 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDatasheet for the Pile
Jan 13, 2022This datasheet describes the Pile, a 825 GiB dataset of human-authored text compiled by EleutherAI for use in large-scale language modeling. The Pile is comprised of 22 different text sources, ranging from original scrapes done for this project, to text data made available by the data owners, to third-party scrapes available online.
Multitask Prompted Training Enables Zero-Shot Task Generalization
Oct 15, 2021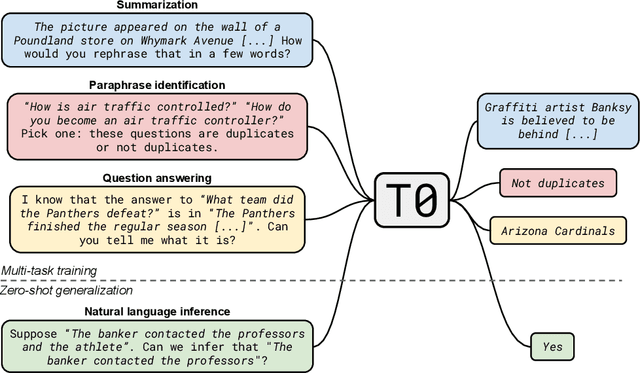

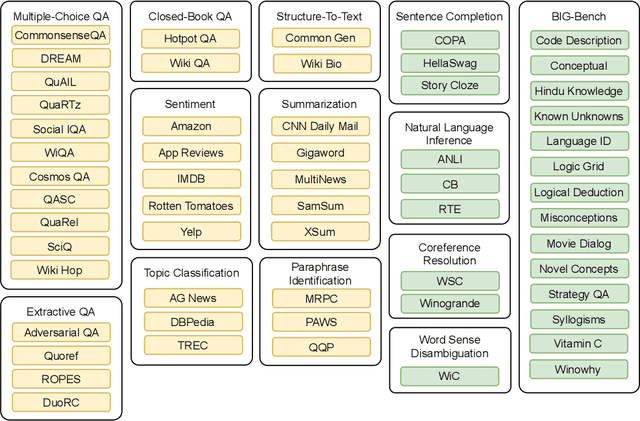

Large language models have recently been shown to attain reasonable zero-shot generalization on a diverse set of tasks. It has been hypothesized that this is a consequence of implicit multitask learning in language model training. Can zero-shot generalization instead be directly induced by explicit multitask learning? To test this question at scale, we develop a system for easily mapping general natural language tasks into a human-readable prompted form. We convert a large set of supervised datasets, each with multiple prompts using varying natural language. These prompted datasets allow for benchmarking the ability of a model to perform completely unseen tasks specified in natural language. We fine-tune a pretrained encoder-decoder model on this multitask mixture covering a wide variety of tasks. The model attains strong zero-shot performance on several standard datasets, often outperforming models 16x its size. Further, our approach attains strong performance on a subset of tasks from the BIG-Bench benchmark, outperforming models 6x its size. All prompts and trained models are available at github.com/bigscience-workshop/promptsource/.
Cut the CARP: Fishing for zero-shot story evaluation
Oct 08, 2021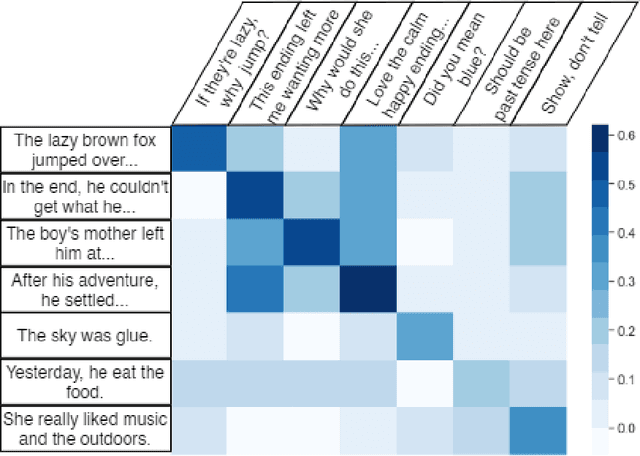

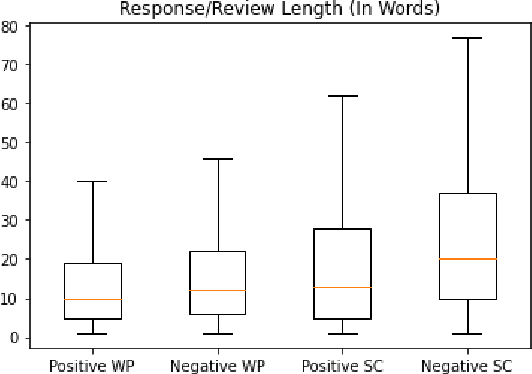

Recent advances in large-scale language models (Raffel et al., 2019; Brown et al., 2020) have brought significant qualitative and quantitative improvements in machine-driven text generation. Despite this, generation and evaluation of machine-generated narrative text remains a challenging problem. Objective evaluation of computationally-generated stories may be prohibitively expensive, require meticulously annotated datasets, or may not adequately measure the logical coherence of a generated story's narratological structure. Informed by recent advances in contrastive learning (Radford et al., 2021), we present Contrastive Authoring and Reviewing Pairing (CARP): a scalable, efficient method for performing qualitatively superior, zero-shot evaluation of stories. We show a strong correlation between human evaluation of stories and those of CARP. Model outputs more significantly correlate with corresponding human input than those language-model based methods which utilize finetuning or prompt engineering approaches. We also present and analyze the Story-Critique Dataset, a new corpora composed of 1.3 million aligned story-critique pairs derived from over 80,000 stories. We expect this corpus to be of interest to NLP researchers.
