 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunity Concealment from Unsupervised Graph Learning-Based Clustering
Feb 12, 2026Graph neural networks (GNNs) are designed to use attributed graphs to learn representations. Such representations are beneficial in the unsupervised learning of clusters and community detection. Nonetheless, such inference may reveal sensitive groups, clustered systems, or collective behaviors, raising concerns regarding group-level privacy. Community attribution in social and critical infrastructure networks, for example, can expose coordinated asset groups, operational hierarchies, and system dependencies that could be used for profiling or intelligence gathering. We study a defensive setting in which a data publisher (defender) seeks to conceal a community of interest while making limited, utility-aware changes in the network. Our analysis indicates that community concealment is strongly influenced by two quantifiable factors: connectivity at the community boundary and feature similarity between the protected community and adjacent communities. Informed by these findings, we present a perturbation strategy that rewires a set of selected edges and modifies node features to reduce the distinctiveness leveraged by GNN message passing. The proposed method outperforms DICE in our experiments on synthetic benchmarks and real network graphs under identical perturbation budgets. Overall, it achieves median relative concealment improvements of approximately 20-45% across the evaluated settings. These findings demonstrate a mitigation strategy against GNN-based community learning and highlight group-level privacy risks intrinsic to graph learning.
Enhancing Patient-Centric Communication: Leveraging LLMs to Simulate Patient Perspectives
Jan 12, 2025



Large Language Models (LLMs) have demonstrated impressive capabilities in role-playing scenarios, particularly in simulating domain-specific experts using tailored prompts. This ability enables LLMs to adopt the persona of individuals with specific backgrounds, offering a cost-effective and efficient alternative to traditional, resource-intensive user studies. By mimicking human behavior, LLMs can anticipate responses based on concrete demographic or professional profiles. In this paper, we evaluate the effectiveness of LLMs in simulating individuals with diverse backgrounds and analyze the consistency of these simulated behaviors compared to real-world outcomes. In particular, we explore the potential of LLMs to interpret and respond to discharge summaries provided to patients leaving the Intensive Care Unit (ICU). We evaluate and compare with human responses the comprehensibility of discharge summaries among individuals with varying educational backgrounds, using this analysis to assess the strengths and limitations of LLM-driven simulations. Notably, when LLMs are primed with educational background information, they deliver accurate and actionable medical guidance 88% of the time. However, when other information is provided, performance significantly drops, falling below random chance levels. This preliminary study shows the potential benefits and pitfalls of automatically generating patient-specific health information from diverse populations. While LLMs show promise in simulating health personas, our results highlight critical gaps that must be addressed before they can be reliably used in clinical settings. Our findings suggest that a straightforward query-response model could outperform a more tailored approach in delivering health information. This is a crucial first step in understanding how LLMs can be optimized for personalized health communication while maintaining accuracy.
MFA is a Waste of Time! Understanding Negative Connotation Towards MFA Applications via User Generated Content
Aug 16, 2019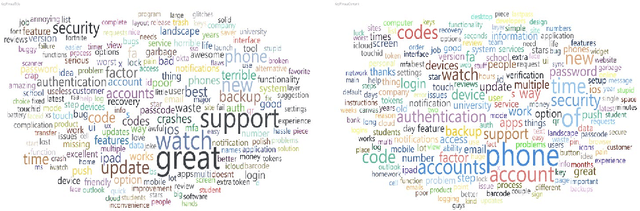
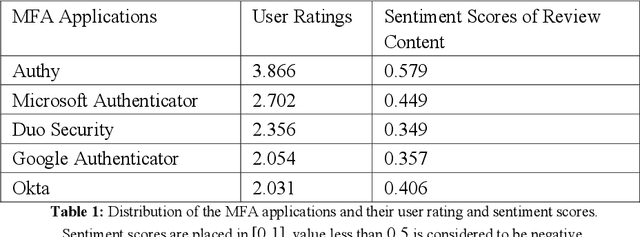
Traditional single-factor authentication possesses several critical security vulnerabilities due to single-point failure feature. Multi-factor authentication (MFA), intends to enhance security by providing additional verification steps. However, in practical deployment, users often experience dissatisfaction while using MFA, which leads to non-adoption. In order to understand the current design and usability issues with MFA, we analyze aggregated user generated comments (N = 12,500) about application-based MFA tools from major distributors, such as, Amazon, Google Play, Apple App Store, and others. While some users acknowledge the security benefits of MFA, majority of them still faced problems with initial configuration, system design understanding, limited device compatibility, and risk trade-offs leading to non-adoption of MFA. Based on these results, we provide actionable recommendations in technological design, initial training, and risk communication to improve the adoption and user experience of MFA.
