 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuture is not One-dimensional: Graph Modeling based Complex Event Schema Induction for Event Prediction
Apr 15, 2021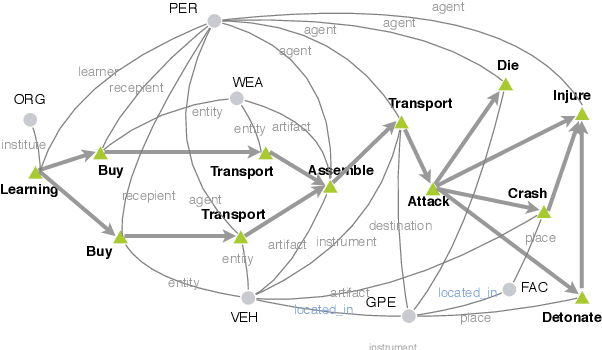
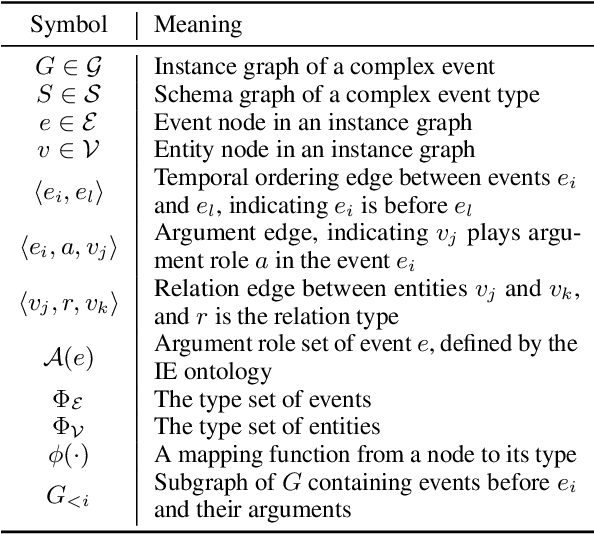
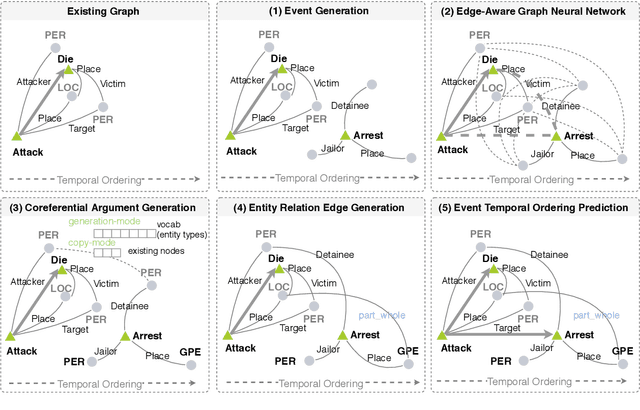
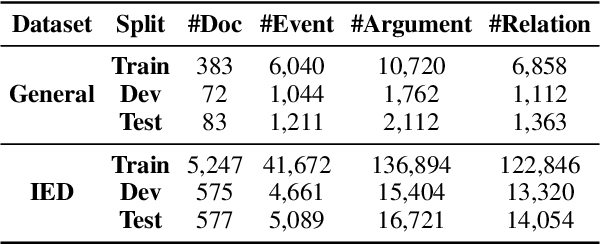
Event schemas encode knowledge of stereotypical structures of events and their connections. As events unfold, schemas are crucial to act as a scaffolding. Previous work on event schema induction either focuses on atomic events or linear temporal event sequences, ignoring the interplay between events via arguments and argument relations. We introduce the concept of Temporal Complex Event Schema: a graph-based schema representation that encompasses events, arguments, temporal connections and argument relations. Additionally, we propose a Temporal Event Graph Model that models the emergence of event instances following the temporal complex event schema. To build and evaluate such schemas, we release a new schema learning corpus containing 6,399 documents accompanied with event graphs, and manually constructed gold schemas. Intrinsic evaluation by schema matching and instance graph perplexity, prove the superior quality of our probabilistic graph schema library compared to linear representations. Extrinsic evaluation on schema-guided event prediction further demonstrates the predictive power of our event graph model, significantly surpassing human schemas and baselines by more than 17.8% on HITS@1.
