 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Adversarial Robustness of Subspace Learning
Aug 17, 2019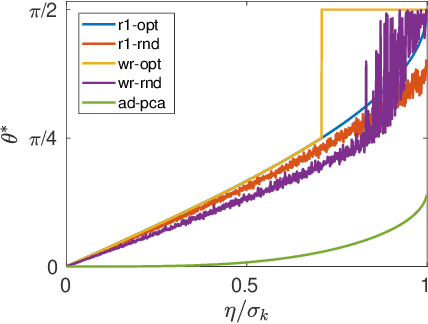
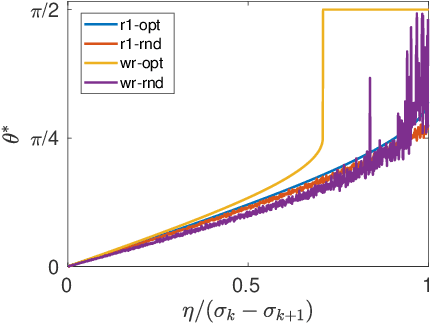
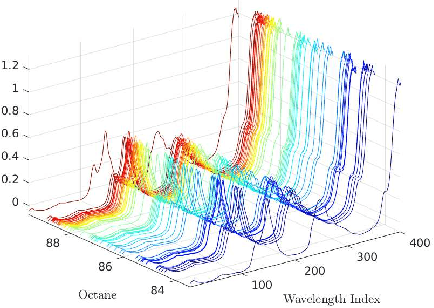
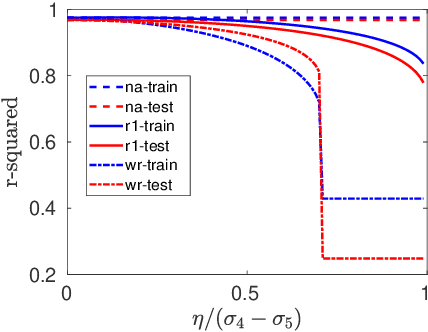
In this paper, we study the adversarial robustness of subspace learning problems. Different from the assumptions made in existing work on robust subspace learning where data samples are contaminated by gross sparse outliers or small dense noises, we consider a more powerful adversary who can first observe the data matrix and then intentionally modify the whole data matrix. We first characterize the optimal rank-one attack strategy that maximizes the subspace distance between the subspace learned from the original data matrix and that learned from the modified data matrix. We then generalize the study to the scenario without the rank constraint and characterize the corresponding optimal attack strategy. Our analysis shows that the optimal strategies depend on the singular values of the original data matrix and the adversary's energy budget. Finally, we provide numerical experiments and practical applications to demonstrate the efficiency of the attack strategies.
On the Adversarial Robustness of Multivariate Robust Estimation
Mar 27, 2019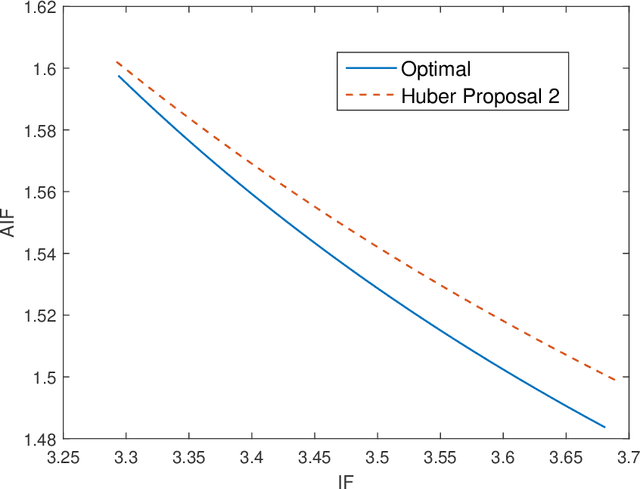
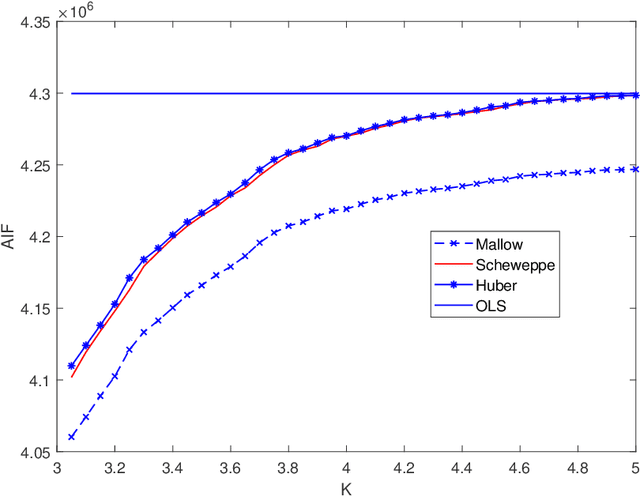
In this paper, we investigate the adversarial robustness of multivariate $M$-Estimators. In the considered model, after observing the whole dataset, an adversary can modify all data points with the goal of maximizing inference errors. We use adversarial influence function (AIF) to measure the asymptotic rate at which the adversary can change the inference result. We first characterize the adversary's optimal modification strategy and its corresponding AIF. From the defender's perspective, we would like to design an estimator that has a small AIF. For the case of joint location and scale estimation problem, we characterize the optimal $M$-estimator that has the smallest AIF. We further identify a tradeoff between robustness against adversarial modifications and robustness against outliers, and derive the optimal $M$-estimator that achieves the best tradeoff.
