May 09, 2012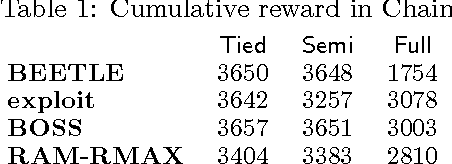
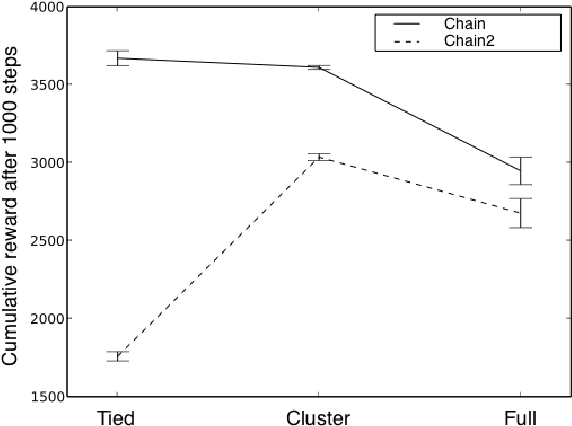
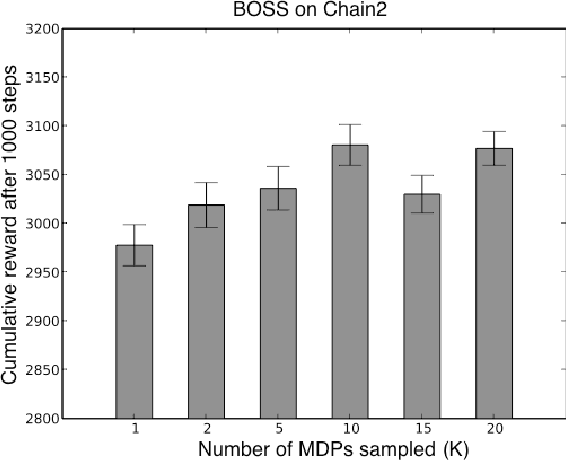
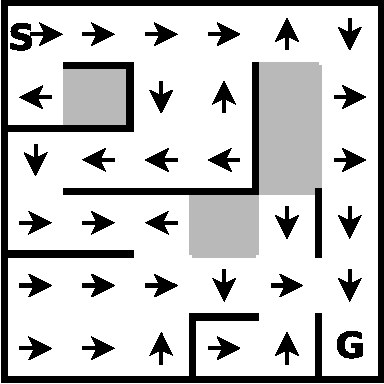
We present a modular approach to reinforcement learning that uses a Bayesian representation of the uncertainty over models. The approach, BOSS (Best of Sampled Set), drives exploration by sampling multiple models from the posterior and selecting actions optimistically. It extends previous work by providing a rule for deciding when to resample and how to combine the models. We show that our algorithm achieves nearoptimal reward with high probability with a sample complexity that is low relative to the speed at which the posterior distribution converges during learning. We demonstrate that BOSS performs quite favorably compared to state-of-the-art reinforcement-learning approaches and illustrate its flexibility by pairing it with a non-parametric model that generalizes across states.
A Contextual-Bandit Approach to Personalized News Article Recommendation
Mar 01, 2012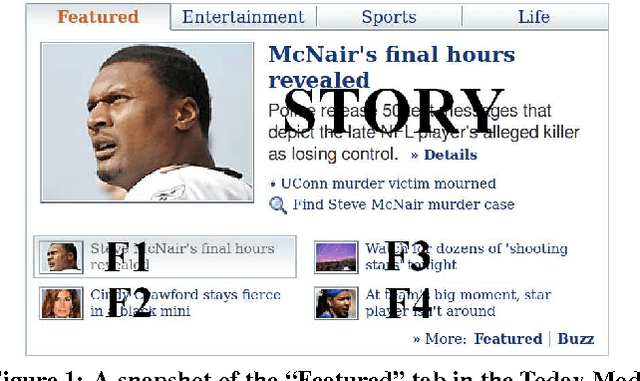
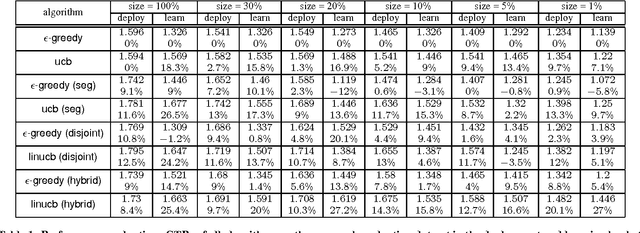
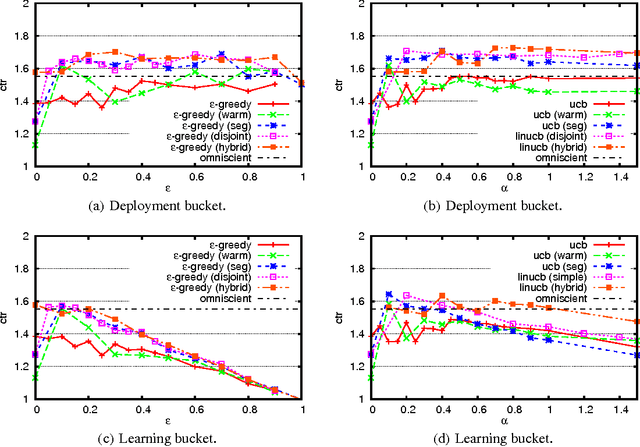
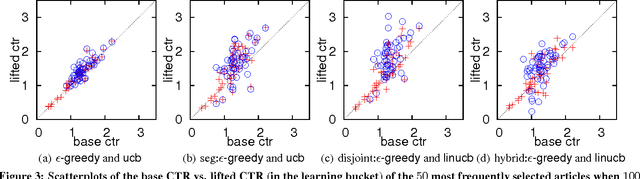
Personalized web services strive to adapt their services (advertisements, news articles, etc) to individual users by making use of both content and user information. Despite a few recent advances, this problem remains challenging for at least two reasons. First, web service is featured with dynamically changing pools of content, rendering traditional collaborative filtering methods inapplicable. Second, the scale of most web services of practical interest calls for solutions that