NaturalProofs: Mathematical Theorem Proving in Natural Language
Mar 24, 2021
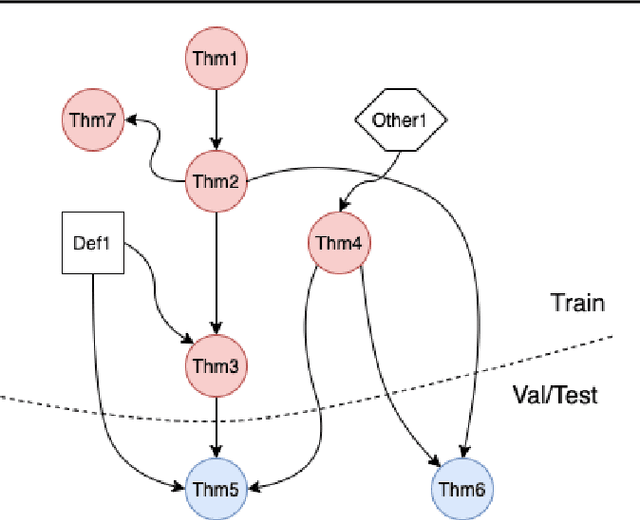
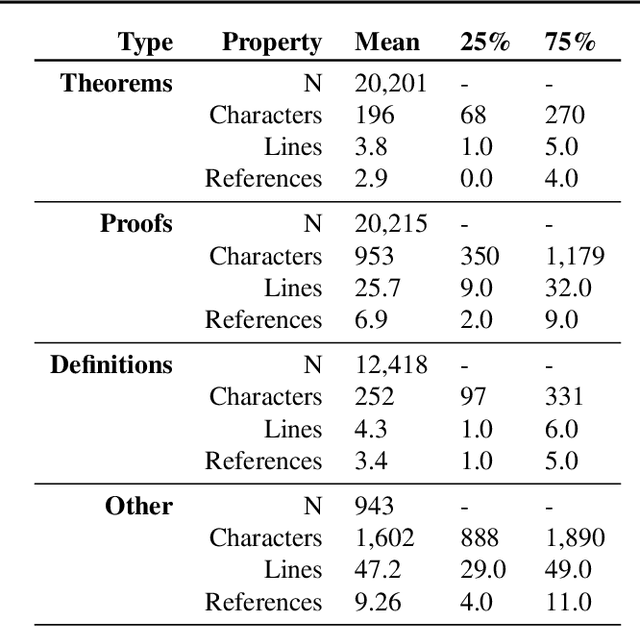
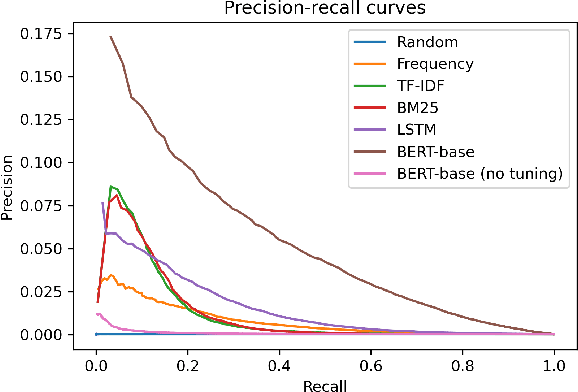
Understanding and creating mathematics using natural mathematical language - the mixture of symbolic and natural language used by humans - is a challenging and important problem for driving progress in machine learning. As a step in this direction, we develop NaturalProofs, a large-scale dataset of mathematical statements and their proofs, written in natural mathematical language. Using NaturalProofs, we propose a mathematical reference retrieval task that tests a system's ability to determine the key results that appear in a proof. Large-scale sequence models excel at this task compared to classical information retrieval techniques, and benefit from language pretraining, yet their performance leaves substantial room for improvement. NaturalProofs opens many possibilities for future research on challenging mathematical tasks.
