 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Incremental Hashing
Jun 09, 2016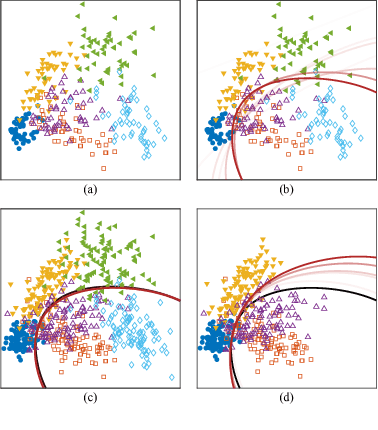
We propose an incremental strategy for learning hash functions with kernels for large-scale image search. Our method is based on a two-stage classification framework that treats binary codes as intermediate variables between the feature space and the semantic space. In the first stage of classification, binary codes are considered as class labels by a set of binary SVMs; each corresponds to one bit. In the second stage, binary codes become the input space of a multi-class SVM. Hash functions are learned by an efficient algorithm where the NP-hard problem of finding optimal binary codes is solved via cyclic coordinate descent and SVMs are trained in a parallelized incremental manner. For modifications like adding images from a previously unseen class, we describe an incremental procedure for effective and efficient updates to the previous hash functions. Experiments on three large-scale image datasets demonstrate the effectiveness of the proposed hashing method, Supervised Incremental Hashing (SIH), over the state-of-the-art supervised hashing methods.
Mining Discriminative Triplets of Patches for Fine-Grained Classification
May 04, 2016
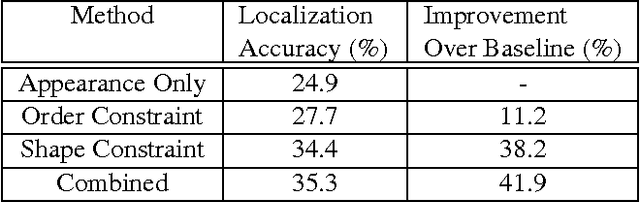
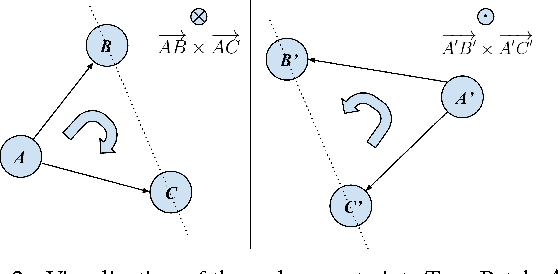
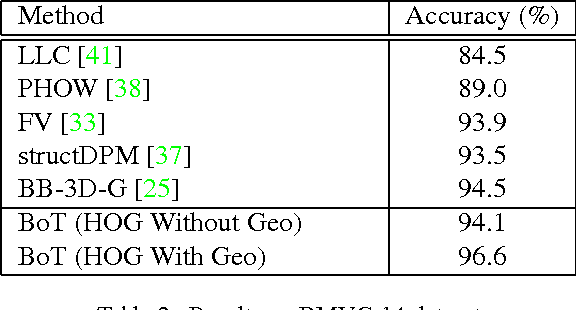
Fine-grained classification involves distinguishing between similar sub-categories based on subtle differences in highly localized regions; therefore, accurate localization of discriminative regions remains a major challenge. We describe a patch-based framework to address this problem. We introduce triplets of patches with geometric constraints to improve the accuracy of patch localization, and automatically mine discriminative geometrically-constrained triplets for classification. The resulting approach only requires object bounding boxes. Its effectiveness is demonstrated using four publicly available fine-grained datasets, on which it outperforms or achieves comparable performance to the state-of-the-art in classification.
