 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRedPen: Region- and Reason-Annotated Dataset of Unnatural Speech
Oct 26, 2022Even with recent advances in speech synthesis models, the evaluation of such models is based purely on human judgement as a single naturalness score, such as the Mean Opinion Score (MOS). The score-based metric does not give any further information about which parts of speech are unnatural or why human judges believe they are unnatural. We present a novel speech dataset, RedPen, with human annotations on unnatural speech regions and their corresponding reasons. RedPen consists of 180 synthesized speeches with unnatural regions annotated by crowd workers; These regions are then reasoned and categorized by error types, such as voice trembling and background noise. We find that our dataset shows a better explanation for unnatural speech regions than the model-driven unnaturalness prediction. Our analysis also shows that each model includes different types of error types. Summing up, our dataset successfully shows the possibility that various error regions and types lie under the single naturalness score. We believe that our dataset will shed light on the evaluation and development of more interpretable speech models in the future. Our dataset will be publicly available upon acceptance.
StyLEx: Explaining Styles with Lexicon-Based Human Perception
Oct 14, 2022
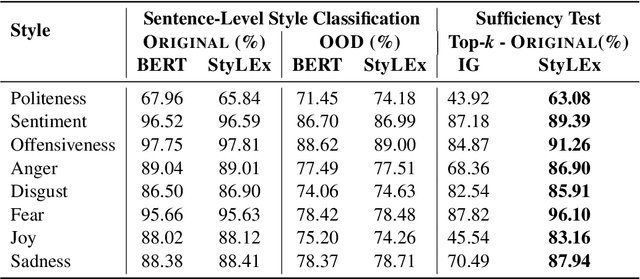
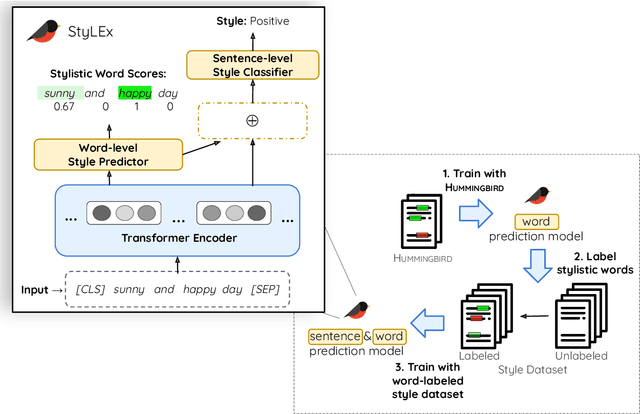
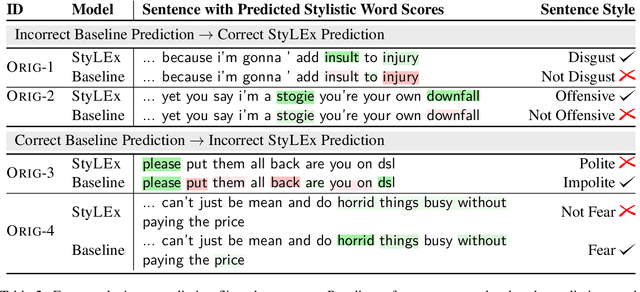
Style plays a significant role in how humans express themselves and communicate with others. Large pre-trained language models produce impressive results on various style classification tasks. However, they often learn spurious domain-specific words to make predictions. This incorrect word importance learned by the model often leads to ambiguous token-level explanations which do not align with human perception of linguistic styles. To tackle this challenge, we introduce StyLEx, a model that learns annotated human perceptions of stylistic lexica and uses these stylistic words as additional information for predicting the style of a sentence. Our experiments show that StyLEx can provide human-like stylistic lexical explanations without sacrificing the performance of sentence-level style prediction on both original and out-of-domain datasets. Explanations from StyLEx show higher sufficiency, and plausibility when compared to human annotations, and are also more understandable by human judges compared to the existing widely-used saliency baseline.
