 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance of regression models as a function of experiment noise
Jan 16, 2020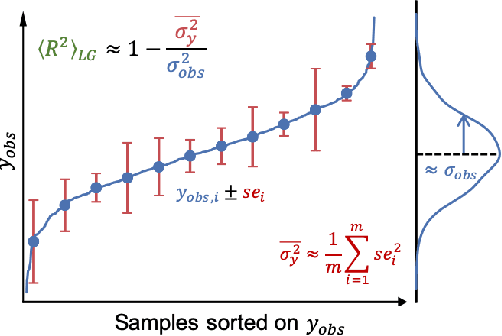
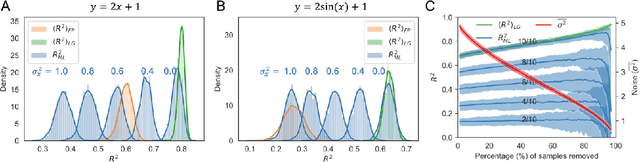
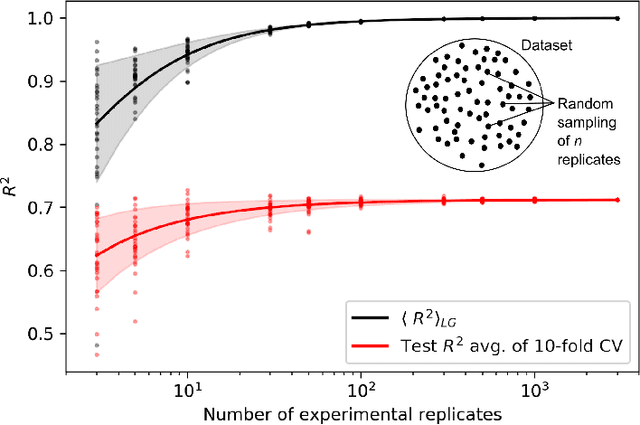
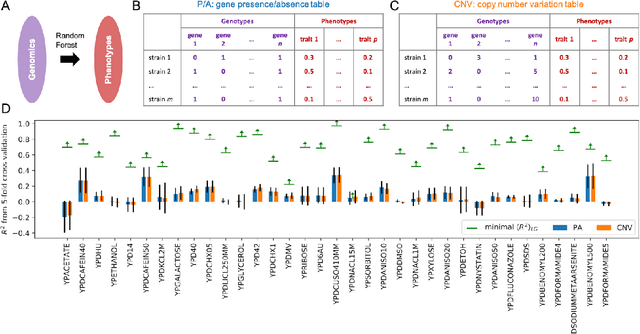
A challenge in developing machine learning regression models is that it is difficult to know whether maximal performance has been reached on a particular dataset, or whether further model improvement is possible. In biology this problem is particularly pronounced as sample labels (response variables) are typically obtained through experiments and therefore have experiment noise associated with them. Such label noise puts a fundamental limit to the performance attainable by regression models. We address this challenge by deriving a theoretical upper bound for the coefficient of determination (R2) for regression models. This theoretical upper bound depends only on the noise associated with the response variable in a dataset as well as its variance. The upper bound estimate was validated via Monte Carlo simulations and then used as a tool to bootstrap performance of regression models trained on biological datasets, including protein sequence data, transcriptomic data, and genomic data. Although we study biological datasets in this work, the new upper bound estimates will hold true for regression models from any research field or application area where response variables have associated noise.
Quick Best Action Identification in Linear Bandit Problems
Dec 02, 2018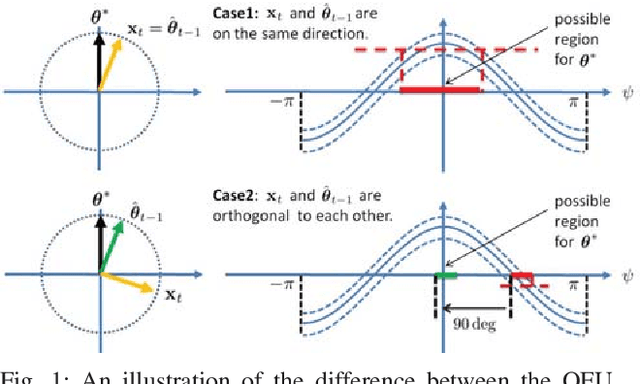
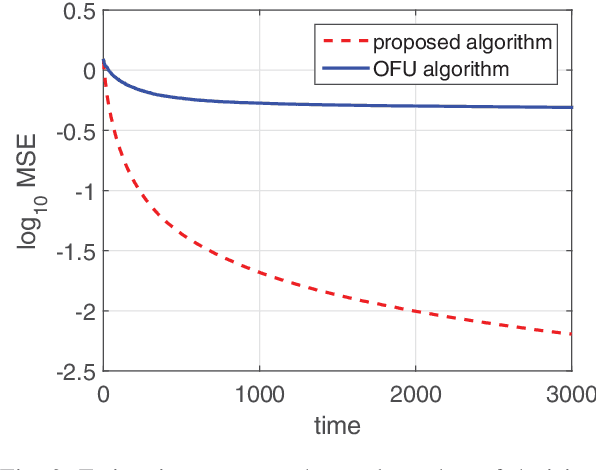
In this paper, we consider a best action identification problem in the stochastic linear bandit setup with a fixed confident constraint. In the considered best action identification problem, instead of minimizing the accumulative regret as done in existing works, the learner aims to obtain an accurate estimate of the underlying parameter based on his action and reward sequences. To improve the estimation efficiency, the learner is allowed to select his action based his historical information; hence the whole procedure is designed in a sequential adaptive manner. We first show that the existing algorithms designed to minimize the accumulative regret is not a consistent estimator and hence is not a good policy for our problem. We then characterize a lower bound on the estimation error for any policy. We further design a simple policy and show that the estimation error of the designed policy achieves the same scaling order as that of the derived lower bound.