 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding Generalization via Analytical Learning Theory
Oct 01, 2018
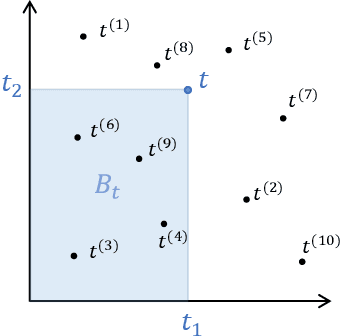

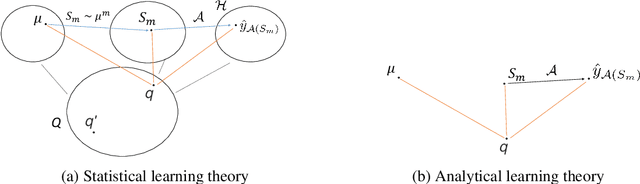
This paper introduces a novel measure-theoretic theory for machine learning that does not require statistical assumptions. Based on this theory, a new regularization method in deep learning is derived and shown to outperform previous methods in CIFAR-10, CIFAR-100, and SVHN. Moreover, the proposed theory provides a theoretical basis for a family of practically successful regularization methods in deep learning. We discuss several consequences of our results on one-shot learning, representation learning, deep learning, and curriculum learning. Unlike statistical learning theory, the proposed learning theory analyzes each problem instance individually via measure theory, rather than a set of problem instances via statistics. As a result, it provides different types of results and insights when compared to statistical learning theory.
Learning What Information to Give in Partially Observed Domains
Sep 27, 2018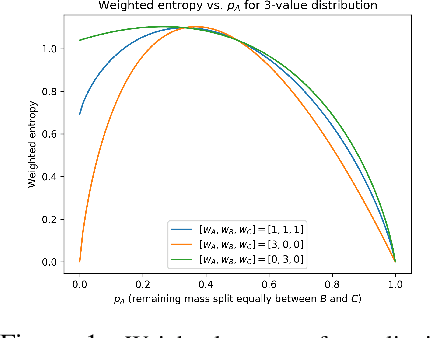
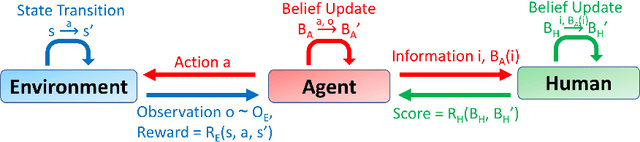
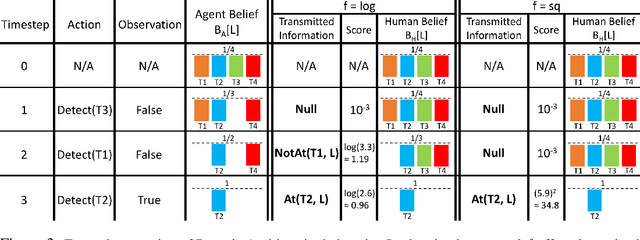
In many robotic applications, an autonomous agent must act within and explore a partially observed environment that is unobserved by its human teammate. We consider such a setting in which the agent can, while acting, transmit declarative information to the human that helps them understand aspects of this unseen environment. In this work, we address the algorithmic question of how the agent should plan out what actions to take and what information to transmit. Naturally, one would expect the human to have preferences, which we model information-theoretically by scoring transmitted information based on the change it induces in weighted entropy of the human's belief state. We formulate this setting as a belief MDP and give a tractable algorithm for solving it approximately. Then, we give an algorithm that allows the agent to learn the human's preferences online, through exploration. We validate our approach experimentally in simulated discrete and continuous partially observed search-and-recover domains. Visit http://tinyurl.com/chitnis-corl-18 for a supplementary video.