Rissanen Data Analysis: Examining Dataset Characteristics via Description Length
Mar 05, 2021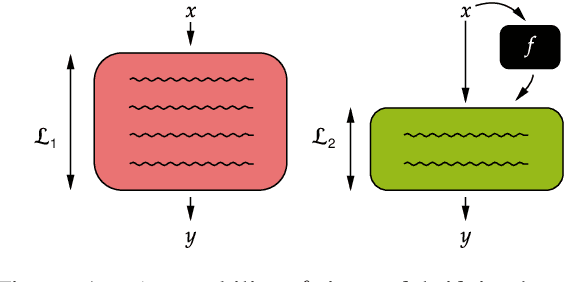

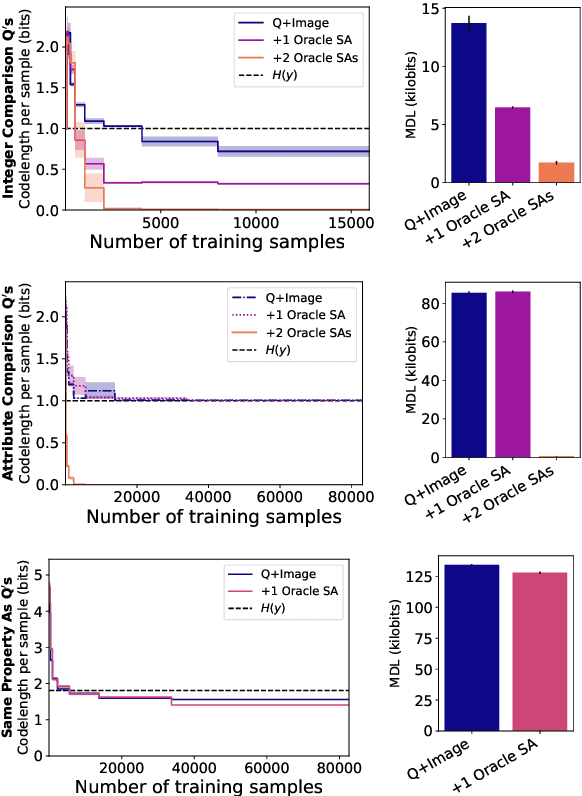
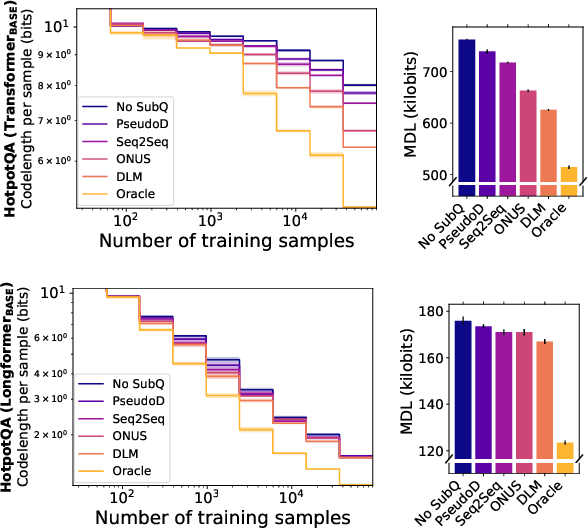
We introduce a method to determine if a certain capability helps to achieve an accurate model of given data. We view labels as being generated from the inputs by a program composed of subroutines with different capabilities, and we posit that a subroutine is useful if and only if the minimal program that invokes it is shorter than the one that does not. Since minimum program length is uncomputable, we instead estimate the labels' minimum description length (MDL) as a proxy, giving us a theoretically-grounded method for analyzing dataset characteristics. We call the method Rissanen Data Analysis (RDA) after the father of MDL, and we showcase its applicability on a wide variety of settings in NLP, ranging from evaluating the utility of generating subquestions before answering a question, to analyzing the value of rationales and explanations, to investigating the importance of different parts of speech, and uncovering dataset gender bias.
