 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Contextually Fused Audio-visual Representations for Audio-visual Speech Recognition
Feb 15, 2022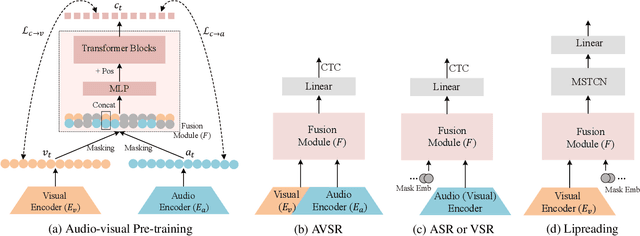
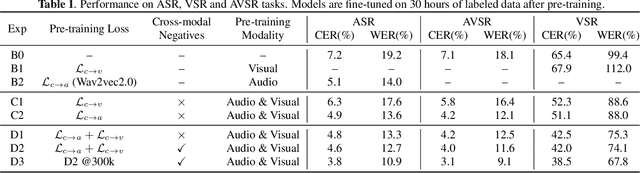
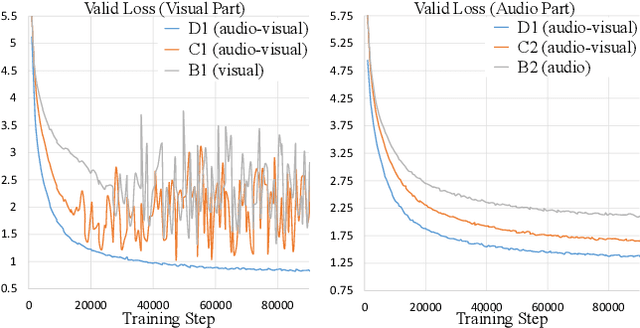
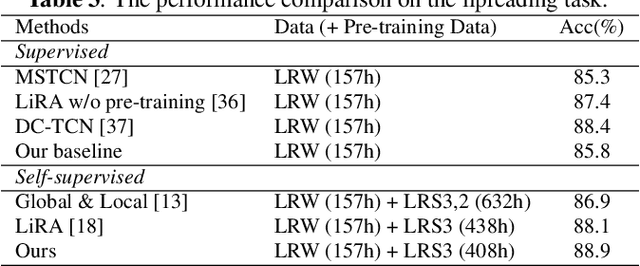
With the advance in self-supervised learning for audio and visual modalities, it has become possible to learn a robust audio-visual speech representation. This would be beneficial for improving the audio-visual speech recognition (AVSR) performance, as the multi-modal inputs contain more fruitful information in principle. In this paper, based on existing self-supervised representation learning methods for audio modality, we therefore propose an audio-visual representation learning approach. The proposed approach explores both the complementarity of audio-visual modalities and long-term context dependency using a transformer-based fusion module and a flexible masking strategy. After pre-training, the model is able to extract fused representations required by AVSR. Without loss of generality, it can be applied to single-modal tasks, e.g. audio/visual speech recognition by simply masking out one modality in the fusion module. The proposed pre-trained model is evaluated on speech recognition and lipreading tasks using one or two modalities, where the superiority is revealed.