Active model learning and diverse action sampling for task and motion planning
Aug 12, 2018
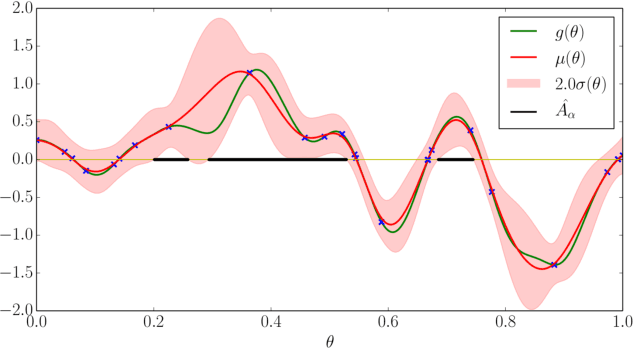
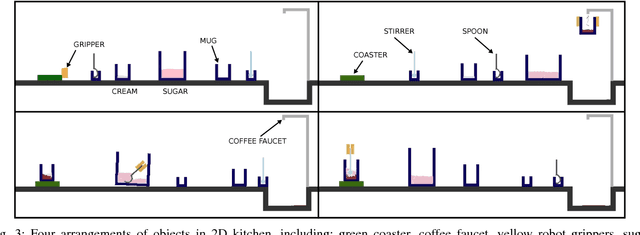
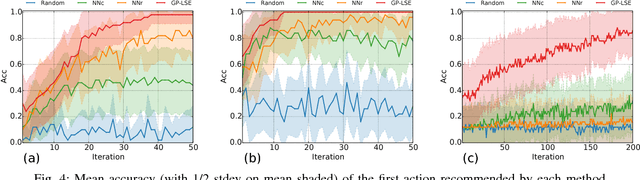
The objective of this work is to augment the basic abilities of a robot by learning to use new sensorimotor primitives to enable the solution of complex long-horizon problems. Solving long-horizon problems in complex domains requires flexible generative planning that can combine primitive abilities in novel combinations to solve problems as they arise in the world. In order to plan to combine primitive actions, we must have models of the preconditions and effects of those actions: under what circumstances will executing this primitive achieve some particular effect in the world? We use, and develop novel improvements on, state-of-the-art methods for active learning and sampling. We use Gaussian process methods for learning the conditions of operator effectiveness from small numbers of expensive training examples collected by experimentation on a robot. We develop adaptive sampling methods for generating diverse elements of continuous sets (such as robot configurations and object poses) during planning for solving a new task, so that planning is as efficient as possible. We demonstrate these methods in an integrated system, combining newly learned models with an efficient continuous-space robot task and motion planner to learn to solve long horizon problems more efficiently than was previously possible.