How did Donald Trump Surprisingly Win the 2016 United States Presidential Election? an Information-Theoretic Perspective
Dec 31, 2018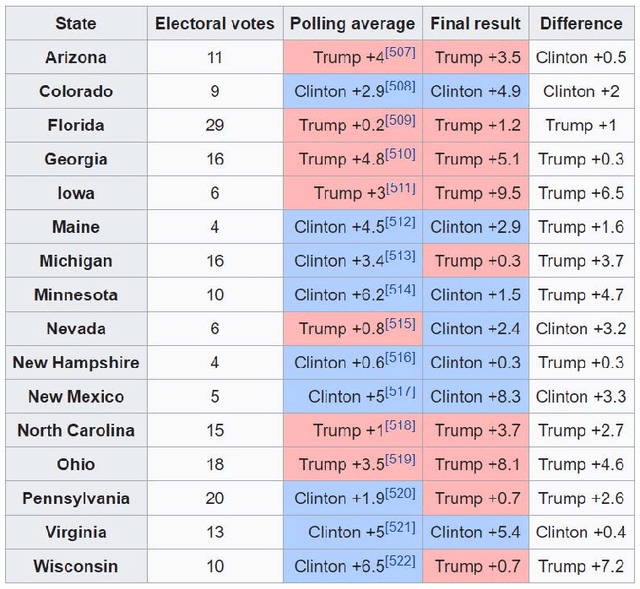
Donald Trump was lagging behind in nearly all opinion polls leading up to the 2016 US presidential election, but he surprisingly won the election. This raises the following important questions: 1) why most opinion polls were not accurate in 2016? and 2) how to improve the accuracies of opinion polls? In this paper, we study the inaccuracies of opinion polls in the 2016 election through the lens of information theory. We first propose a general framework of parameter estimation, called clean sensing (polling), which performs optimal parameter estimation with sensing cost constraints, from heterogeneous and potentially distorted data sources. We then cast the opinion polling as a problem of parameter estimation from potentially distorted heterogeneous data sources, and derive the optimal polling strategy using heterogenous and possibly distorted data under cost constraints. Our results show that a larger number of data samples do not necessarily lead to better polling accuracy, which give a possible explanation of the inaccuracies of opinion polls in 2016. The optimal sensing strategy should instead optimally allocate sensing resources over heterogenous data sources according to several factors including data quality, and, moreover, for a particular data source, it should strike an optimal balance between the quality of data samples, and the quantity of data samples. As a byproduct of this research, in a general setting, we derive a group of new lower bounds on the mean-squared errors of general unbiased and biased parameter estimators. These new lower bounds can be tighter than the classical Cram\'{e}r-Rao bound (CRB) and Chapman-Robbins bound. Our derivations are via studying the Lagrange dual problems of certain convex programs. The classical Cram\'{e}r-Rao bound and Chapman-Robbins bound follow naturally from our results for special cases of these convex programs.