An Empirical Exploration in Quality Filtering of Text Data
Sep 02, 2021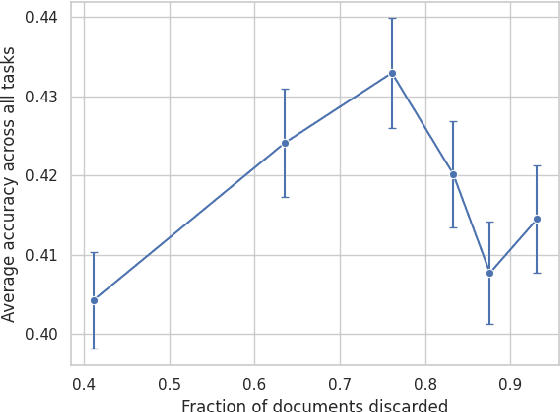
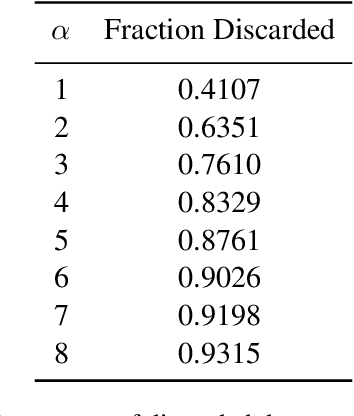
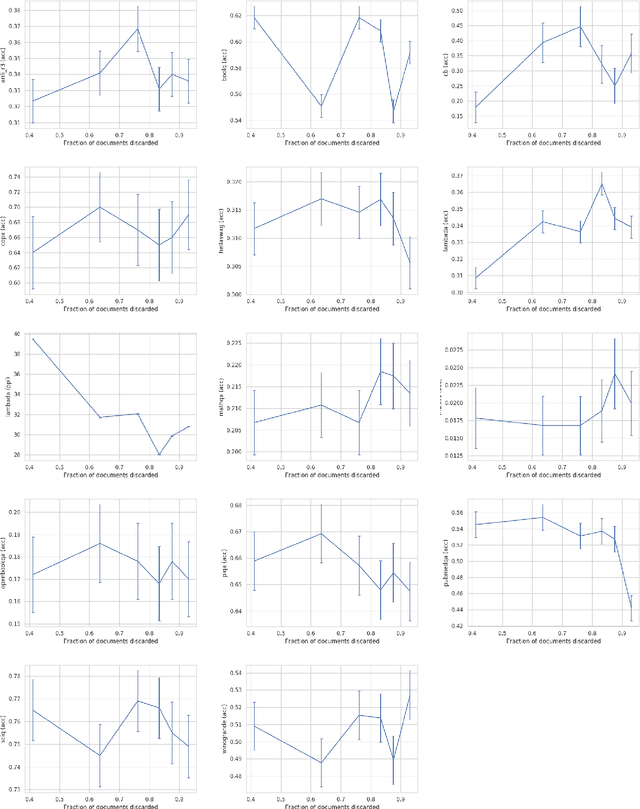
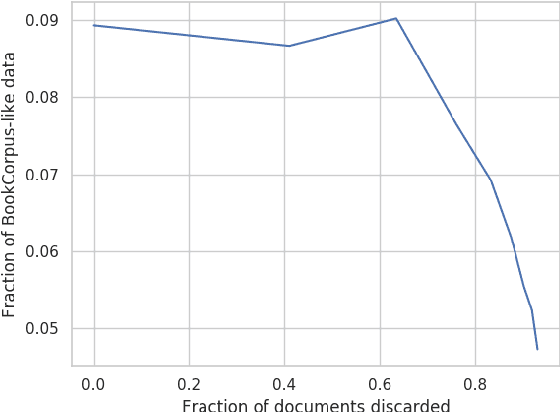
While conventional wisdom suggests that more aggressively filtering data from low-quality sources like Common Crawl always monotonically improves the quality of training data, we find that aggressive filtering can in fact lead to a decrease in model quality on a wide array of downstream tasks for a GPT-like language model. We speculate that this is because optimizing sufficiently strongly for a proxy metric harms performance on the true objective, suggesting a need for more robust filtering objectives when attempting to filter more aggressively. We hope this work leads to detailed analysis of the effects of dataset filtering design choices on downstream model performance in future work.