Integrating Human-Provided Information Into Belief State Representation Using Dynamic Factorization
Jul 30, 2018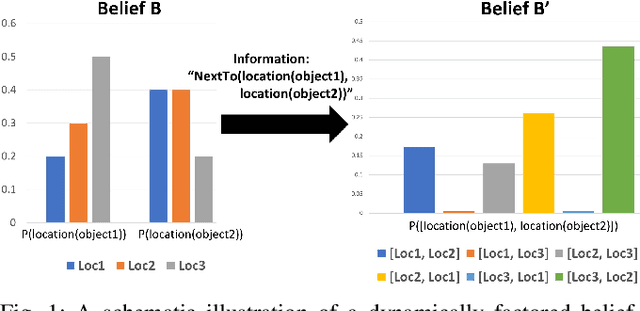
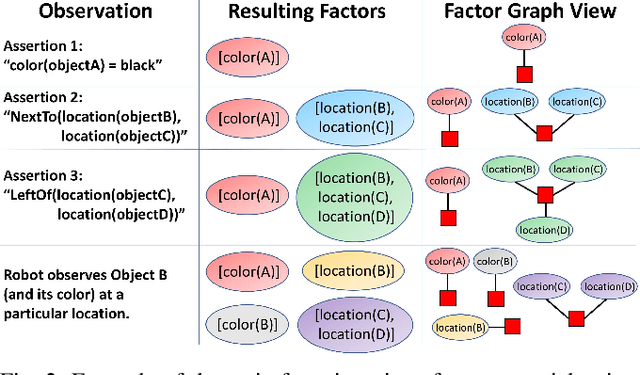
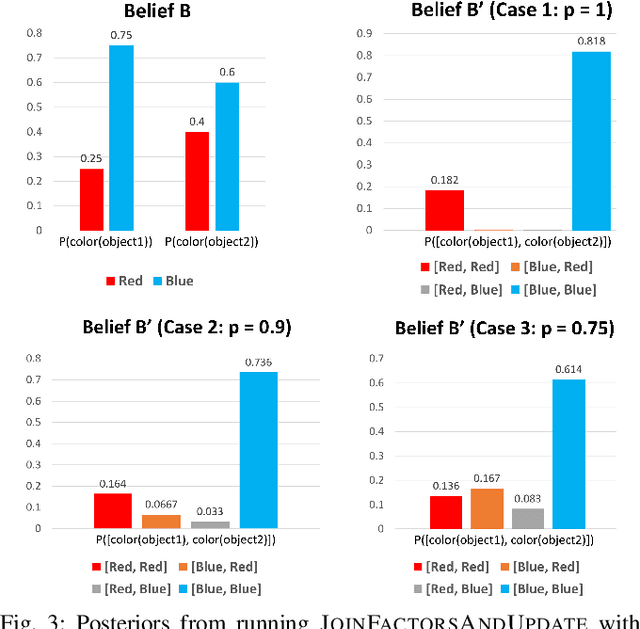
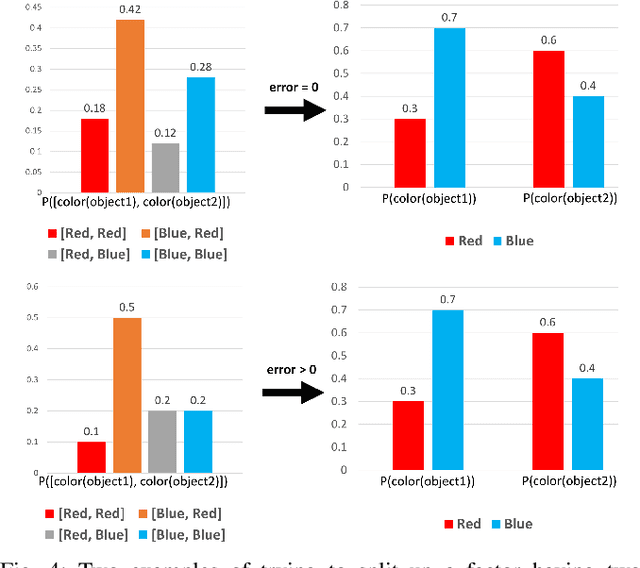
In partially observed environments, it can be useful for a human to provide the robot with declarative information that represents probabilistic relational constraints on properties of objects in the world, augmenting the robot's sensory observations. For instance, a robot tasked with a search-and-rescue mission may be informed by the human that two victims are probably in the same room. An important question arises: how should we represent the robot's internal knowledge so that this information is correctly processed and combined with raw sensory information? In this paper, we provide an efficient belief state representation that dynamically selects an appropriate factoring, combining aspects of the belief when they are correlated through information and separating them when they are not. This strategy works in open domains, in which the set of possible objects is not known in advance, and provides significant improvements in inference time over a static factoring, leading to more efficient planning for complex partially observed tasks. We validate our approach experimentally in two open-domain planning problems: a 2D discrete gridworld task and a 3D continuous cooking task. A supplementary video can be found at http://tinyurl.com/chitnis-iros-18.