are both fast in learning and computation. In this work, we model personalized recommendation of news articles as a contextual bandit problem, a principled approach in which a learning algorithm sequentially selects articles to serve users based on contextual information about the users and articles, while simultaneously adapting its article-selection strategy based on user-click feedback to maximize total user clicks. The contributions of this work are three-fold. First, we propose a new, general contextual bandit algorithm that is computationally efficient and well motivated from learning theory. Second, we argue that any bandit algorithm can be reliably evaluated offline using previously recorded random traffic. Finally, using this offline evaluation method, we successfully applied our new algorithm to a Yahoo! Front Page Today Module dataset containing over 33 million events. Results showed a 12.5% click lift compared to a standard context-free bandit algorithm, and the advantage becomes even greater when data gets more scarce.
* 10 pages, 5 figures
Unbiased Offline Evaluation of Contextual-bandit-based News Article Recommendation Algorithms
Mar 01, 2012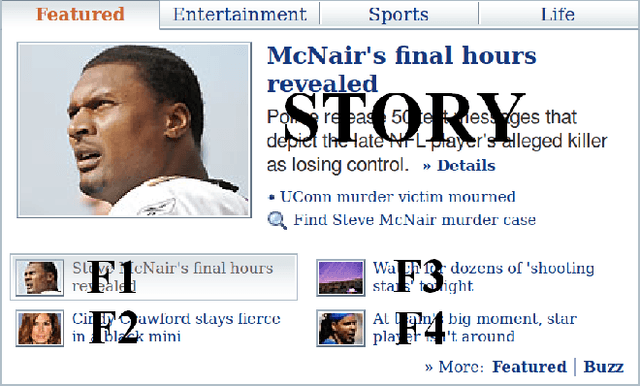

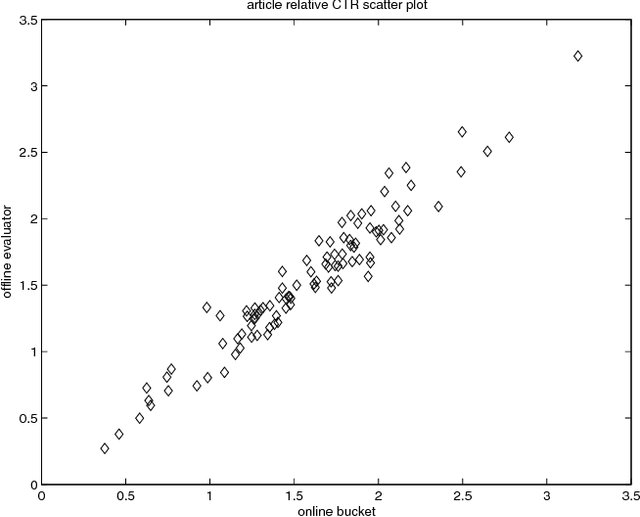
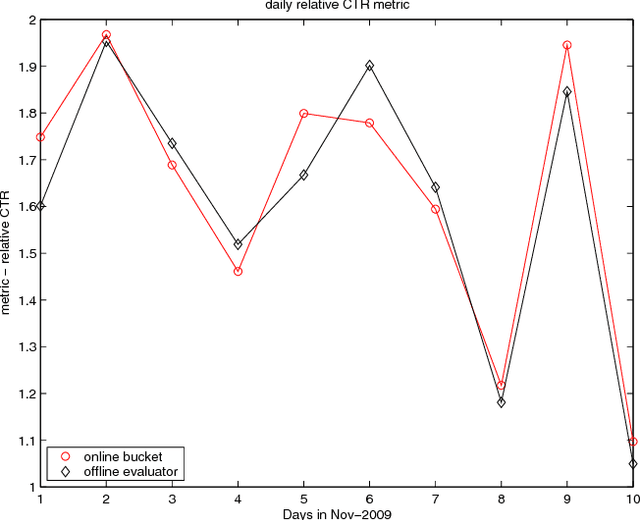
Contextual bandit algorithms have become popular for online recommendation systems such as Digg, Yahoo! Buzz, and news recommendation in general. \emph{Offline} evaluation of the effectiveness of new algorithms in these applications is critical for protecting online user experiences but very challenging due to their "partial-label" nature. Common practice is to create a simulator which simulates the