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Dec 31, 2020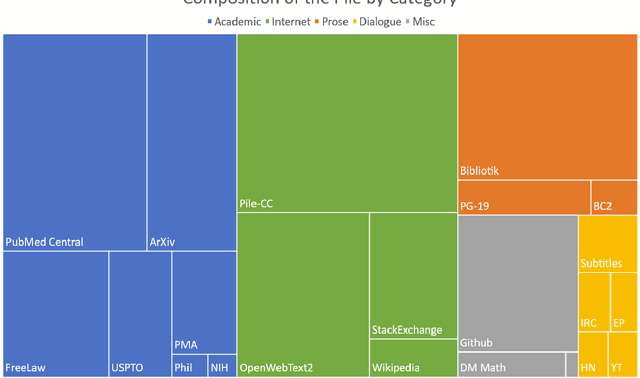
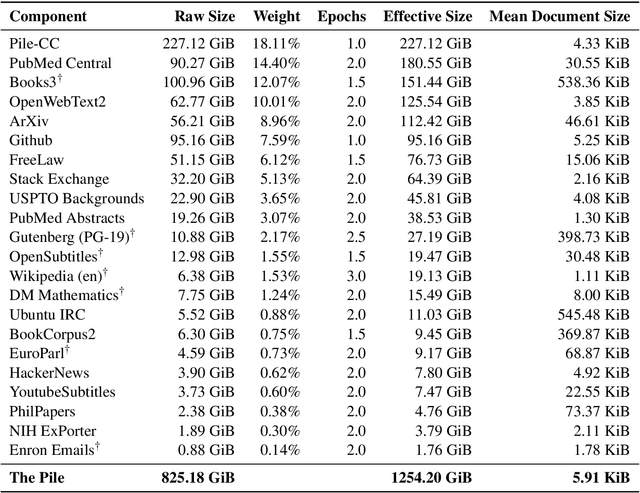
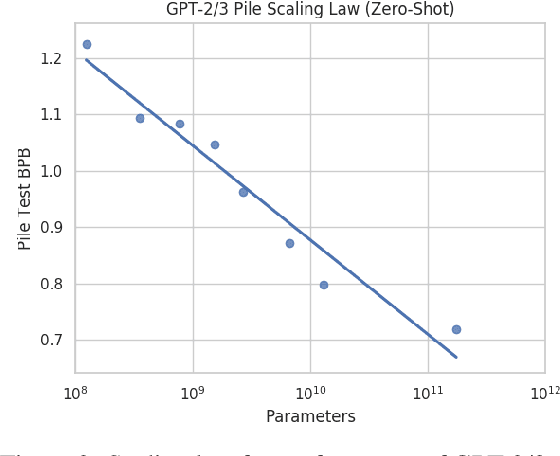
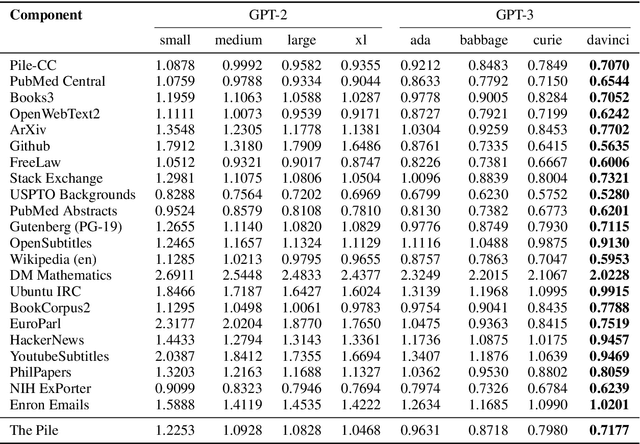
Recent work has demonstrated that increased training dataset diversity improves general cross-domain knowledge and downstream generalization capability for large-scale language models. With this in mind, we present \textit{the Pile}: an 825 GiB English text corpus targeted at training large-scale language models. The Pile is constructed from 22 diverse high-quality subsets -- both existing and newly constructed -- many of which derive from academic or professional sources. Our evaluation of the untuned performance of GPT-2 and GPT-3 on the Pile shows that these models struggle on many of its components, such as academic writing. Conversely, models trained on the Pile improve significantly over both Raw CC and CC-100 on all components of the Pile, while improving performance on downstream evaluations. Through an in-depth exploratory analysis, we document potentially concerning aspects of the data for prospective users. We make publicly available the code used in its construction.
