 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Potential Observation Missingness in Inverse Reinforcement Learning
May 12, 2026Inverse reinforcement learning (IRL), which infers reward functions from demonstrations, is a valuable tool for modeling and understanding decision-making behavior. Many variants of IRL have been developed to capture complexities of human decision-making, such as subjective beliefs, imperfect planning, and dynamic goals. However, an often-overlooked issue in real-world behavioral datasets is that the recorded data may be missing observations that were available to the original decision-maker. In use-inspired settings such as healthcare, this can make expert actions appear suboptimal, even when they were near-optimal given the information available at the time. As a result, the rewards learned by standard IRL may be misleading. In this paper, we identify the minimal perturbations to the recorded observations needed for the expert's actions to appear optimal. We develop a practical algorithm for this problem and demonstrate its utility for quantifying the possible extent of missing observations in behavioral datasets through extensive experiments on synthetic navigation tasks, a cancer treatment simulator, and ICU treatment data.
A Benchmark for Multi-Party Negotiation Games from Real Negotiation Data
Mar 14, 2026Many real-world multi-party negotiations unfold as sequences of binding, action-level commitments rather than a single final outcome. We introduce a benchmark for this under-studied regime featuring a configurable game generator that sweeps key structural properties such as incentive alignment, goal complexity, and payoff distribution. To evaluate decision-making, we test three value-function approximations - myopic reward, an optimistic upper bound, and a pessimistic lower bound - that act as biased lenses on deal evaluation. Through exact evaluation on small games and comparative evaluation on large, document-grounded instances derived from the Harvard Negotiation Challenge, we map the strategic regimes where each approximation succeeds or fails. We observe that different game structures demand different valuation strategies, motivating agents that learn robust state values and plan effectively over long horizons under binding commitments and terminal only rewards.
Inverse Transition Learning: Learning Dynamics from Demonstrations
Nov 07, 2024



We consider the problem of estimating the transition dynamics $T^*$ from near-optimal expert trajectories in the context of offline model-based reinforcement learning. We develop a novel constraint-based method, Inverse Transition Learning, that treats the limited coverage of the expert trajectories as a \emph{feature}: we use the fact that the expert is near-optimal to inform our estimate of $T^*$. We integrate our constraints into a Bayesian approach. Across both synthetic environments and real healthcare scenarios like Intensive Care Unit (ICU) patient management in hypotension, we demonstrate not only significant improvements in decision-making, but that our posterior can inform when transfer will be successful.
Pruning the Path to Optimal Care: Identifying Systematically Suboptimal Medical Decision-Making with Inverse Reinforcement Learning
Nov 07, 2024In aims to uncover insights into medical decision-making embedded within observational data from clinical settings, we present a novel application of Inverse Reinforcement Learning (IRL) that identifies suboptimal clinician actions based on the actions of their peers. This approach centers two stages of IRL with an intermediate step to prune trajectories displaying behavior that deviates significantly from the consensus. This enables us to effectively identify clinical priorities and values from ICU data containing both optimal and suboptimal clinician decisions. We observe that the benefits of removing suboptimal actions vary by disease and differentially impact certain demographic groups.
Decision-Point Guided Safe Policy Improvement
Oct 12, 2024



Within batch reinforcement learning, safe policy improvement (SPI) seeks to ensure that the learnt policy performs at least as well as the behavior policy that generated the dataset. The core challenge in SPI is seeking improvements while balancing risk when many state-action pairs may be infrequently visited. In this work, we introduce Decision Points RL (DPRL), an algorithm that restricts the set of state-action pairs (or regions for continuous states) considered for improvement. DPRL ensures high-confidence improvement in densely visited states (i.e. decision points) while still utilizing data from sparsely visited states. By appropriately limiting where and how we may deviate from the behavior policy, we achieve tighter bounds than prior work; specifically, our data-dependent bounds do not scale with the size of the state and action spaces. In addition to the analysis, we demonstrate that DPRL is both safe and performant on synthetic and real datasets.
Bayesian Inverse Transition Learning for Offline Settings
Aug 09, 2023

Offline Reinforcement learning is commonly used for sequential decision-making in domains such as healthcare and education, where the rewards are known and the transition dynamics $T$ must be estimated on the basis of batch data. A key challenge for all tasks is how to learn a reliable estimate of the transition dynamics $T$ that produce near-optimal policies that are safe enough so that they never take actions that are far away from the best action with respect to their value functions and informative enough so that they communicate the uncertainties they have. Using data from an expert, we propose a new constraint-based approach that captures our desiderata for reliably learning a posterior distribution of the transition dynamics $T$ that is free from gradients. Our results demonstrate that by using our constraints, we learn a high-performing policy, while considerably reducing the policy's variance over different datasets. We also explain how combining uncertainty estimation with these constraints can help us infer a partial ranking of actions that produce higher returns, and helps us infer safer and more informative policies for planning.
Risk averse non-stationary multi-armed bandits
Sep 28, 2021
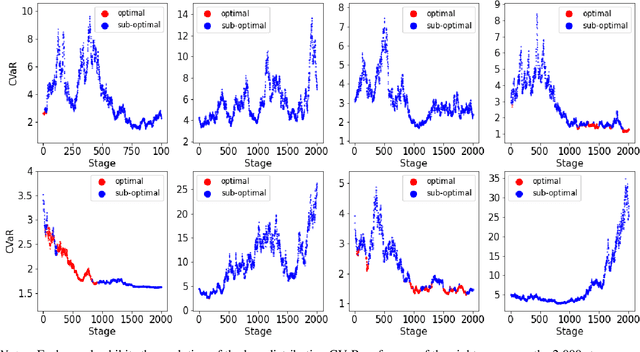
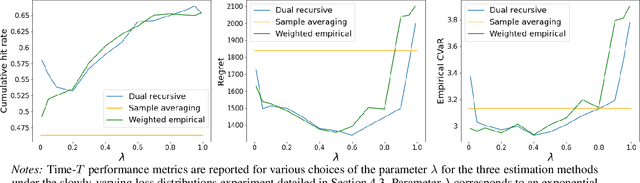
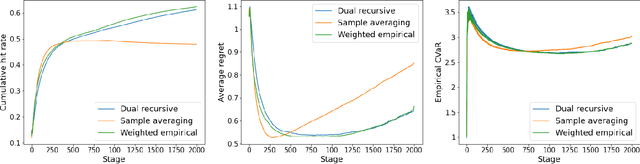
This paper tackles the risk averse multi-armed bandits problem when incurred losses are non-stationary. The conditional value-at-risk (CVaR) is used as the objective function. Two estimation methods are proposed for this objective function in the presence of non-stationary losses, one relying on a weighted empirical distribution of losses and another on the dual representation of the CVaR. Such estimates can then be embedded into classic arm selection methods such as epsilon-greedy policies. Simulation experiments assess the performance of the arm selection algorithms based on the two novel estimation approaches, and such policies are shown to outperform naive benchmarks not taking non-stationarity into account.