online environment for the problem at hand and then run an algorithm against this simulator. However, creating simulator itself is often difficult and modeling bias is usually unavoidably introduced. In this paper, we introduce a \emph{replay} methodology for contextual bandit algorithm evaluation. Different from simulator-based approaches, our method is completely data-driven and very easy to adapt to different applications. More importantly, our method can provide provably unbiased evaluations. Our empirical results on a large-scale news article recommendation dataset collected from Yahoo! Front Page conform well with our theoretical results. Furthermore, comparisons between our offline replay and online bucket evaluation of several contextual bandit algorithms show accuracy and effectiveness of our offline evaluation method.
Contextual Bandit Algorithms with Supervised Learning Guarantees
Oct 27, 2011We address the problem of learning in an online, bandit setting where the learner must repeatedly select among $K$ actions, but only receives partial feedback based on its choices. We establish two new facts: First, using a new algorithm called Exp4.P, we show that it is possible to compete with the best in a set of $N$ experts with probability $1-\delta$ while incurring regret at most $O(\sqrt{KT\ln(N/\delta)})$ over $T$ time steps. The new algorithm is tested empirically in a large-scale, real-world dataset. Second, we give a new algorithm called VE that competes with a possibly infinite set of policies of VC-dimension $d$ while incurring regret at most $O(\sqrt{T(d\ln(T) + \ln (1/\delta))})$ with probability $1-\delta$. These guarantees improve on those of all previous algorithms, whether in a stochastic or adversarial environment, and bring us closer to providing supervised learning type guarantees for the contextual bandit setting.
