 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Selection Based on Wasserstein Distance
Nov 13, 2024This paper presents a novel feature selection method leveraging the Wasserstein distance to improve feature selection in machine learning. Unlike traditional methods based on correlation or Kullback-Leibler (KL) divergence, our approach uses the Wasserstein distance to assess feature similarity, inherently capturing class relationships and making it robust to noisy labels. We introduce a Markov blanket-based feature selection algorithm and demonstrate its effectiveness. Our analysis shows that the Wasserstein distance-based feature selection method effectively reduces the impact of noisy labels without relying on specific noise models. We provide a lower bound on its effectiveness, which remains meaningful even in the presence of noise. Experimental results across multiple datasets demonstrate that our approach consistently outperforms traditional methods, particularly in noisy settings.
On the Adversarial Robustness of LASSO Based Feature Selection
Oct 20, 2020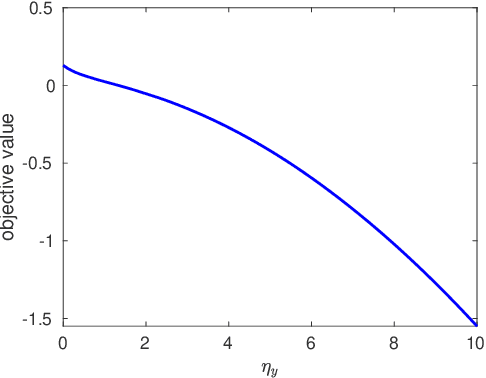
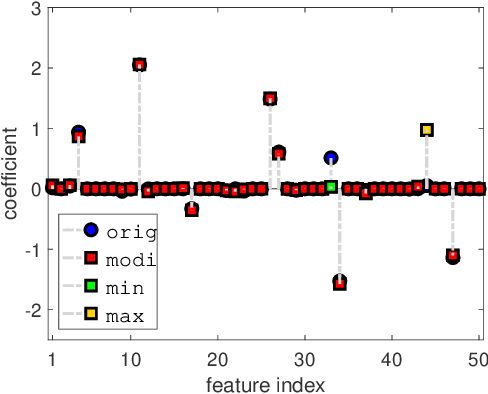
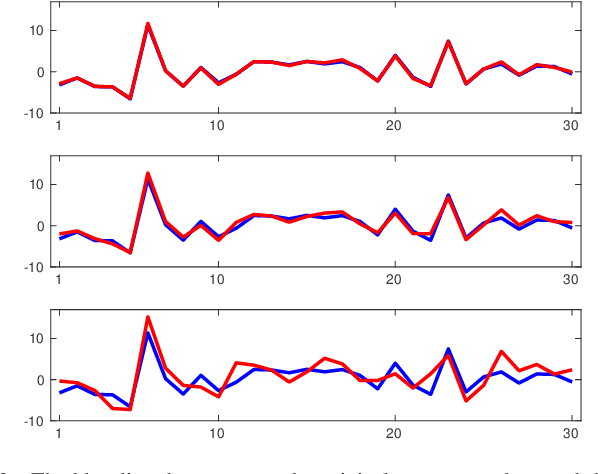
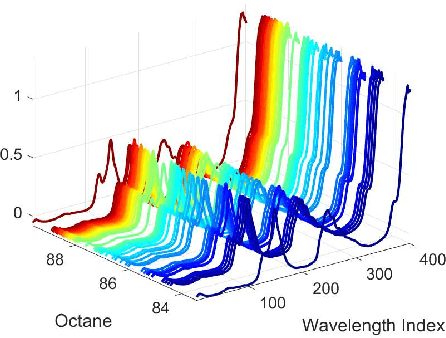
In this paper, we investigate the adversarial robustness of feature selection based on the $\ell_1$ regularized linear regression model, namely LASSO. In the considered model, there is a malicious adversary who can observe the whole dataset, and then will carefully modify the response values or the feature matrix in order to manipulate the selected features. We formulate the modification strategy of the adversary as a bi-level optimization problem. Due to the difficulty of the non-differentiability of the $\ell_1$ norm at the zero point, we reformulate the $\ell_1$ norm regularizer as linear inequality constraints. We employ the interior-point method to solve this reformulated LASSO problem and obtain the gradient information. Then we use the projected gradient descent method to design the modification strategy. In addition, We demonstrate that this method can be extended to other $\ell_1$ based feature selection methods, such as group LASSO and sparse group LASSO. Numerical examples with synthetic and real data illustrate that our method is efficient and effective.