Supervised and Self-supervised Pretraining Based COVID-19 Detection Using Acoustic Breathing/Cough/Speech Signals
Jan 22, 2022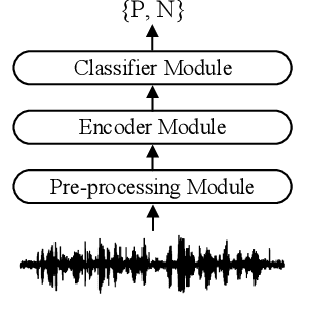
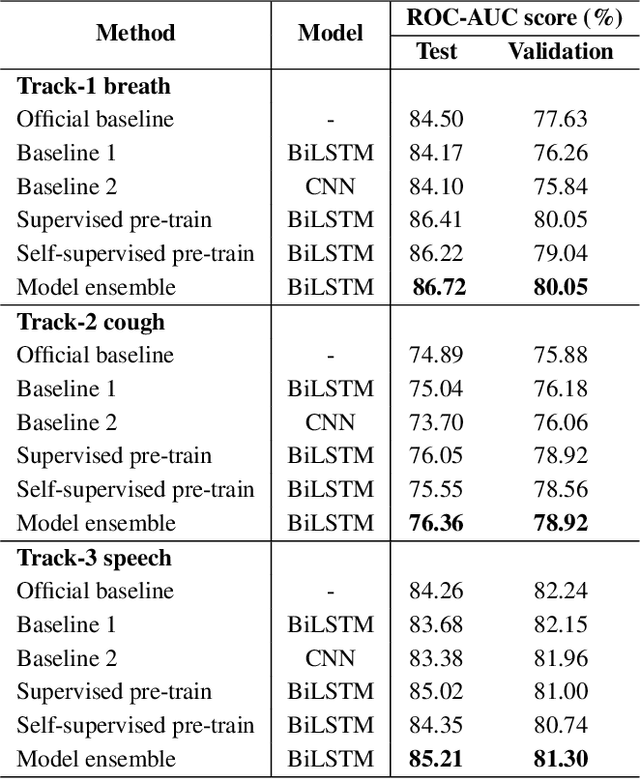
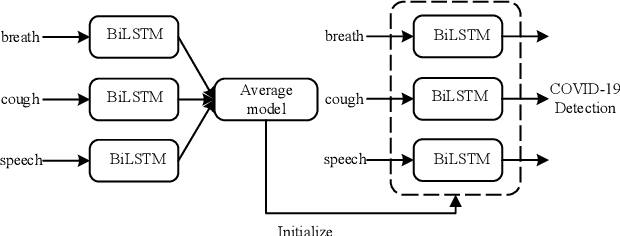
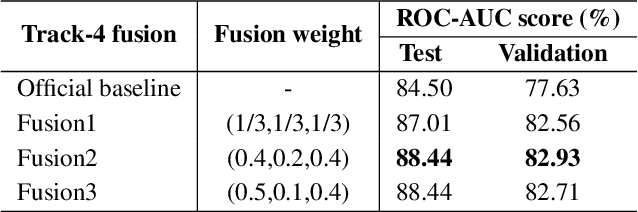
In this work, we propose a bi-directional long short-term memory (BiLSTM) network based COVID-19 detection method using breath/speech/cough signals. By using the acoustic signals to train the network, respectively, we can build individual models for three tasks, whose parameters are averaged to obtain an average model, which is then used as the initialization for the BiLSTM model training of each task. This initialization method can significantly improve the performance on the three tasks, which surpasses the official baseline results. Besides, we also utilize a public pre-trained model wav2vec2.0 and pre-train it using the official DiCOVA datasets. This wav2vec2.0 model is utilized to extract high-level features of the sound as the model input to replace conventional mel-frequency cepstral coefficients (MFCC) features. Experimental results reveal that using high-level features together with MFCC features can improve the performance. To further improve the performance, we also deploy some preprocessing techniques like silent segment removal, amplitude normalization and time-frequency mask. The proposed detection model is evaluated on the DiCOVA dataset and results show that our method achieves an area under curve (AUC) score of 88.44% on blind test in the fusion track.
A Noise-Robust Self-supervised Pre-training Model Based Speech Representation Learning for Automatic Speech Recognition
Jan 22, 2022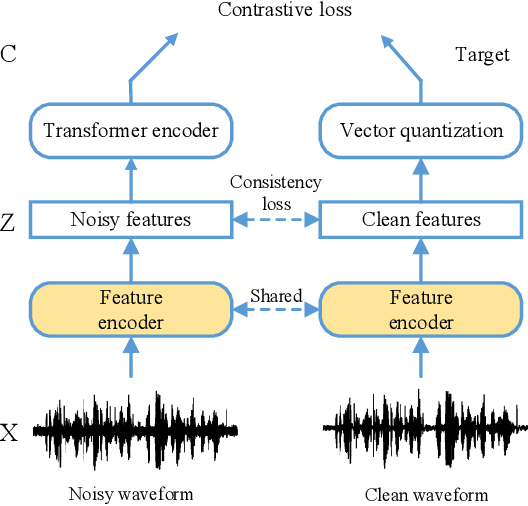
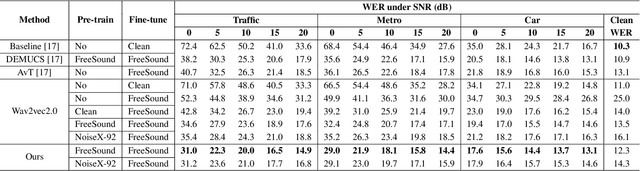
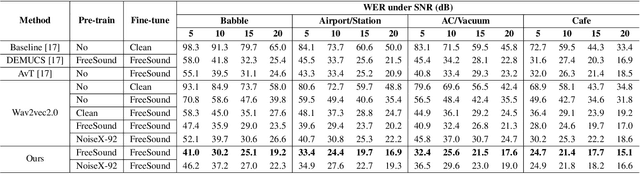
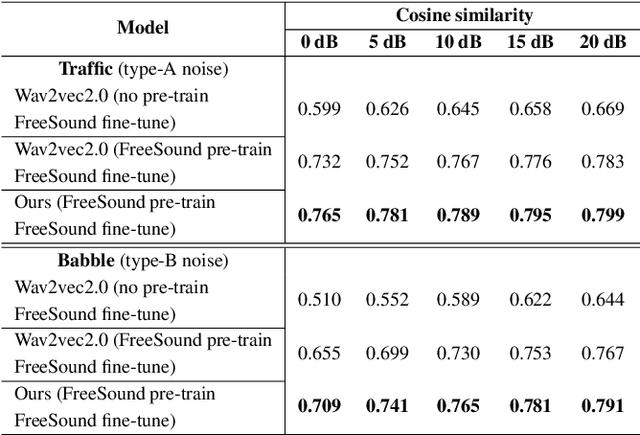