Doubly Robust Policy Evaluation and Learning
May 06, 2011
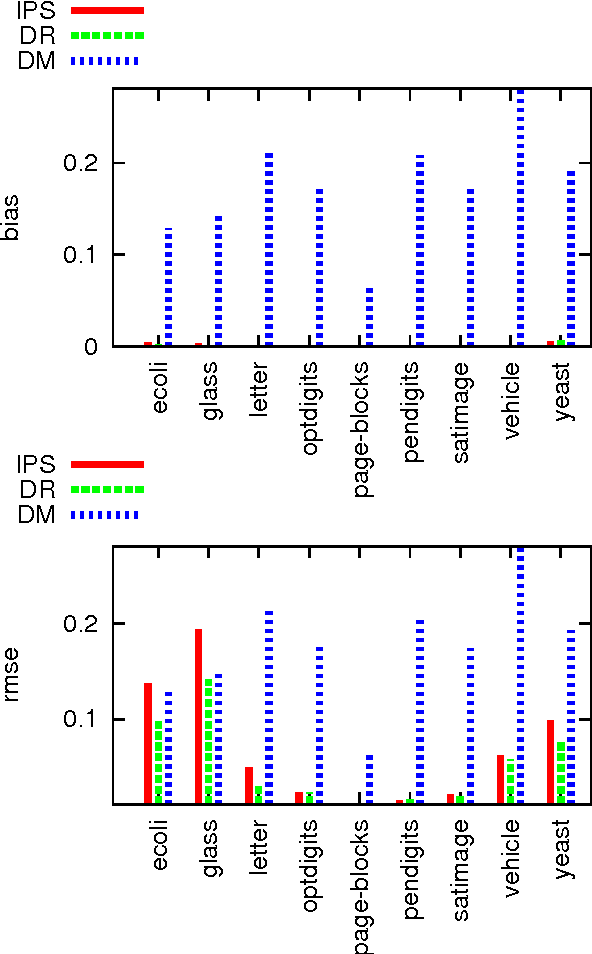
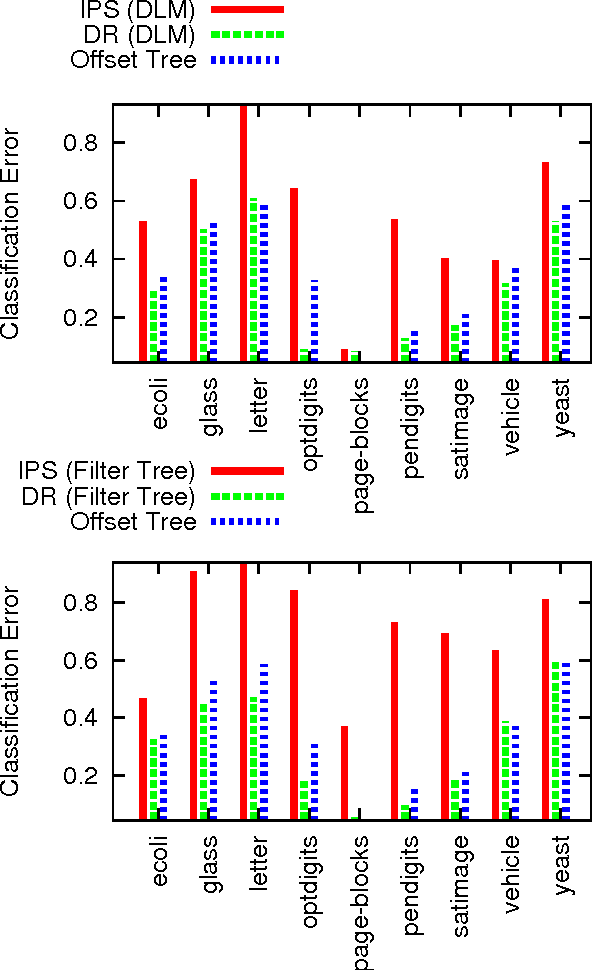
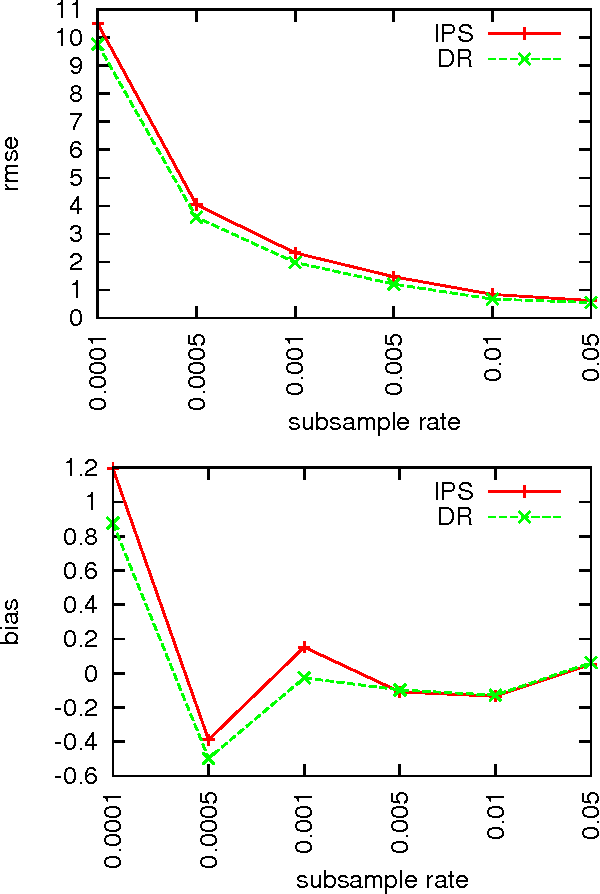
We study decision making in environments where the reward is only partially observed, but can be modeled as a function of an action and an observed context. This setting, known as contextual bandits, encompasses a wide variety of applications including health-care policy and Internet advertising. A central task is evaluation of a new policy given historic data consisting of contexts, actions and received rewards. The key challenge is that the past data typically does not faithfully represent proportions of actions taken by a new policy. Previous approaches rely either on models of rewards or models of the past policy. The former are plagued by a large bias whereas the latter have a large variance. In this work, we leverage the strength and overcome the weaknesses of the two approaches by applying the doubly robust technique to the problems of policy evaluation and optimization. We prove that this approach yields accurate value estimates when we have either a good (but not necessarily consistent) model of rewards or a good (but not necessarily consistent) model of past policy. Extensive empirical comparison demonstrates that the doubly robust approach uniformly improves over existing techniques, achieving both lower variance in value estimation and better policies. As such, we expect the doubly robust approach to become common practice.