G-CNN: an Iterative Grid Based Object Detector
Apr 25, 2016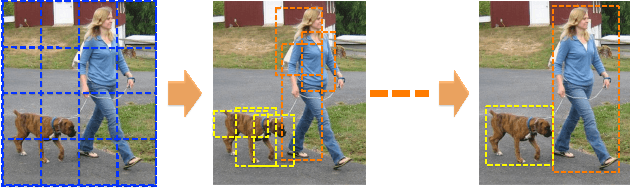

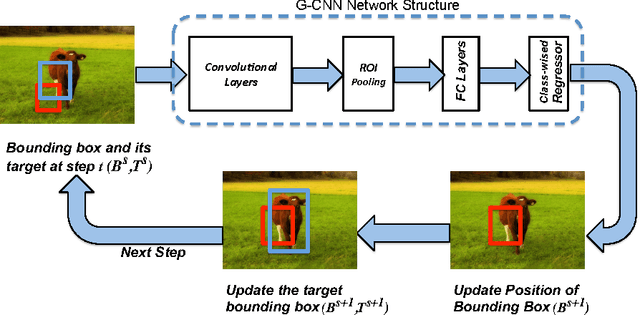

We introduce G-CNN, an object detection technique based on CNNs which works without proposal algorithms. G-CNN starts with a multi-scale grid of fixed bounding boxes. We train a regressor to move and scale elements of the grid towards objects iteratively. G-CNN models the problem of object detection as finding a path from a fixed grid to boxes tightly surrounding the objects. G-CNN with around 180 boxes in a multi-scale grid performs comparably to Fast R-CNN which uses around 2K bounding boxes generated with a proposal technique. This strategy makes detection faster by removing the object proposal stage as well as reducing the number of boxes to be processed.
Scalable Gaussian Processes for Supervised Hashing
Apr 25, 2016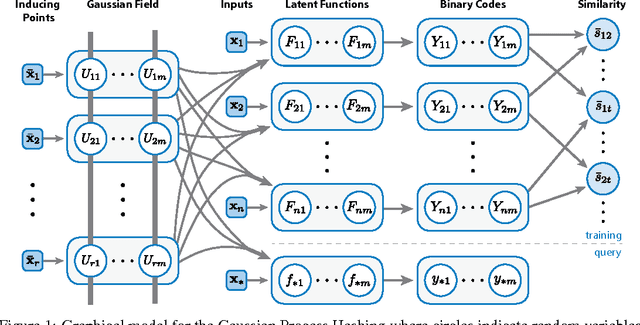
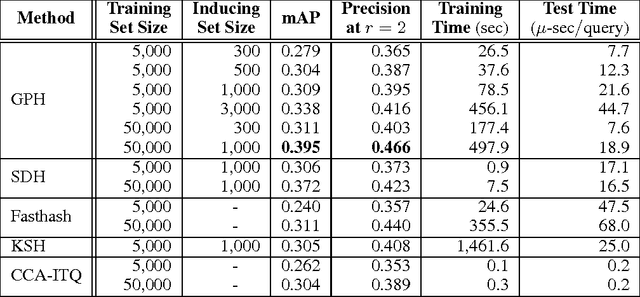
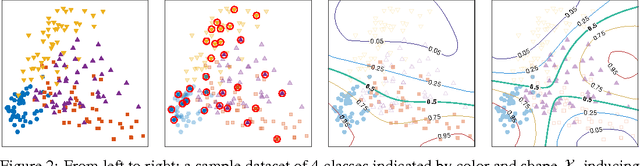
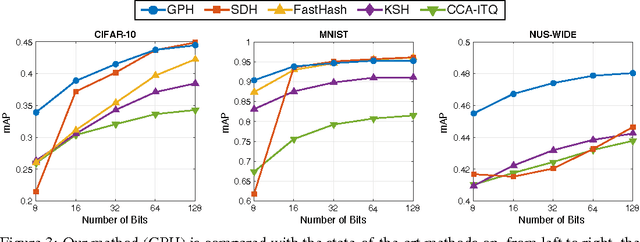
We propose a flexible procedure for large-scale image search by hash functions with kernels. Our method treats binary codes and pairwise semantic similarity as latent and observed variables, respectively, in a probabilistic model based on Gaussian processes for binary classification. We present an efficient inference algorithm with the sparse pseudo-input Gaussian process (SPGP) model and parallelization. Experiments on three large-scale image dataset demonstrate the effectiveness of the proposed hashing method, Gaussian Process Hashing (GPH), for short binary codes and the datasets without predefined classes in comparison to the state-of-the-art supervised hashing methods.
