 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIDE: Every Layer Knows the Token Beneath the Context
May 07, 2026We revisit a universally accepted but under-examined design choice in every modern LLM: a token index is looked up once at the input embedding layer and then permanently discarded. This single-injection assumption induces two structural failures: (i) the Rare Token Problem, where a Zipf-type distribution of vocabulary causes rare-token embeddings are chronically under-trained due to receiving a fraction of the cumulative gradient signal compared to common tokens; and (ii) the Contextual Collapse Problem, where limited parameters models map distributionally similar tokens to indistinguishable hidden states. As an attempt to address both, we propose TIDE, which augments the standard transformer with EmbeddingMemory: an ensemble of K independent MemoryBlocks that map token indices to context-free semantic vectors, computed once and injected into every layer through a depth-conditioned softmax router with a learnable null bank. We theoretically and empirically establish the benefits of TIDE in addressing the issues associated with single-token identity injection as well as improve performance across multiple language modeling and downstream tasks.
MemoryLLM: Plug-n-Play Interpretable Feed-Forward Memory for Transformers
Jan 30, 2026Understanding how transformer components operate in LLMs is important, as it is at the core of recent technological advances in artificial intelligence. In this work, we revisit the challenges associated with interpretability of feed-forward modules (FFNs) and propose MemoryLLM, which aims to decouple FFNs from self-attention and enables us to study the decoupled FFNs as context-free token-wise neural retrieval memory. In detail, we investigate how input tokens access memory locations within FFN parameters and the importance of FFN memory across different downstream tasks. MemoryLLM achieves context-free FFNs by training them in isolation from self-attention directly using the token embeddings. This approach allows FFNs to be pre-computed as token-wise lookups (ToLs), enabling on-demand transfer between VRAM and storage, additionally enhancing inference efficiency. We also introduce Flex-MemoryLLM, positioning it between a conventional transformer design and MemoryLLM. This architecture bridges the performance gap caused by training FFNs with context-free token-wise embeddings.
Ensemble Methods for Convex Regression with Applications to Geometric Programming Based Circuit Design
Jun 18, 2012


Convex regression is a promising area for bridging statistical estimation and deterministic convex optimization. New piecewise linear convex regression methods are fast and scalable, but can have instability when used to approximate constraints or objective functions for optimization. Ensemble methods, like bagging, smearing and random partitioning, can alleviate this problem and maintain the theoretical properties of the underlying estimator. We empirically examine the performance of ensemble methods for prediction and optimization, and then apply them to device modeling and constraint approximation for geometric programming based circuit design.
Beta-Negative Binomial Process and Poisson Factor Analysis
Feb 04, 2012

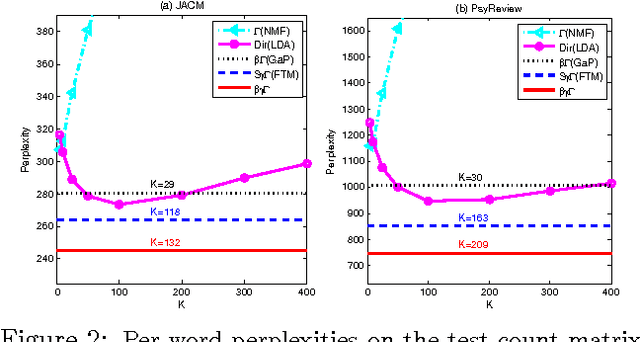

A beta-negative binomial (BNB) process is proposed, leading to a beta-gamma-Poisson process, which may be viewed as a "multi-scoop" generalization of the beta-Bernoulli process. The BNB process is augmented into a beta-gamma-gamma-Poisson hierarchical structure, and applied as a nonparametric Bayesian prior for an infinite Poisson factor analysis model. A finite approximation for the beta process Levy random measure is constructed for convenient implementation. Efficient MCMC computations are performed with data augmentation and marginalization techniques. Encouraging results are shown on document count matrix factorization.