Wav2vec2.0 is a popular self-supervised pre-training framework for learning speech representations in the context of automatic speech recognition (ASR). It was shown that wav2vec2.0 has a good robustness against the domain shift, while the noise robustness is still unclear. In this work, we therefore first analyze the noise robustness of wav2vec2.0 via experiments. We observe that wav2vec2.0 pre-trained on noisy data can obtain good representations and thus improve the ASR performance on the noisy test set, which however brings a performance degradation on the clean test set. To avoid this issue, in this work we propose an enhanced wav2vec2.0 model. Specifically, the noisy speech and the corresponding clean version are fed into the same feature encoder, where the clean speech provides training targets for the model. Experimental results reveal that the proposed method can not only improve the ASR performance on the noisy test set which surpasses the original wav2vec2.0, but also ensure a tiny performance decrease on the clean test set. In addition, the effectiveness of the proposed method is demonstrated under different types of noise conditions.
XLST: Cross-lingual Self-training to Learn Multilingual Representation for Low Resource Speech Recognition
Mar 15, 2021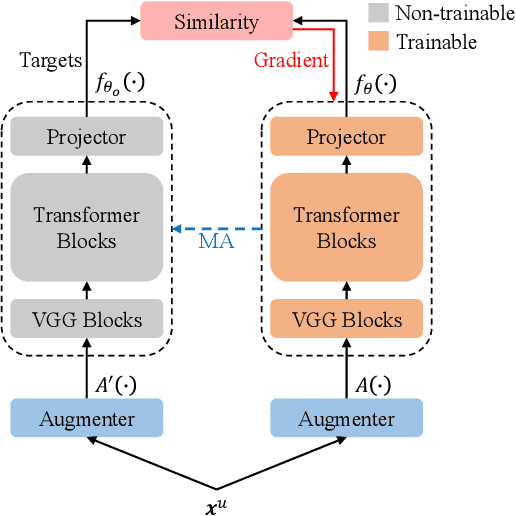
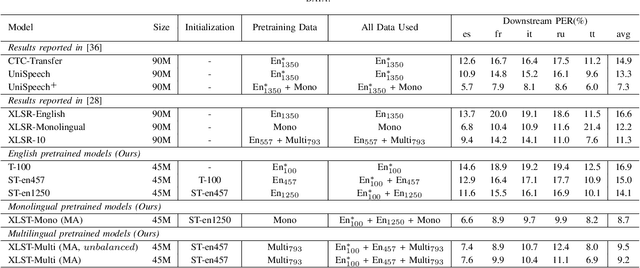
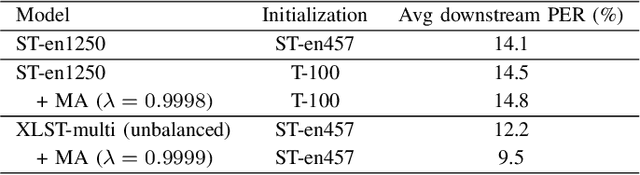

In this paper, we propose a weakly supervised multilingual representation learning framework, called cross-lingual self-training (XLST). XLST is able to utilize a small amount of annotated data from high-resource languages to improve the representation learning on multilingual un-annotated data. Specifically, XLST uses a supervised trained model to produce initial representations and another model to learn from them, by maximizing the similarity between output embeddings of these two models. Furthermore, the moving average mechanism and multi-view data augmentation are employed, which are experimentally shown to be crucial to XLST. Comprehensive experiments have been conducted on the CommonVoice corpus to evaluate the effectiveness of XLST. Results on 5 downstream low-resource ASR tasks shows that our multilingual pretrained model achieves relatively 18.6% PER reduction over the state-of-the-art self-supervised method, with leveraging additional 100 hours of annotated English data.