Learning Temporal Regularity in Video Sequences
Apr 15, 2016


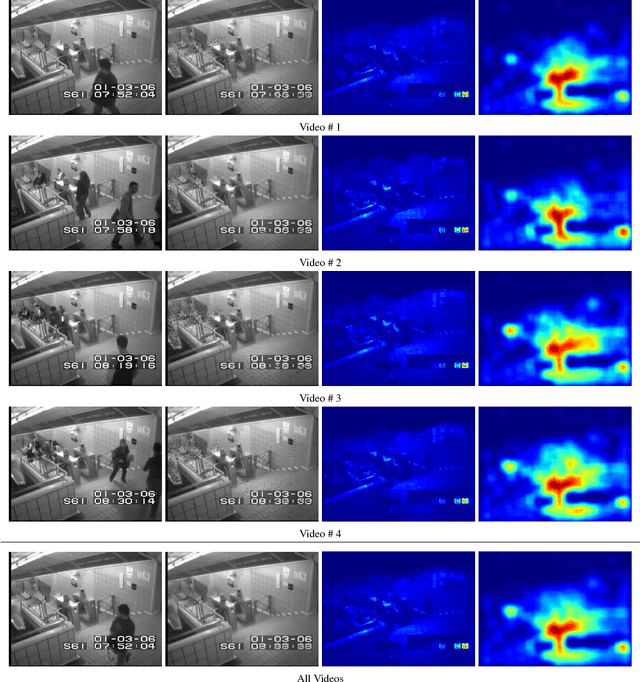
Perceiving meaningful activities in a long video sequence is a challenging problem due to ambiguous definition of 'meaningfulness' as well as clutters in the scene. We approach this problem by learning a generative model for regular motion patterns, termed as regularity, using multiple sources with very limited supervision. Specifically, we propose two methods that are built upon the autoencoders for their ability to work with little to no supervision. We first leverage the conventional handcrafted spatio-temporal local features and learn a fully connected autoencoder on them. Second, we build a fully convolutional feed-forward autoencoder to learn both the local features and the classifiers as an end-to-end learning framework. Our model can capture the regularities from multiple datasets. We evaluate our methods in both qualitative and quantitative ways - showing the learned regularity of videos in various aspects and demonstrating competitive performance on anomaly detection datasets as an application.
Generating Discriminative Object Proposals via Submodular Ranking
Feb 11, 2016
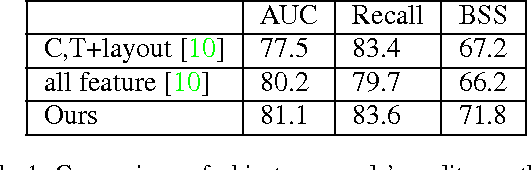
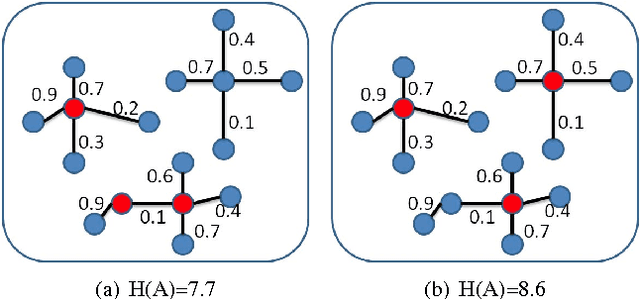
A multi-scale greedy-based object proposal generation approach is presented. Based on the multi-scale nature of objects in images, our approach is built on top of a hierarchical segmentation. We first identify the representative and diverse exemplar clusters within each scale by using a diversity ranking algorithm. Object proposals are obtained by selecting a subset from the multi-scale segment pool via maximizing a submodular objective function, which consists of a weighted coverage term, a single-scale diversity term and a multi-scale reward term. The weighted coverage term forces the selected set of object proposals to be representative and compact; the single-scale diversity term encourages choosing segments from different exemplar clusters so that they will cover as many object patterns as possible; the multi-scale reward term encourages the selected proposals to be discriminative and selected from multiple layers generated by the hierarchical image segmentation. The experimental results on the Berkeley Segmentation Dataset and PASCAL VOC2012 segmentation dataset demonstrate the accuracy and efficiency of our object proposal model. Additionally, we validate our object proposals in simultaneous segmentation and detection and outperform the state-of-art performance.