Learning to guide task and motion planning using score-space representation
Jul 26, 2018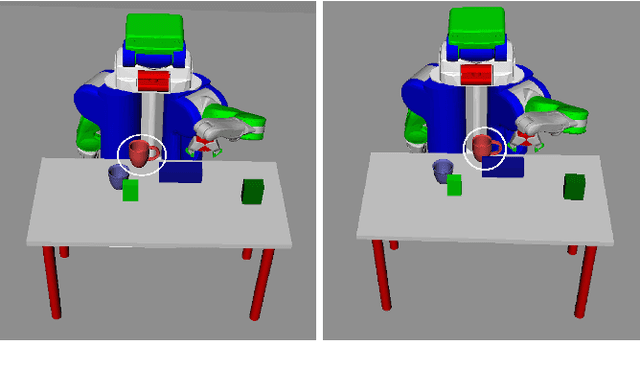
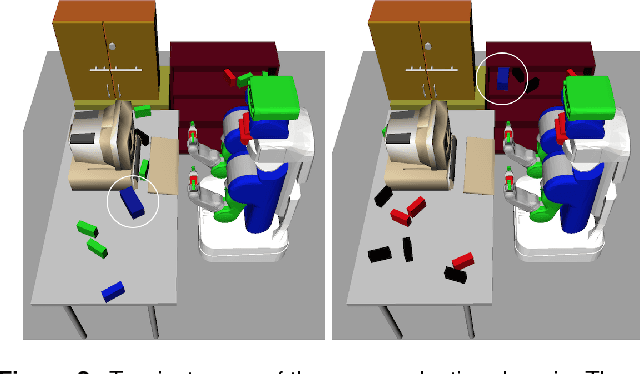
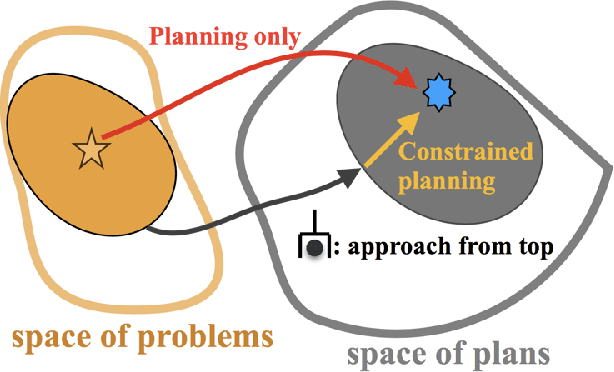
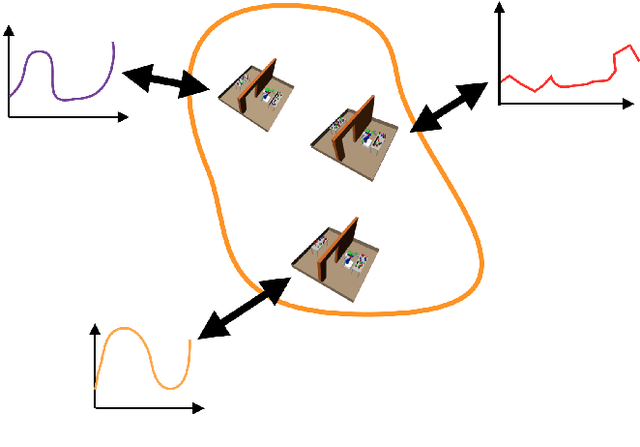
In this paper, we propose a learning algorithm that speeds up the search in task and motion planning problems. Our algorithm proposes solutions to three different challenges that arise in learning to improve planning efficiency: what to predict, how to represent a planning problem instance, and how to transfer knowledge from one problem instance to another. We propose a method that predicts constraints on the search space based on a generic representation of a planning problem instance, called score-space, where we represent a problem instance in terms of the performance of a set of solutions attempted so far. Using this representation, we transfer knowledge, in the form of constraints, from previous problems based on the similarity in score space. We design a sequential algorithm that efficiently predicts these constraints, and evaluate it in three different challenging task and motion planning problems. Results indicate that our approach performs orders of magnitudes faster than an unguided planner
Selecting Representative Examples for Program Synthesis
Jun 07, 2018

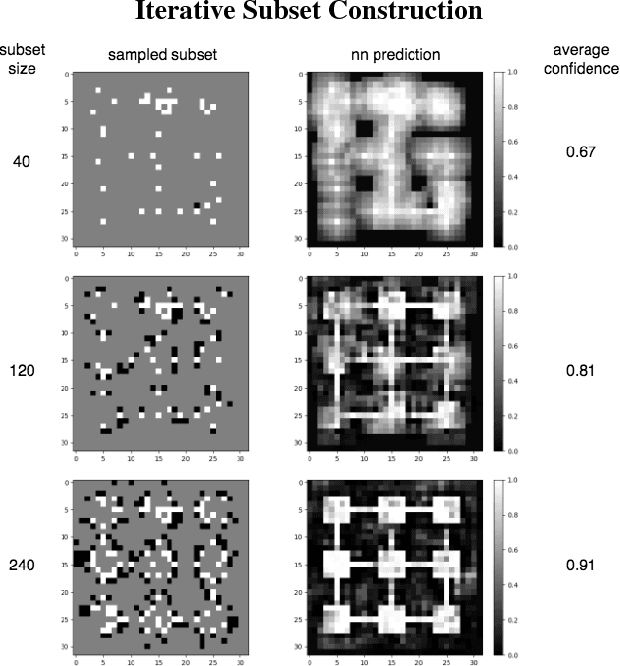
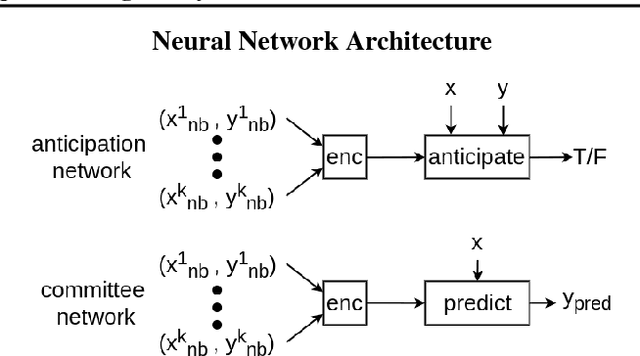