Optimal Feature Manipulation Attacks Against Linear Regression
Feb 29, 2020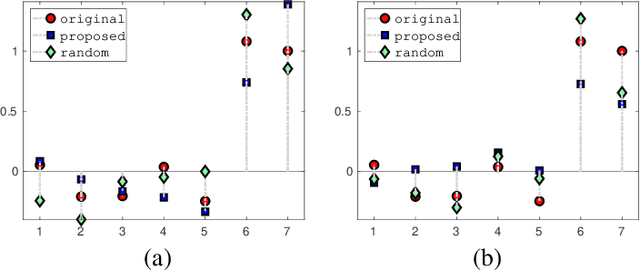
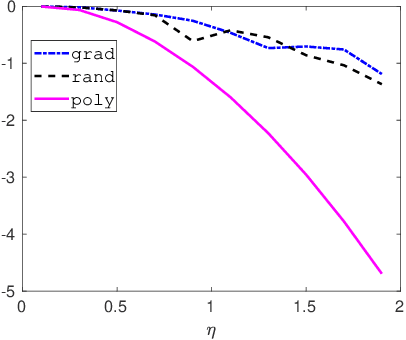
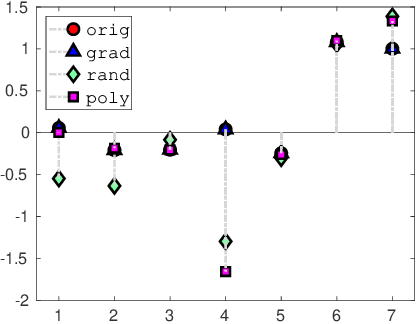
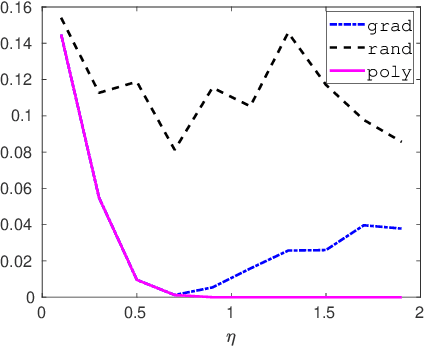
In this paper, we investigate how to manipulate the coefficients obtained via linear regression by adding carefully designed poisoning data points to the dataset or modify the original data points. Given the energy budget, we first provide the closed-form solution of the optimal poisoning data point when our target is modifying one designated regression coefficient. We then extend the analysis to the more challenging scenario where the attacker aims to change one particular regression coefficient while making others to be changed as small as possible. For this scenario, we introduce a semidefinite relaxation method to design the best attack scheme. Finally, we study a more powerful adversary who can perform a rank-one modification on the feature matrix. We propose an alternating optimization method to find the optimal rank-one modification matrix. Numerical examples are provided to illustrate the analytical results obtained in this paper.
On the Adversarial Robustness of Subspace Learning
Aug 17, 2019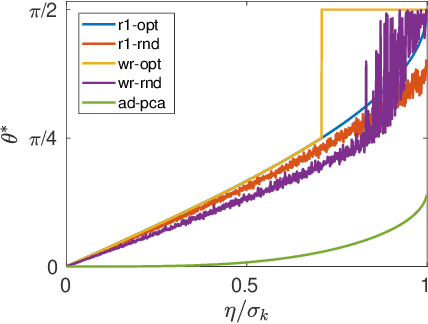
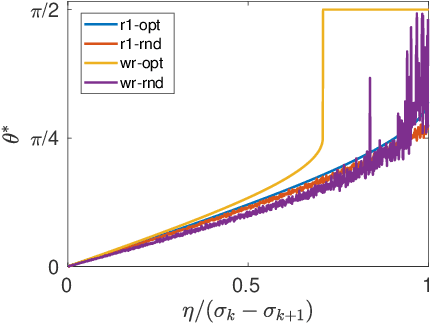
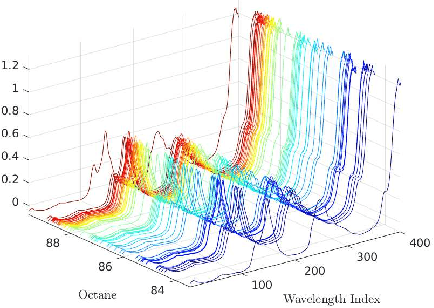
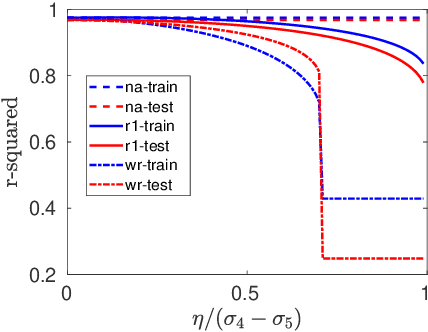
In this paper, we study the adversarial robustness of subspace learning problems. Different from the assumptions made in existing work on robust subspace learning where data samples are contaminated by gross sparse outliers or small dense noises, we consider a more powerful adversary who can first observe the data matrix and then intentionally modify the whole data matrix. We first characterize the optimal rank-one attack strategy that maximizes the subspace distance between the subspace learned from the original data matrix and that learned from the modified data matrix. We then generalize the study to the scenario without the rank constraint and characterize the corresponding optimal attack strategy. Our analysis shows that the optimal strategies depend on the singular values of the original data matrix and the adversary's energy budget. Finally, we provide numerical experiments and practical applications to demonstrate the efficiency of the attack strategies.