Lip-reading with Hierarchical Pyramidal Convolution and Self-Attention
Dec 28, 2020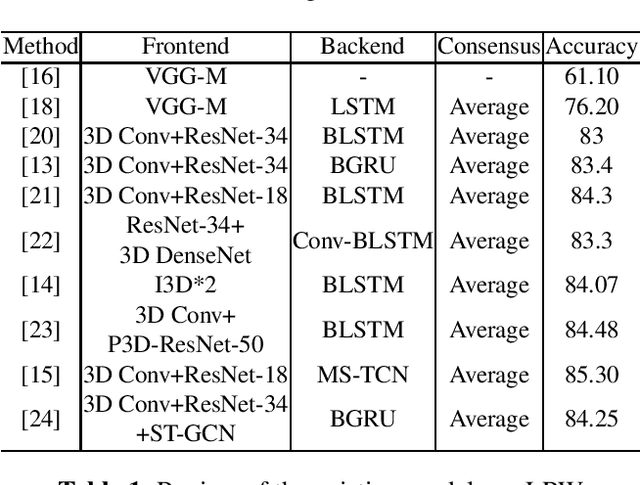
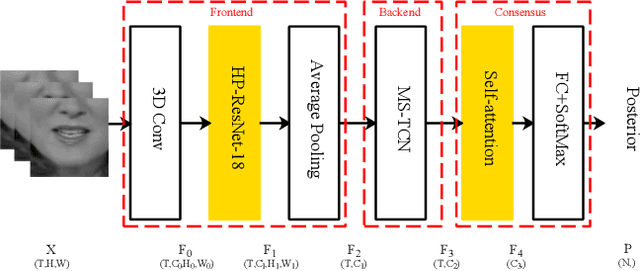
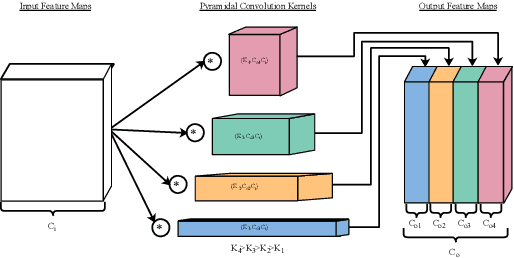
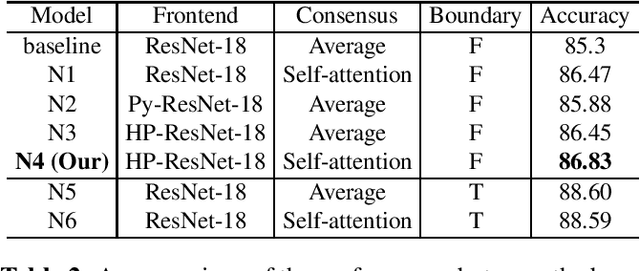
In this paper, we propose a novel deep learning architecture to improving word-level lip-reading. On the one hand, we first introduce the multi-scale processing into the spatial feature extraction for lip-reading. Specially, we proposed hierarchical pyramidal convolution (HPConv) to replace the standard convolution in original module, leading to improvements over the model's ability to discover fine-grained lip movements. On the other hand, we merge information in all time steps of the sequence by utilizing self-attention, to make the model pay more attention to the relevant frames. These two advantages are combined together to further enhance the model's classification power. Experiments on the Lip Reading in the Wild (LRW) dataset show that our proposed model has achieved 86.83% accuracy, yielding 1.53% absolute improvement over the current state-of-the-art. We also conducted extensive experiments to better understand the behavior of the proposed model.