Quick Best Action Identification in Linear Bandit Problems
Dec 02, 2018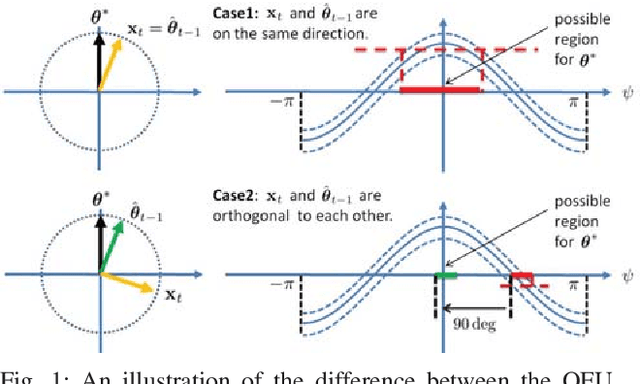
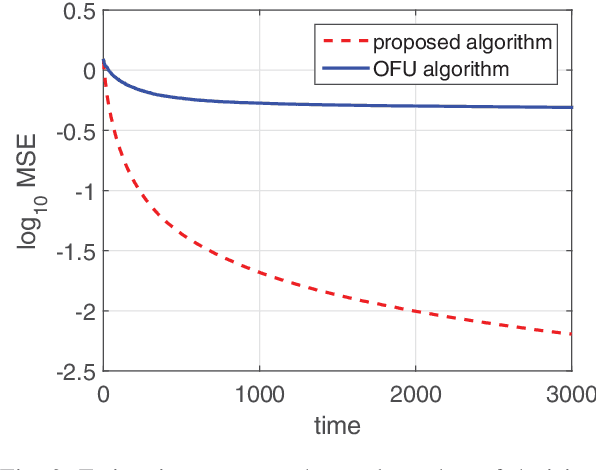
In this paper, we consider a best action identification problem in the stochastic linear bandit setup with a fixed confident constraint. In the considered best action identification problem, instead of minimizing the accumulative regret as done in existing works, the learner aims to obtain an accurate estimate of the underlying parameter based on his action and reward sequences. To improve the estimation efficiency, the learner is allowed to select his action based his historical information; hence the whole procedure is designed in a sequential adaptive manner. We first show that the existing algorithms designed to minimize the accumulative regret is not a consistent estimator and hence is not a good policy for our problem. We then characterize a lower bound on the estimation error for any policy. We further design a simple policy and show that the estimation error of the designed policy achieves the same scaling order as that of the derived lower bound.