Collaborative Storytelling with Large-scale Neural Language Models
Nov 20, 2020
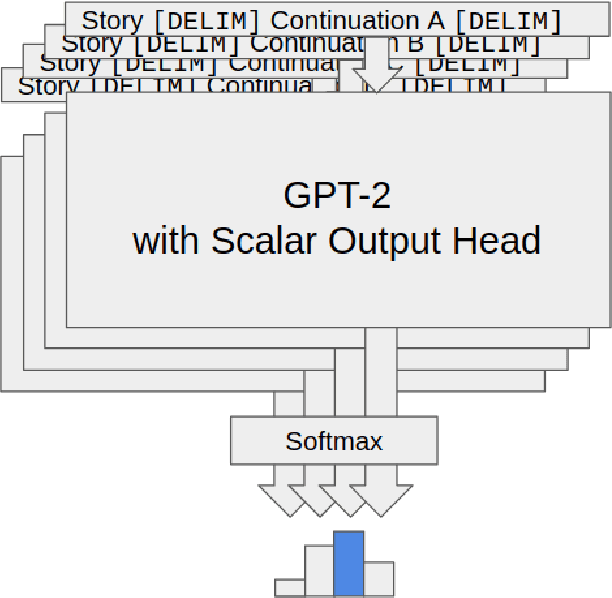
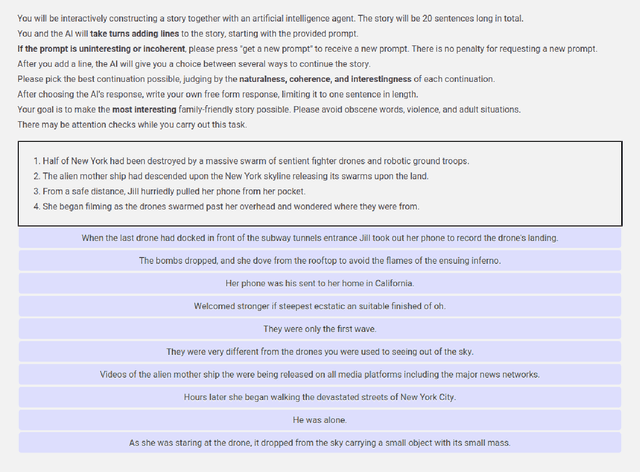
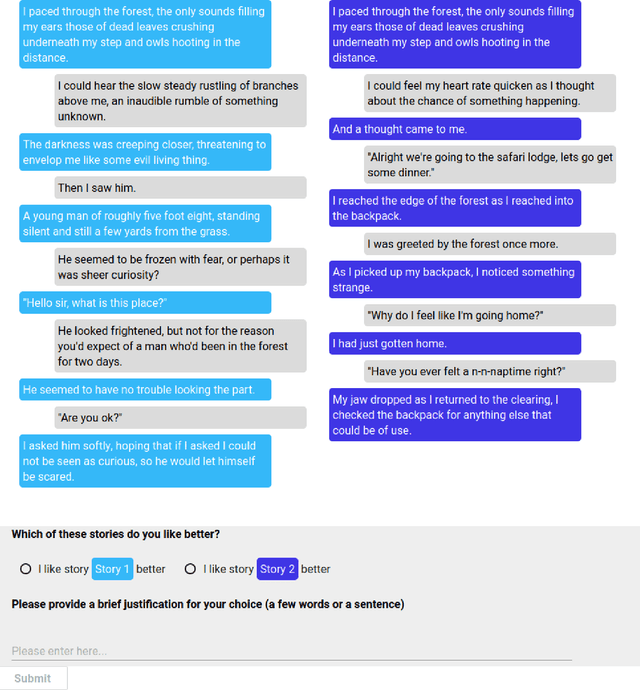
Storytelling plays a central role in human socializing and entertainment. However, much of the research on automatic storytelling generation assumes that stories will be generated by an agent without any human interaction. In this paper, we introduce the task of collaborative storytelling, where an artificial intelligence agent and a person collaborate to create a unique story by taking turns adding to it. We present a collaborative storytelling system which works with a human storyteller to create a story by generating new utterances based on the story so far. We constructed the storytelling system by tuning a publicly-available large scale language model on a dataset of writing prompts and their accompanying fictional works. We identify generating sufficiently human-like utterances to be an important technical issue and propose a sample-and-rank approach to improve utterance quality. Quantitative evaluation shows that our approach outperforms a baseline, and we present qualitative evaluation of our system's capabilities.