Correlating Subword Articulation with Lip Shapes for Embedding Aware Audio-Visual Speech Enhancement
Sep 21, 2020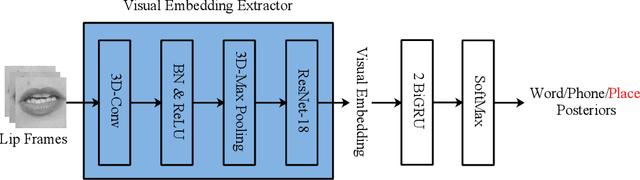
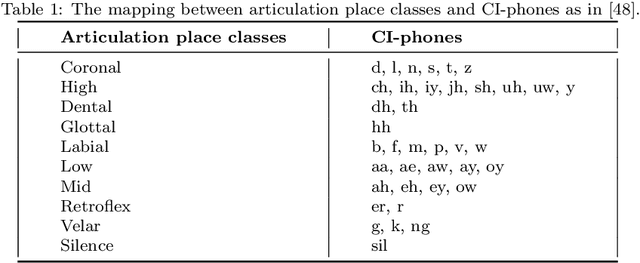

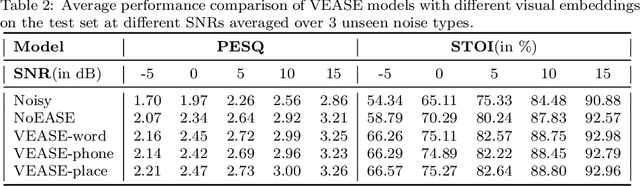
In this paper, we propose a visual embedding approach to improving embedding aware speech enhancement (EASE) by synchronizing visual lip frames at the phone and place of articulation levels. We first extract visual embedding from lip frames using a pre-trained phone or articulation place recognizer for visual-only EASE (VEASE). Next, we extract audio-visual embedding from noisy speech and lip videos in an information intersection manner, utilizing a complementarity of audio and visual features for multi-modal EASE (MEASE). Experiments on the TCD-TIMIT corpus corrupted by simulated additive noises show that our proposed subword based VEASE approach is more effective than conventional embedding at the word level. Moreover, visual embedding at the articulation place level, leveraging upon a high correlation between place of articulation and lip shapes, shows an even better performance than that at the phone level. Finally the proposed MEASE framework, incorporating both audio and visual embedding, yields significantly better speech quality and intelligibility than those obtained with the best visual-only and audio-only EASE systems.
Singing Voice Synthesis Using Deep Autoregressive Neural Networks for Acoustic Modeling
Jun 21, 2019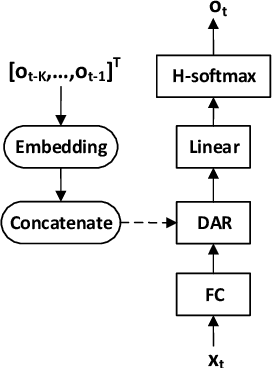
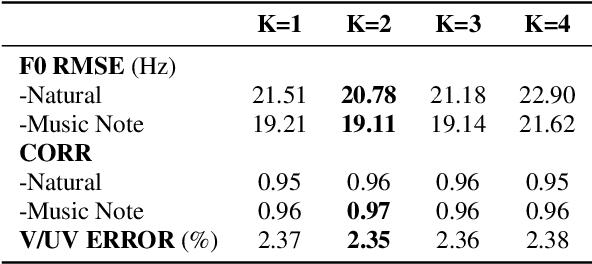
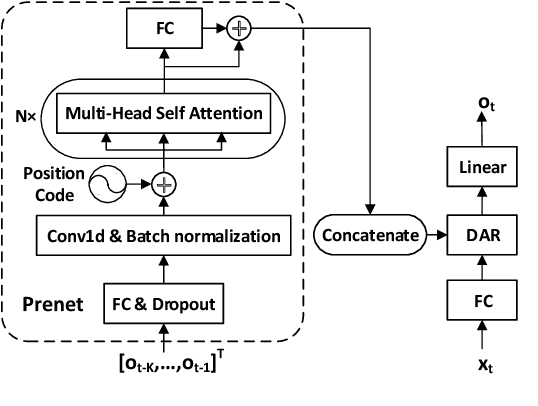
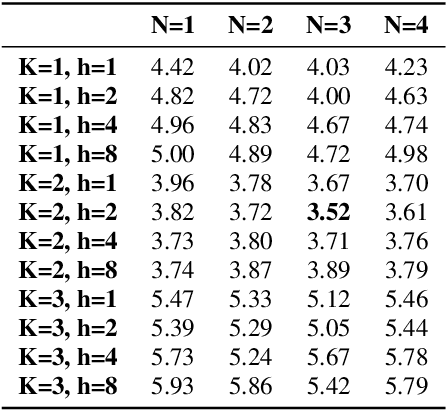
This paper presents a method of using autoregressive neural networks for the acoustic modeling of singing voice synthesis (SVS). Singing voice differs from speech and it contains more local dynamic movements of acoustic features, e.g., vibratos. Therefore, our method adopts deep autoregressive (DAR) models to predict the F0 and spectral features of singing voice in order to better describe the dependencies among the