Online hyperparameter optimization by real-time recurrent learning
Feb 15, 2021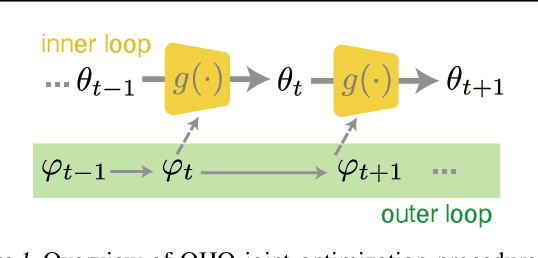
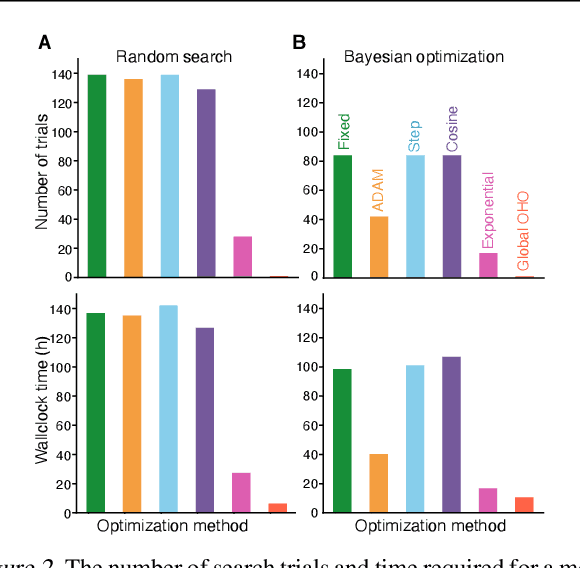
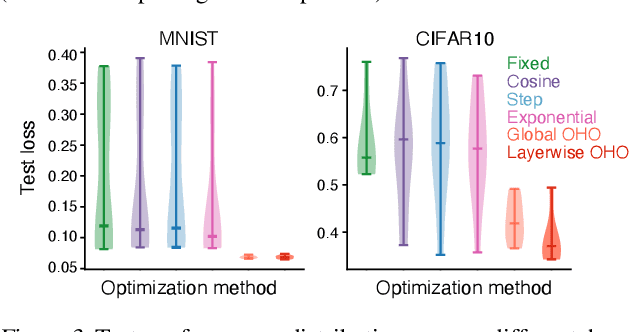
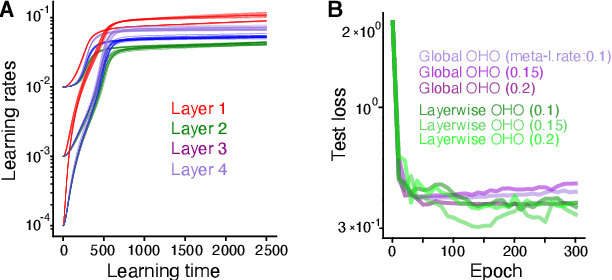
Conventional hyperparameter optimization methods are computationally intensive and hard to generalize to scenarios that require dynamically adapting hyperparameters, such as life-long learning. Here, we propose an online hyperparameter optimization algorithm that is asymptotically exact and computationally tractable, both theoretically and practically. Our framework takes advantage of the analogy between hyperparameter optimization and parameter learning in recurrent neural networks (RNNs). It adapts a well-studied family of online learning algorithms for RNNs to tune hyperparameters and network parameters simultaneously, without repeatedly rolling out iterative optimization. This procedure yields systematically better generalization performance compared to standard methods, at a fraction of wallclock time.