Program synthesis is a class of regression problems where one seeks a solution, in the form of a source-code program, mapping the inputs to their corresponding outputs exactly. Due to its precise and combinatorial nature, program synthesis is commonly formulated as a constraint satisfaction problem, where input-output examples are encoded as constraints and solved with a constraint solver. A key challenge of this formulation is scalability: while constraint solvers work well with a few well-chosen examples, a large set of examples can incur significant overhead in both time and memory. We describe a method to discover a subset of examples that is both small and representative: the subset is constructed iteratively, using a neural network to predict the probability of unchosen examples conditioned on the chosen examples in the subset, and greedily adding the least probable example. We empirically evaluate the representativeness of the subsets constructed by our method, and demonstrate such subsets can significantly improve synthesis time and stability.
Generalization in Deep Learning
Feb 22, 2018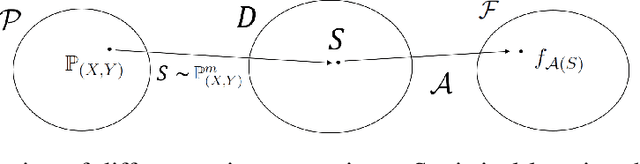
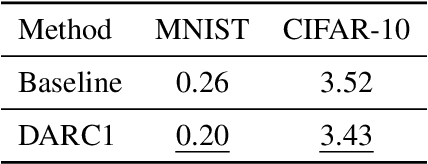
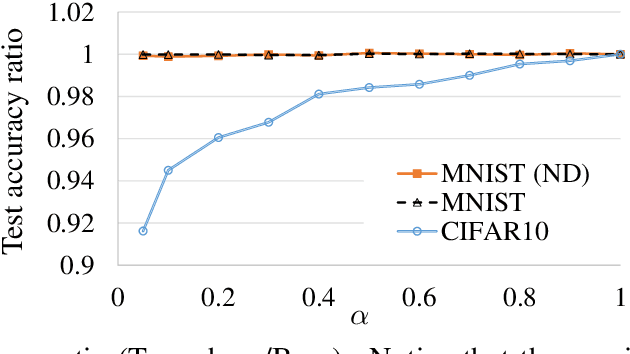

With a direct analysis of neural networks, this paper presents a mathematically tight generalization theory to partially address an open problem regarding the generalization of deep learning. Unlike previous bound-based theory, our main theory is quantitatively as tight as possible for every dataset individually, while producing qualitative insights competitively. Our results give insight into why and how deep learning can generalize well, despite its large capacity, complexity, possible algorithmic instability, nonrobustness, and sharp minima, answering to an open question in the literature. We also discuss limitations of our results and propose additional open problems.