Network Constrained Distributed Dual Coordinate Ascent for Machine Learning
Oct 30, 2018
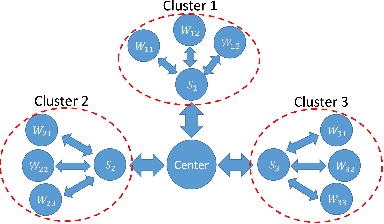
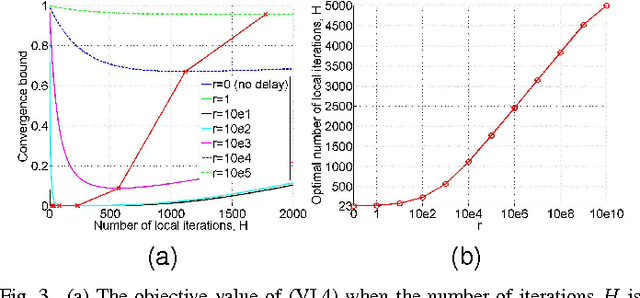
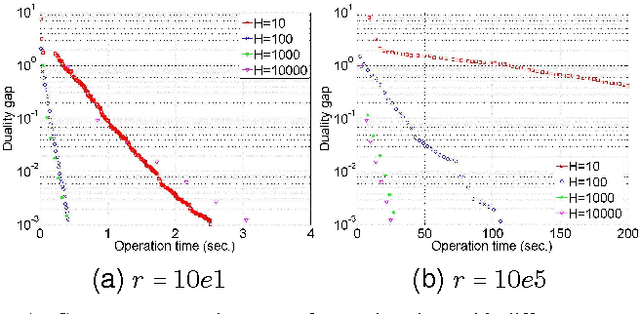
With explosion of data size and limited storage space at a single location, data are often distributed at different locations. We thus face the challenge of performing large-scale machine learning from these distributed data through communication networks. In this paper, we study how the network communication constraints will impact the convergence speed of distributed machine learning optimization algorithms. In particular, we give the convergence rate analysis of the distributed dual coordinate ascent in a general tree structured network. Furthermore, by considering network communication delays, we optimize the network-constrained dual coordinate ascent algorithms to maximize its convergence speed. Our results show that under different network communication delays, to achieve maximum convergence speed, one needs to adopt delay-dependent numbers of local and global iterations for distributed dual coordinate ascent.
Analysis of KNN Information Estimators for Smooth Distributions
Oct 27, 2018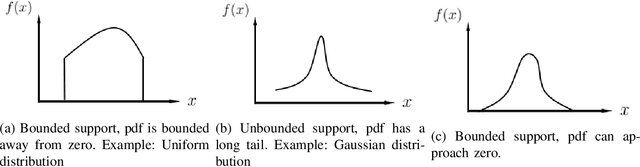
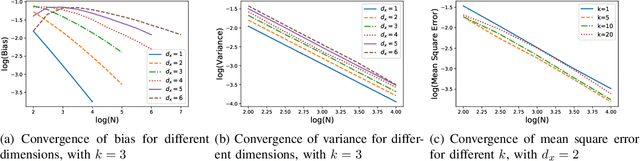
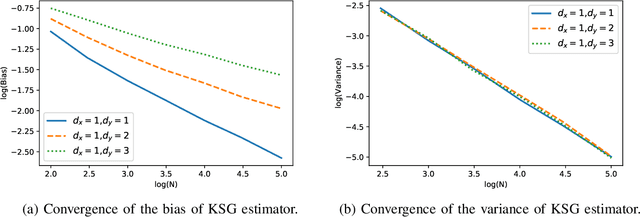

KSG mutual information estimator, which is based on the distances of each sample to its k-th nearest neighbor, is widely used to estimate mutual information between two continuous random variables. Existing work has analyzed the convergence rate of this estimator for random variables whose densities are bounded away from zero in its support. In practice, however, KSG estimator also performs well for a much broader class of distributions, including not only those with bounded support and densities bounded away from zero, but also those with bounded support but densities approaching zero, and those with unbounded support. In this paper, we analyze the convergence rate of the error of KSG estimator for smooth distributions, whose support of density can be both bounded and unbounded. As KSG mutual information estimator can be viewed as an adaptive recombination of KL entropy estimators, in our analysis, we also provide convergence analysis of KL entropy estimator for a broad class of distributions.