Parameterizing Region Covariance: An Efficient Way To Apply Sparse Codes On Second Order Statistics
Feb 09, 2016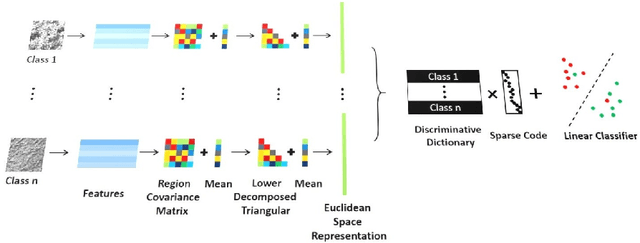
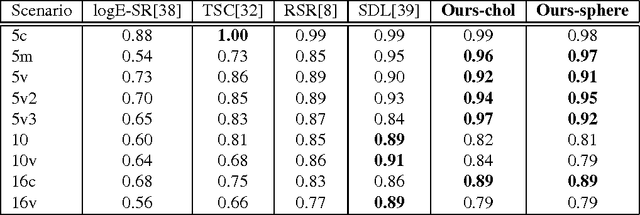

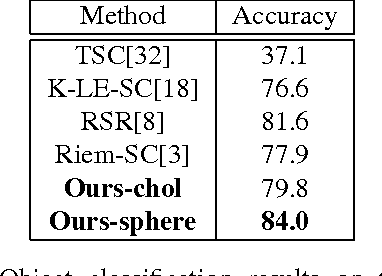
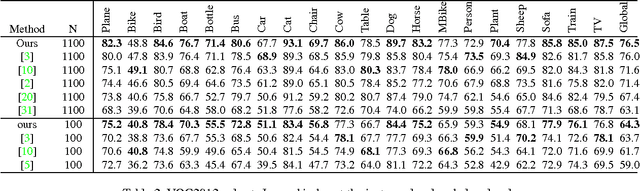
Sparse representations have been successfully applied to signal processing, computer vision and machine learning. Currently there is a trend to learn sparse models directly on structure data, such as region covariance. However, such methods when combined with region covariance often require complex computation. We present an approach to transform a structured sparse model learning problem to a traditional vectorized sparse modeling problem by constructing a Euclidean space representation for region covariance matrices. Our new representation has multiple advantages. Experiments on several vision tasks demonstrate competitive performance with the state-of-the-art methods.
Action Recognition with Image Based CNN Features
Dec 13, 2015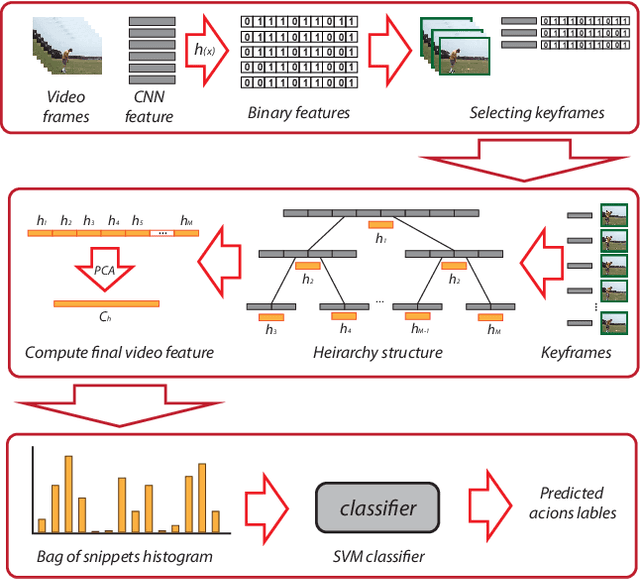
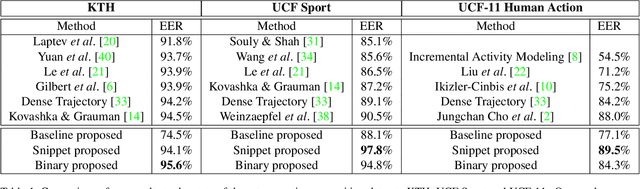
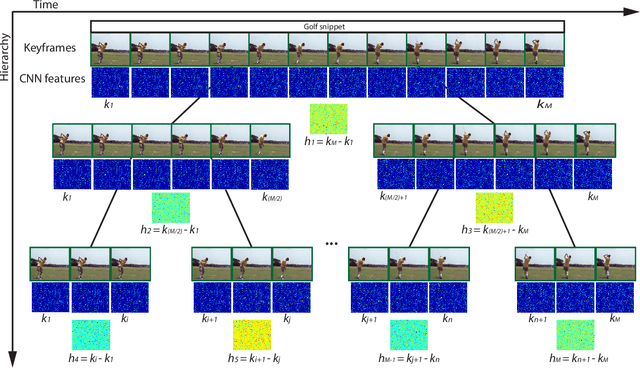
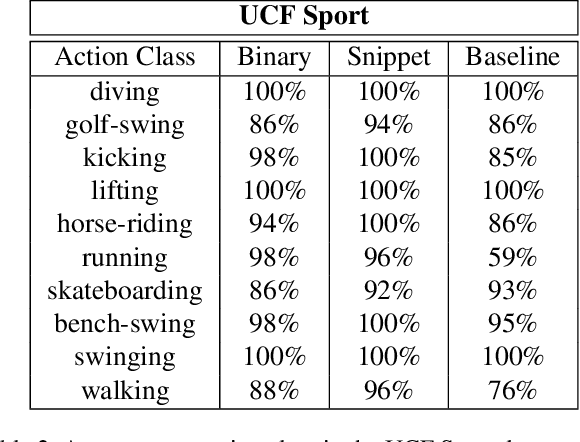
Most of human actions consist of complex temporal compositions of more simple actions. Action recognition tasks usually relies on complex handcrafted structures as features to represent the human action model. Convolutional Neural Nets (CNN) have shown to be a powerful tool that eliminate the need for designing handcrafted features. Usually, the output of the last layer in CNN (a layer before the classification layer -known as fc7) is used as a generic feature for images. In this paper, we show that fc7 features, per se, can not get a good performance for the task of action recognition, when the network is trained only on images. We