FFRob: Leveraging Symbolic Planning for Efficient Task and Motion Planning
Dec 01, 2017
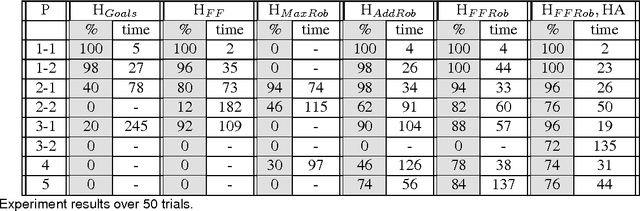
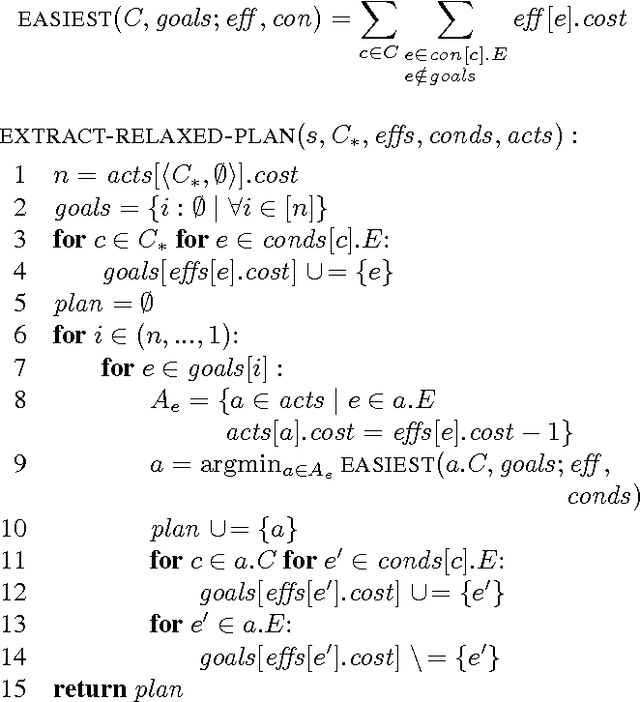
Mobile manipulation problems involving many objects are challenging to solve due to the high dimensionality and multi-modality of their hybrid configuration spaces. Planners that perform a purely geometric search are prohibitively slow for solving these problems because they are unable to factor the configuration space. Symbolic task planners can efficiently construct plans involving many variables but cannot represent the geometric and kinematic constraints required in manipulation. We present the FFRob algorithm for solving task and motion planning problems. First, we introduce Extended Action Specification (EAS) as a general purpose planning representation that supports arbitrary predicates as conditions. We adapt existing heuristic search ideas for solving \proc{strips} planning problems, particularly delete-relaxations, to solve EAS problem instances. We then apply the EAS representation and planners to manipulation problems resulting in FFRob. FFRob iteratively discretizes task and motion planning problems using batch sampling of manipulation primitives and a multi-query roadmap structure that can be conditionalized to evaluate reachability under different placements of movable objects. This structure enables the EAS planner to efficiently compute heuristics that incorporate geometric and kinematic planning constraints to give a tight estimate of the distance to the goal. Additionally, we show FFRob is probabilistically complete and has finite expected runtime. Finally, we empirically demonstrate FFRob's effectiveness on complex and diverse task and motion planning tasks including rearrangement planning and navigation among movable objects.