On Randomized Distributed Coordinate Descent with Quantized Updates
Jan 20, 2017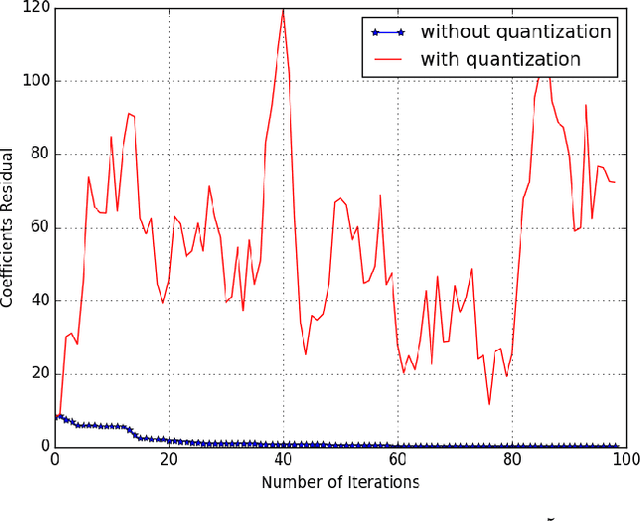
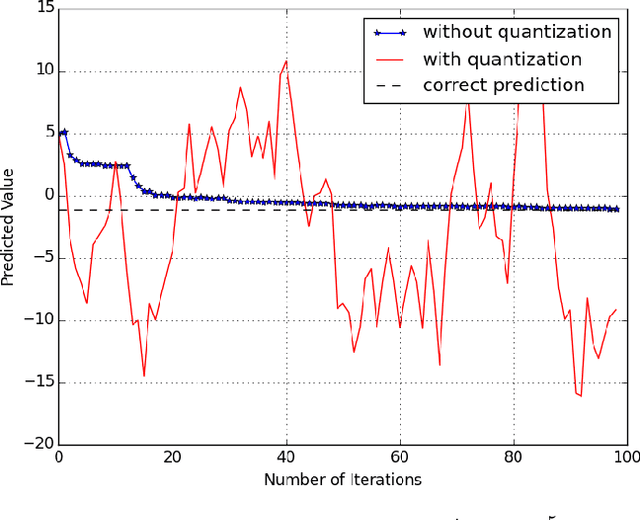
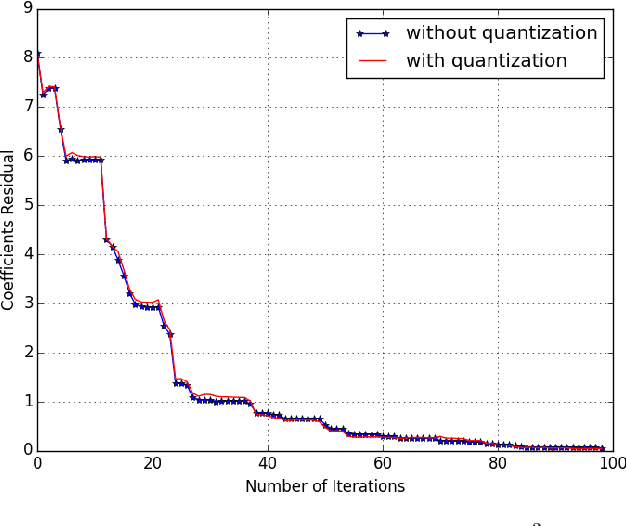
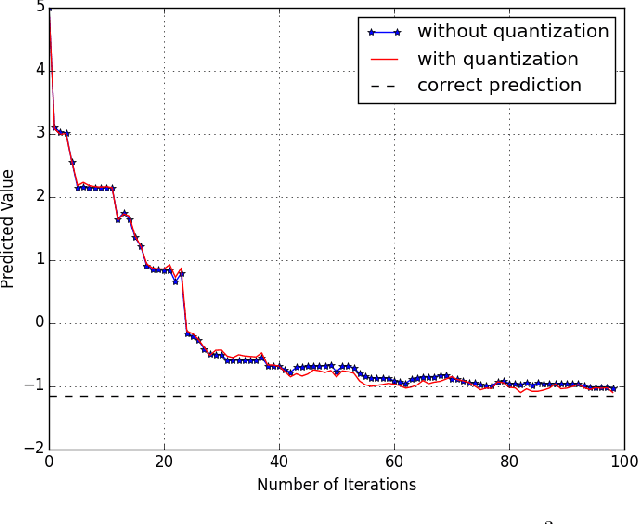
In this paper, we study the randomized distributed coordinate descent algorithm with quantized updates. In the literature, the iteration complexity of the randomized distributed coordinate descent algorithm has been characterized under the assumption that machines can exchange updates with an infinite precision. We consider a practical scenario in which the messages exchange occurs over channels with finite capacity, and hence the updates have to be quantized. We derive sufficient conditions on the quantization error such that the algorithm with quantized update still converge. We further verify our theoretical results by running an experiment, where we apply the algorithm with quantized updates to solve a linear regression problem.