Self-Supervised Equivariant Scene Synthesis from Video
Feb 01, 2021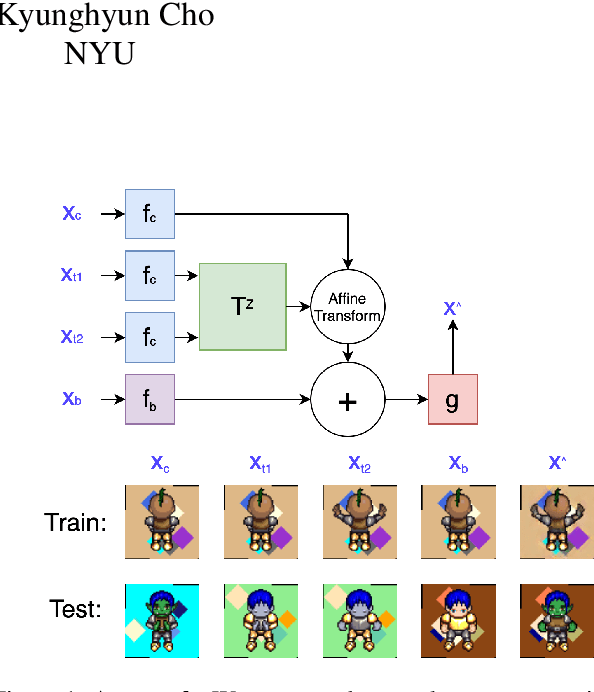
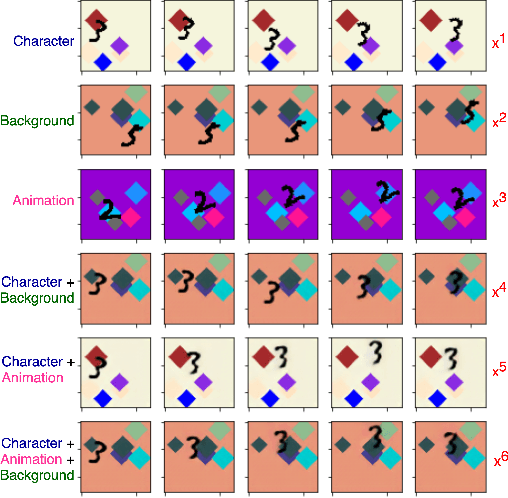
We propose a self-supervised framework to learn scene representations from video that are automatically delineated into background, characters, and their animations. Our method capitalizes on moving characters being equivariant with respect to their transformation across frames and the background being constant with respect to that same transformation. After training, we can manipulate image encodings in real time to create unseen combinations of the delineated components. As far as we know, we are the first method to perform unsupervised extraction and synthesis of interpretable background, character, and animation. We demonstrate results on three datasets: Moving MNIST with backgrounds, 2D video game sprites, and Fashion Modeling.
Catastrophic Fisher Explosion: Early Phase Fisher Matrix Impacts Generalization
Dec 28, 2020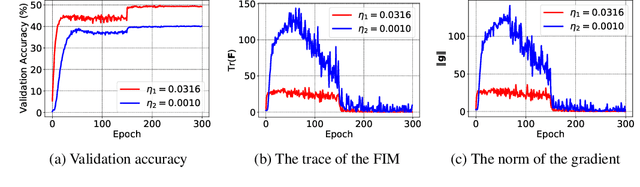
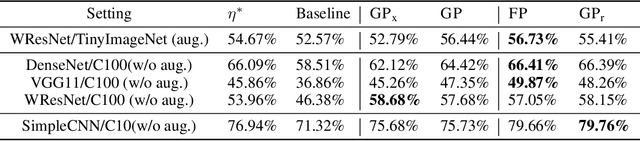
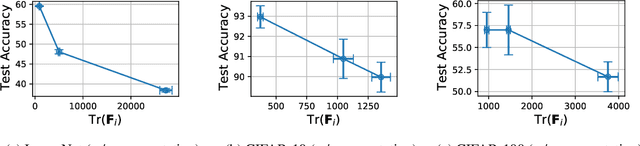
The early phase of training has been shown to be important in two ways for deep neural networks. First, the degree of regularization in this phase significantly impacts the final generalization. Second, it is accompanied by a rapid change in the local loss curvature influenced by regularization choices. Connecting these two findings, we show that stochastic gradient descent (SGD) implicitly penalizes the trace of the Fisher Information Matrix (FIM) from the beginning of training. We argue it is an implicit regularizer in SGD by showing that explicitly penalizing the trace of the FIM can significantly improve generalization. We further show that the early value of the trace of the FIM correlates strongly with the final generalization. We highlight that in the absence of implicit or explicit regularization, the trace of the FIM can increase to a large value early in training, to which we refer as catastrophic Fisher explosion. Finally, to gain insight into the regularization effect of penalizing the trace of the FIM, we show that 1) it limits memorization by reducing the learning speed of examples with noisy labels more than that of the clean examples, and 2) trajectories with a low initial trace of the FIM end in flat minima, which are commonly associated with good generalization.