present a feature structure on top of fc7 features, which can capture the temporal variation in a video. To represent the temporal components, which is needed to capture motion information, we introduced a hierarchical structure. The hierarchical model enables to capture sub-actions from a complex action. At the higher levels of the hierarchy, it represents a coarse capture of action sequence and lower levels represent fine action elements. Furthermore, we introduce a method for extracting key-frames using binary coding of each frame in a video, which helps to improve the performance of our hierarchical model. We experimented our method on several action datasets and show that our method achieves superior results compared to other state-of-the-arts methods.
Searching for Objects using Structure in Indoor Scenes
Nov 24, 2015
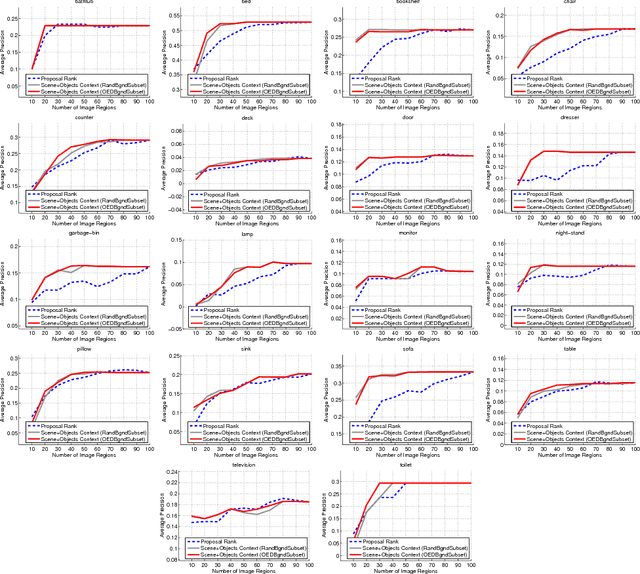
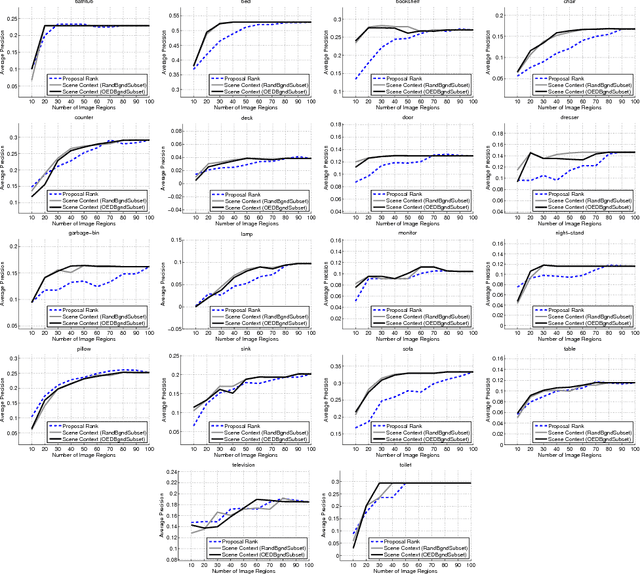

To identify the location of objects of a particular class, a passive computer vision system generally processes all the regions in an image to finally output few regions. However, we can use structure in the scene to search for objects without processing the entire image. We propose a search technique that sequentially processes image regions such that the regions that are more likely to correspond to the query class object are explored earlier. We frame the problem as a Markov decision process and use an imitation learning algorithm to learn a search strategy. Since structure in the scene is essential for search, we work with indoor scene images as they contain both unary scene context information and object-object context in the scene. We perform experiments on the NYU-depth v2 dataset and show that the unary scene context features alone can achieve a significantly high average precision while processing only 20-25\% of the regions for classes like bed and sofa. By considering object-object context along with the scene context features, the performance is further improved for classes like counter, lamp, pillow and sofa.