Are Slepian-Wolf Rates Necessary for Distributed Parameter Estimation?
Nov 10, 2015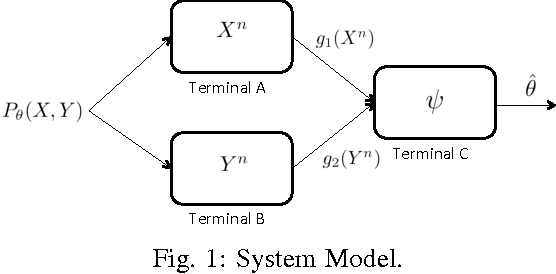


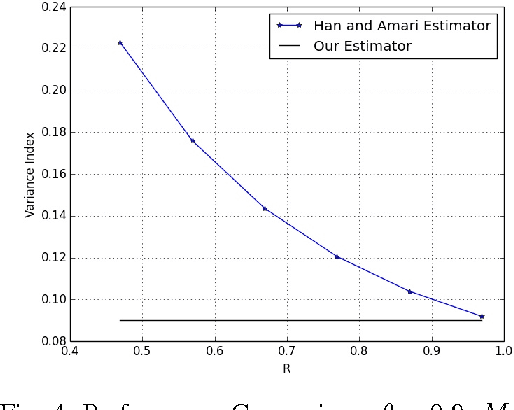
We consider a distributed parameter estimation problem, in which multiple terminals send messages related to their local observations using limited rates to a fusion center who will obtain an estimate of a parameter related to observations of all terminals. It is well known that if the transmission rates are in the Slepian-Wolf region, the fusion center can fully recover all observations and hence can construct an estimator having the same performance as that of the centralized case. One natural question is whether Slepian-Wolf rates are necessary to achieve the same estimation performance as that of the centralized case. In this paper, we show that the answer to this question is negative. We establish our result by explicitly constructing an asymptotically minimum variance unbiased estimator (MVUE) that has the same performance as that of the optimal estimator in the centralized case while requiring information rates less than the conditions required in the Slepian-Wolf rate region.
Precise Phase Transition of Total Variation Minimization
Sep 15, 2015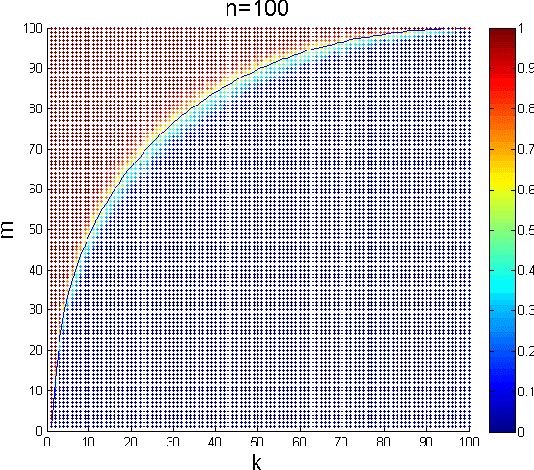
Characterizing the phase transitions of convex optimizations in recovering structured signals or data is of central importance in compressed sensing, machine learning and statistics. The phase transitions of many convex optimization signal recovery methods such as $\ell_1$ minimization and nuclear norm minimization are well understood through recent years' research. However, rigorously characterizing the phase transition of total variation (TV) minimization in recovering sparse-gradient signal is still open. In this paper, we fully characterize the phase transition curve of the TV minimization. Our proof builds on Donoho, Johnstone and Montanari's conjectured phase transition curve for the TV approximate message passing algorithm (AMP), together with the linkage between the minmax Mean Square Error of a denoising problem and the high-dimensional convex geometry for TV minimization.