Guiding the search in continuous state-action spaces by learning an action sampling distribution from off-target samples
Nov 04, 2017
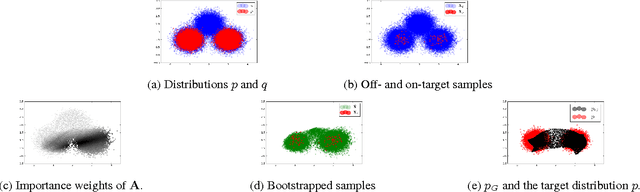

In robotics, it is essential to be able to plan efficiently in high-dimensional continuous state-action spaces for long horizons. For such complex planning problems, unguided uniform sampling of actions until a path to a goal is found is hopelessly inefficient, and gradient-based approaches often fall short when the optimization manifold of a given problem is not smooth. In this paper we present an approach that guides the search of a state-space planner, such as A*, by learning an action-sampling distribution that can generalize across different instances of a planning problem. The motivation is that, unlike typical learning approaches for planning for continuous action space that estimate a policy, an estimated action sampler is more robust to error since it has a planner to fall back on. We use a Generative Adversarial Network (GAN), and address an important issue: search experience consists of a relatively large number of actions that are not on a solution path and a relatively small number of actions that actually are on a solution path. We introduce a new technique, based on an importance-ratio estimation method, for using samples from a non-target distribution to make GAN learning more data-efficient. We provide theoretical guarantees and empirical evaluation in three challenging continuous robot planning problems to illustrate the effectiveness of our algorithm.
Provably Safe Robot Navigation with Obstacle Uncertainty
May 31, 2017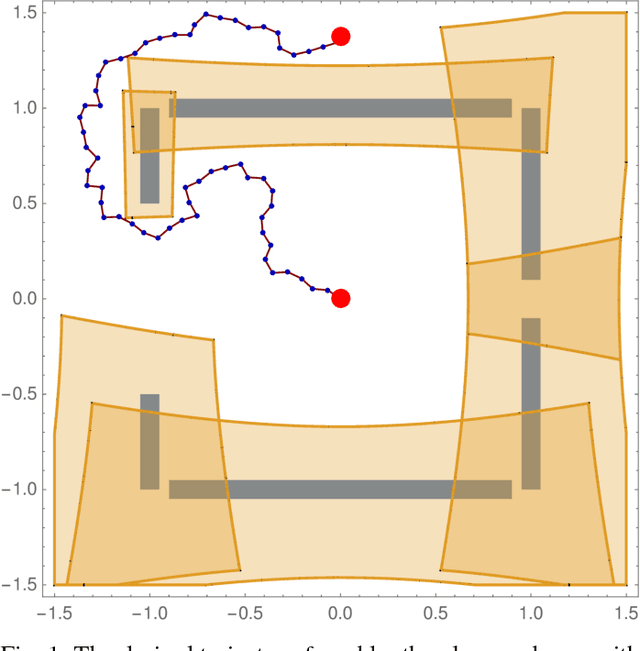

As drones and autonomous cars become more widespread it is becoming increasingly important that robots can operate safely under realistic conditions. The noisy information fed into real systems means that robots must use estimates of the environment to plan navigation. Efficiently guaranteeing that the resulting motion plans are safe under these circumstances has proved difficult. We examine how to guarantee that a trajectory or policy is safe with only imperfect observations of the environment. We examine the implications of various mathematical formalisms of safety and arrive at a mathematical notion of safety of a long-term execution, even when conditioned on observational information. We present efficient algorithms that can prove that trajectories or policies are safe with much tighter bounds than in previous work. Notably, the complexity of the environment does not affect our methods ability to evaluate if a trajectory or policy is safe. We then use these safety checking methods to design a safe variant of the RRT planning algorithm.