acoustic features of consecutive frames. For F0 modeling, discretized F0 values are used and the influences of the history length in DAR are analyzed by experiments. An F0 post-processing strategy is also designed to alleviate the inconsistency between the predicted F0 contours and the F0 values determined by music notes. Furthermore, we extend the DAR model to deal with continuous spectral features, and a prenet module with self-attention layers is introduced to process historical frames. Experiments on a Chinese singing voice corpus demonstrate that our method using DARs can produce F0 contours with vibratos effectively, and can achieve better objective and subjective performance than the conventional method using recurrent neural networks (RNNs).
Forward Attention in Sequence-to-sequence Acoustic Modelling for Speech Synthesis
Jul 18, 2018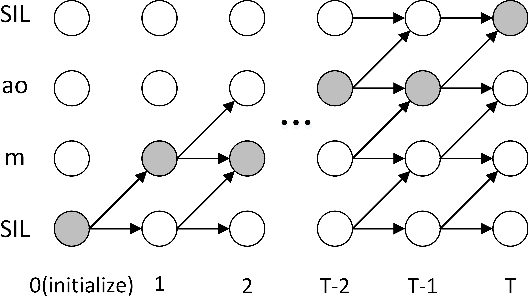
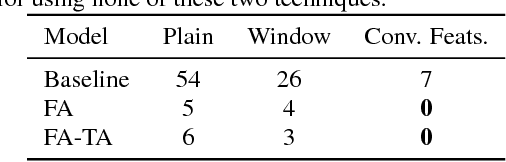
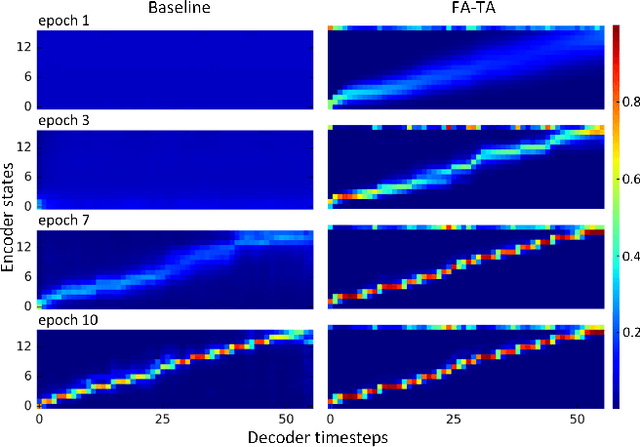

This paper proposes a forward attention method for the sequenceto- sequence acoustic modeling of speech synthesis. This method is motivated by the nature of the monotonic alignment from phone sequences to acoustic sequences. Only the alignment paths that satisfy the monotonic condition are taken into consideration at each decoder timestep. The modified attention probabilities at each timestep are computed recursively using a forward algorithm. A transition agent for forward attention is further proposed, which helps the attention mechanism to make decisions whether to move forward or stay at each decoder timestep. Experimental results show that the proposed forward attention method achieves faster convergence speed and higher stability than the baseline attention method. Besides, the method of forward attention with transition agent can also help improve the naturalness of synthetic speech and control the speed of synthetic speech effectively.
* 5 pages, 3 figures, 2 tables. Published in IEEE International Conference on Acoustics, Speech and Signal Processing 2018 (ICASSP2018)