 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow did Donald Trump Surprisingly Win the 2016 United States Presidential Election? an Information-Theoretic Perspective
Dec 31, 2018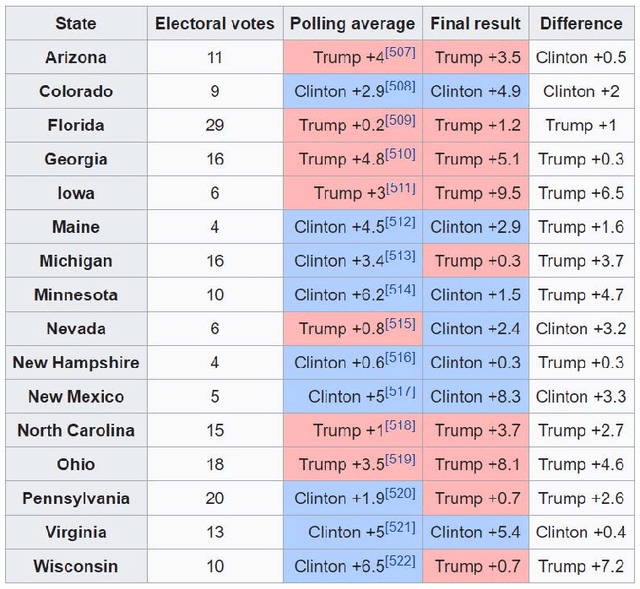
Donald Trump was lagging behind in nearly all opinion polls leading up to the 2016 US presidential election, but he surprisingly won the election. This raises the following important questions: 1) why most opinion polls were not accurate in 2016? and 2) how to improve the accuracies of opinion polls? In this paper, we study the inaccuracies of opinion polls in the 2016 election through the lens of information theory. We first propose a general framework of parameter estimation, called clean sensing (polling), which performs optimal parameter estimation with sensing cost constraints, from heterogeneous and potentially distorted data sources. We then cast the opinion polling as a problem of parameter estimation from potentially distorted heterogeneous data sources, and derive the optimal polling strategy using heterogenous and possibly distorted data under cost constraints. Our results show that a larger number of data samples do not necessarily lead to better polling accuracy, which give a possible explanation of the inaccuracies of opinion polls in 2016. The optimal sensing strategy should instead optimally allocate sensing resources over heterogenous data sources according to several factors including data quality, and, moreover, for a particular data source, it should strike an optimal balance between the quality of data samples, and the quantity of data samples. As a byproduct of this research, in a general setting, we derive a group of new lower bounds on the mean-squared errors of general unbiased and biased parameter estimators. These new lower bounds can be tighter than the classical Cram\'{e}r-Rao bound (CRB) and Chapman-Robbins bound. Our derivations are via studying the Lagrange dual problems of certain convex programs. The classical Cram\'{e}r-Rao bound and Chapman-Robbins bound follow naturally from our results for special cases of these convex programs.
Competitive Machine Learning: Best Theoretical Prediction vs Optimization
Mar 09, 2018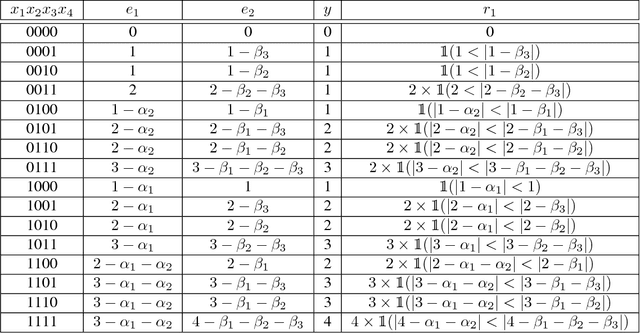

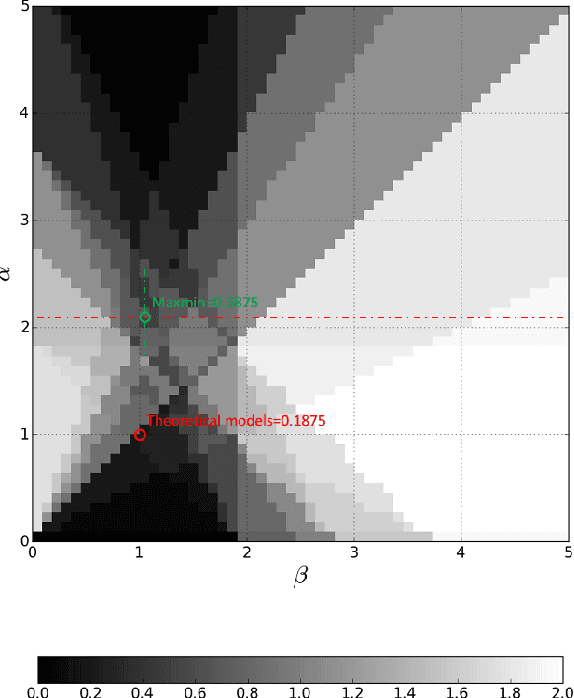

Machine learning is often used in competitive scenarios: Participants learn and fit static models, and those models compete in a shared platform. The common assumption is that in order to win a competition one has to have the best predictive model, i.e., the model with the smallest out-sample error. Is that necessarily true? Does the best theoretical predictive model for a target always yield the best reward in a competition? If not, can one take the best model and purposefully change it into a theoretically inferior model which in practice results in a higher competitive edge? How does that modification look like? And finally, if all participants modify their prediction models towards the best practical performance, who benefits the most? players with inferior models, or those with theoretical superiority? The main theme of this paper is to raise these important questions and propose a theoretical model to answer them. We consider a study case where two linear predictive models compete over a shared target. The model with the closest estimate gets the whole reward, which is equal to the absolute value of the target. We characterize the reward function of each model, and using a basic game theoretic approach, demonstrate that the inferior competitor can significantly improve his performance by choosing optimal model coefficients that are different from the best theoretical prediction. This is a preliminary study that emphasizes the fact that in many applications where predictive machine learning is at the service of competition, much can be gained from practical (back-testing) optimization of the model compared to static prediction improvement.