A Study on the Autoregressive and non-Autoregressive Multi-label Learning
Dec 03, 2020Extreme classification tasks are multi-label tasks with an extremely large number of labels (tags). These tasks are hard because the label space is usually (i) very large, e.g. thousands or millions of labels, (ii) very sparse, i.e. very few labels apply to each input document, and (iii) highly correlated, meaning that the existence of one label changes the likelihood of predicting all other labels. In this work, we propose a self-attention based variational encoder-model to extract the label-label and label-feature dependencies jointly and to predict labels for a given input. In more detail, we propose a non-autoregressive latent variable model and compare it to a strong autoregressive baseline that predicts a label based on all previously generated labels. Our model can therefore be used to predict all labels in parallel while still including both label-label and label-feature dependencies through latent variables, and compares favourably to the autoregressive baseline. We apply our models to four standard extreme classification natural language data sets, and one news videos dataset for automated label detection from a lexicon of semantic concepts. Experimental results show that although the autoregressive models, where use a given order of the labels for chain-order label prediction, work great for the small scale labels or the prediction of the highly ranked label, but our non-autoregressive model surpasses them by around 2% to 6% when we need to predict more labels, or the dataset has a larger number of the labels.
Differences between human and machine perception in medical diagnosis
Nov 28, 2020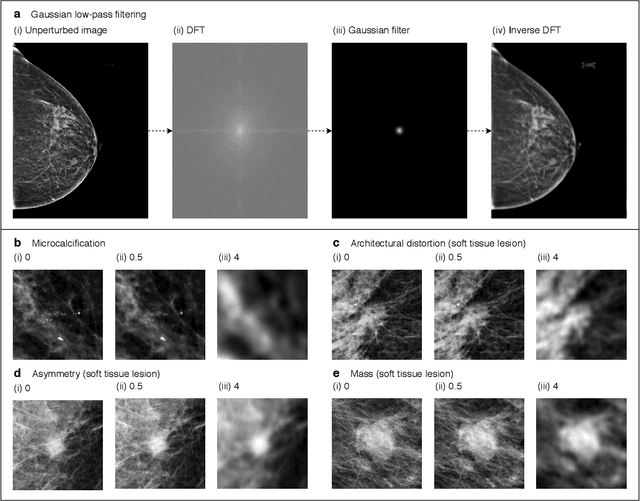
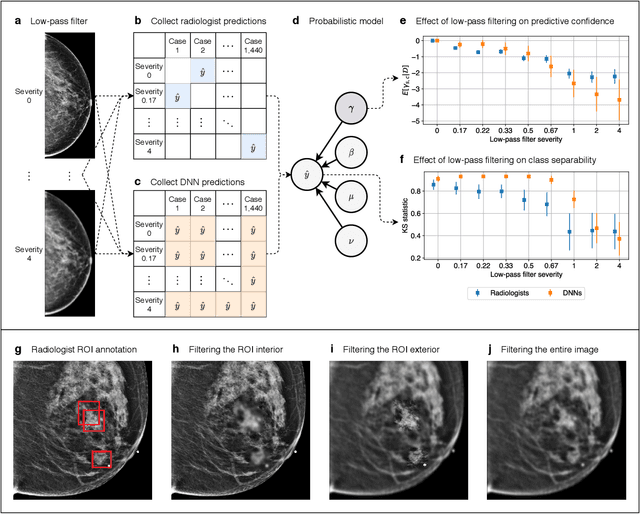
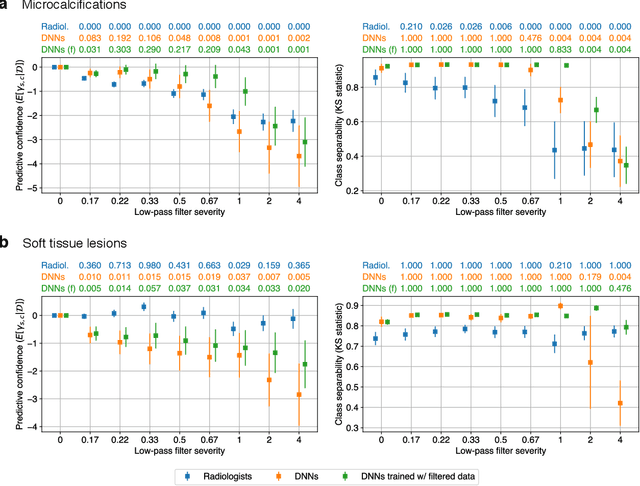
Deep neural networks (DNNs) show promise in image-based medical diagnosis, but cannot be fully trusted since their performance can be severely degraded by dataset shifts to which human perception remains invariant. If we can better understand the differences between human and machine perception, we can potentially characterize and mitigate this effect. We therefore propose a framework for comparing human and machine perception in medical diagnosis. The two are compared with respect to their sensitivity to the removal of clinically meaningful information, and to the regions of an image deemed most suspicious. Drawing inspiration from the natural image domain, we frame both comparisons in terms of perturbation robustness. The novelty of our framework is that separate analyses are performed for subgroups with clinically meaningful differences. We argue that this is necessary in order to avert Simpson's paradox and draw correct conclusions. We demonstrate our framework