Using Bursty Announcements for Early Detection of BGP Routing Anomalies
May 14, 2019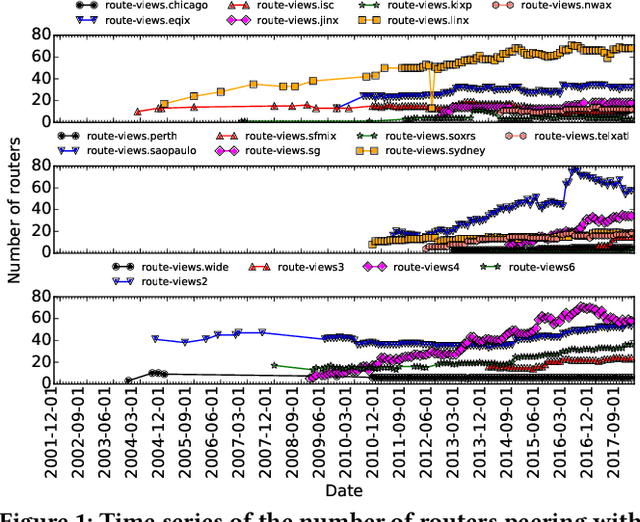
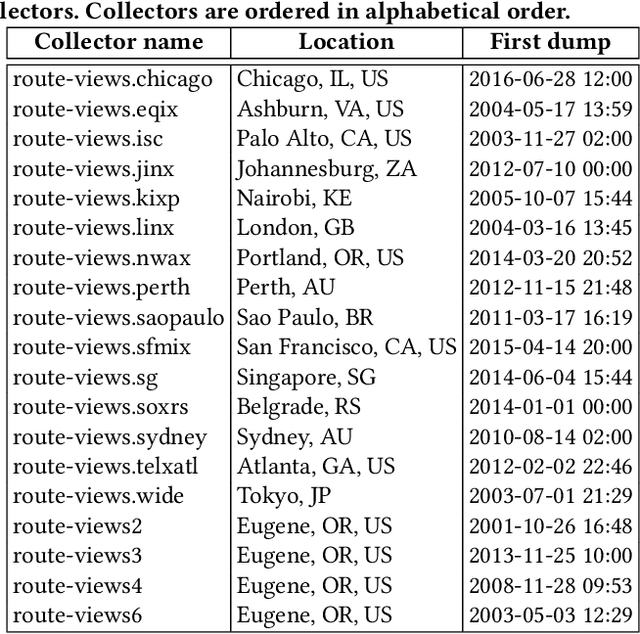
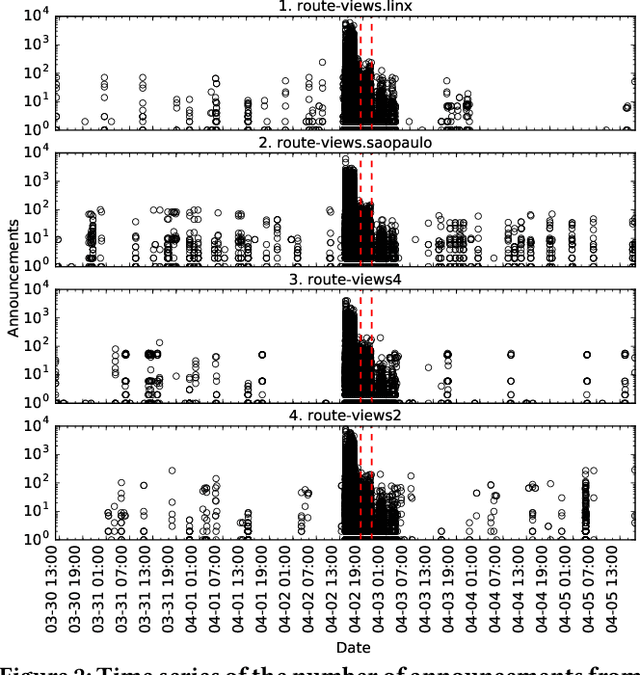
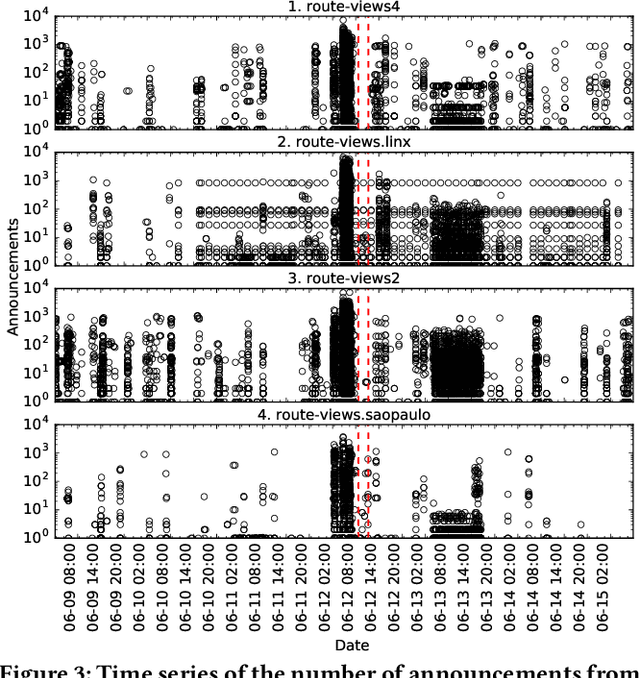
Despite the robust structure of the Internet, it is still susceptible to disruptive routing updates that prevent network traffic from reaching its destination. In this work, we propose a method for early detection of large-scale disruptions based on the analysis of bursty BGP announcements. We hypothesize that the occurrence of large-scale disruptions is preceded by bursty announcements. Our method is grounded in analysis of changes in the inter-arrival times of announcements. BGP announcements that are associated with disruptive updates tend to occur in groups of relatively high frequency, followed by periods of infrequent activity. To test our hypothesis, we quantify the burstiness of inter-arrival times around the date and times of three large-scale incidents: the Indosat hijacking event in April 2014, the Telecom Malaysia leak in June 2015, and the Bharti Airtel Ltd. hijack in November 2015. We show that we can detect these events several hours prior to when they were originally detected. We propose an algorithm that leverages the burstiness of disruptive updates to provide early detection of large-scale malicious incidents using local collector data. We describe limitations, open challenges, and how this method can be used for large-scale routing anomaly detection.