Selecting Relevant Web Trained Concepts for Automated Event Retrieval
Sep 25, 2015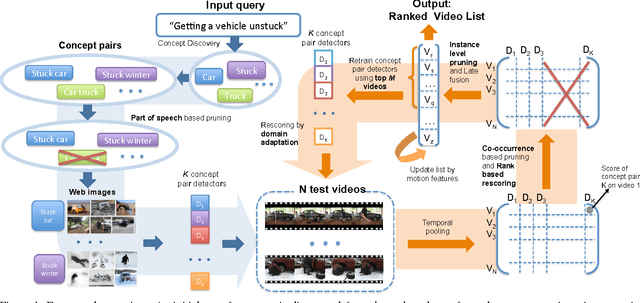
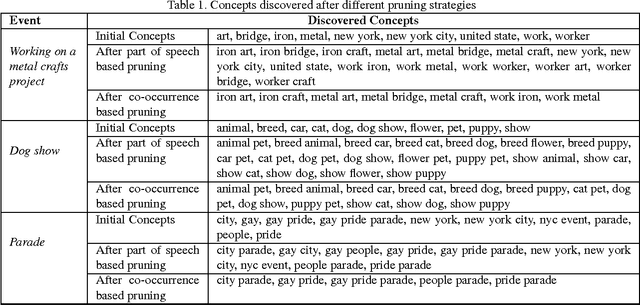


Complex event retrieval is a challenging research problem, especially when no training videos are available. An alternative to collecting training videos is to train a large semantic concept bank a priori. Given a text description of an event, event retrieval is performed by selecting concepts linguistically related to the event description and fusing the concept responses on unseen videos. However, defining an exhaustive concept lexicon and pre-training it requires vast computational resources. Therefore, recent approaches automate concept discovery and training by leveraging large amounts of weakly annotated web data. Compact visually salient concepts are automatically obtained by the use of concept pairs or, more generally, n-grams. However, not all visually salient n-grams are necessarily useful for an event query--some combinations of concepts may be visually compact but irrelevant--and this drastically affects performance. We propose an event retrieval algorithm that constructs pairs of automatically discovered concepts and then prunes those concepts that are unlikely to be helpful for retrieval. Pruning depends both on the query and on the specific video instance being evaluated. Our approach also addresses calibration and domain adaptation issues that arise when applying concept detectors to unseen videos. We demonstrate large improvements over other vision based systems on the TRECVID MED 13 dataset.