with a case study in breast cancer screening, and reveal significant differences between radiologists and DNNs. We compare the two with respect to their robustness to Gaussian low-pass filtering, performing a subgroup analysis on microcalcifications and soft tissue lesions. For microcalcifications, DNNs use a separate set of high frequency components than radiologists, some of which lie outside the image regions considered most suspicious by radiologists. These features run the risk of being spurious, but if not, could represent potential new biomarkers. For soft tissue lesions, the divergence between radiologists and DNNs is even starker, with DNNs relying heavily on spurious high frequency components ignored by radiologists. Importantly, this deviation in soft tissue lesions was only observable through subgroup analysis, which highlights the importance of incorporating medical domain knowledge into our comparison framework.
Learned Equivariant Rendering without Transformation Supervision
Nov 11, 2020


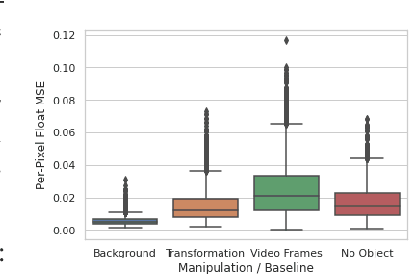
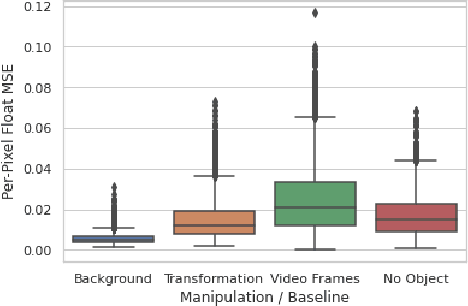
We propose a self-supervised framework to learn scene representations from video that are automatically delineated into objects and background. Our method relies on moving objects being equivariant with respect to their transformation across frames and the background being constant. After training, we can manipulate and render the scenes in real time to create unseen combinations of objects, transformations, and backgrounds. We show results on moving MNIST with backgrounds.
Improving Conversational Question Answering Systems after Deployment using Feedback-Weighted Learning
Nov 01, 2020
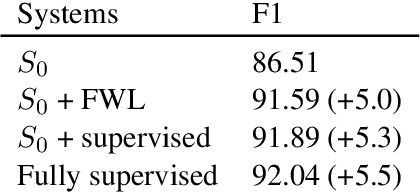

The interaction of conversational systems with users poses an exciting opportunity for improving them after deployment, but little evidence has been provided of its feasibility. In most applications, users are not able to provide the correct answer to the system, but they are able to provide binary (correct, incorrect) feedback. In this paper we propose feedback-weighted learning based on importance sampling to improve upon an initial supervised system using binary user feedback. We perform simulated experiments on document classification (for development) and Conversational Question Answering datasets like QuAC and DoQA, where binary user feedback is derived from gold annotations. The results show that our method is able to improve over the initial supervised system, getting close to a fully-supervised system that has access to the same labeled examples in in-domain experiments (QuAC), and even matching in out-of-domain experiments (DoQA). Our work opens the prospect to exploit interactions with real users and improve conversational systems after deployment.