DailyTalk: Spoken Dialogue Dataset for Conversational Text-to-Speech
Jul 03, 2022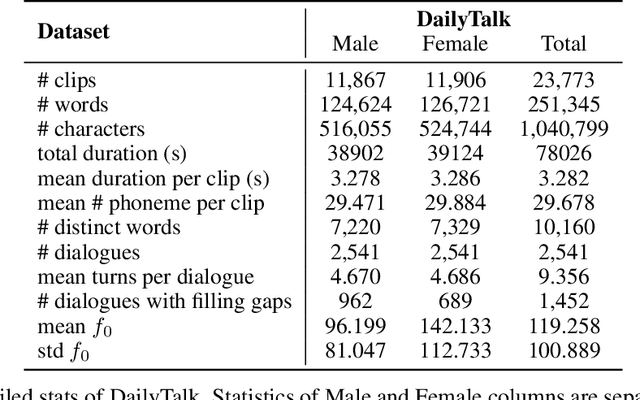
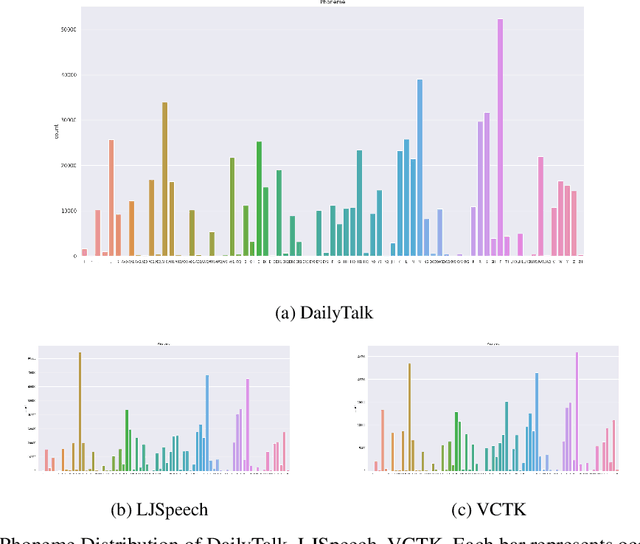

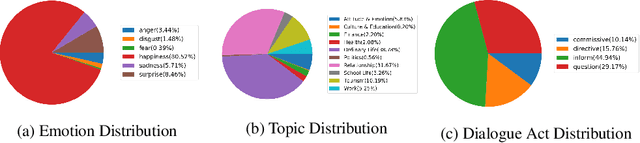
The majority of current TTS datasets, which are collections of individual utterances, contain few conversational aspects in terms of both style and metadata. In this paper, we introduce DailyTalk, a high-quality conversational speech dataset designed for Text-to-Speech. We sampled, modified, and recorded 2,541 dialogues from the open-domain dialogue dataset DailyDialog which are adequately long to represent context of each dialogue. During the data construction step, we maintained attributes distribution originally annotated in DailyDialog to support diverse dialogue in DailyTalk. On top of our dataset, we extend prior work as our baseline, where a non-autoregressive TTS is conditioned on historical information in a dialog. We gather metadata so that a TTS model can learn historical dialog information, the key to generating context-aware speech. From the baseline experiment results, we show that DailyTalk can be used to train neural text-to-speech models, and our baseline can represent contextual information. The DailyTalk dataset and baseline code are freely available for academic use with CC-BY-SA 4.0 license.
SSMix: Saliency-Based Span Mixup for Text Classification
Jun 15, 2021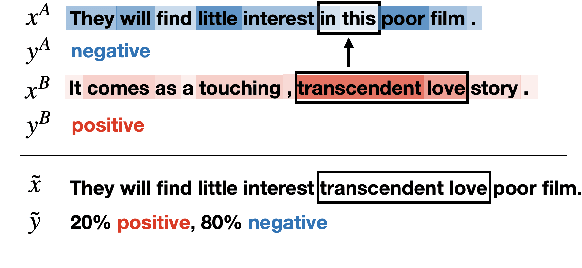
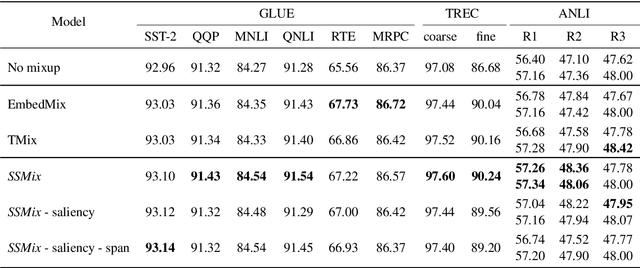
Data augmentation with mixup has shown to be effective on various computer vision tasks. Despite its great success, there has been a hurdle to apply mixup to NLP tasks since text consists of discrete tokens with variable length. In this work, we propose SSMix, a novel mixup method where the operation is performed on input text rather than on hidden vectors like previous approaches. SSMix synthesizes a sentence while preserving the locality of two original texts by span-based mixing and keeping more tokens related to the prediction relying on saliency information. With extensive experiments, we empirically validate that our method outperforms hidden-level mixup methods on a wide range of text classification benchmarks, including textual entailment, sentiment classification, and question-type classification. Our code is available at https://github.com/clovaai/ssmix.
KLUE: Korean Language Understanding Evaluation
Jun 11, 2021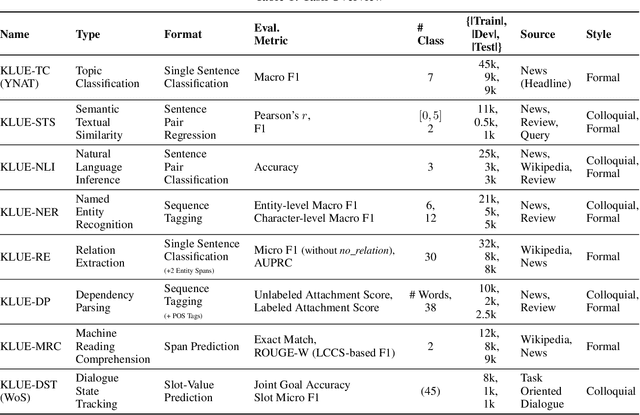
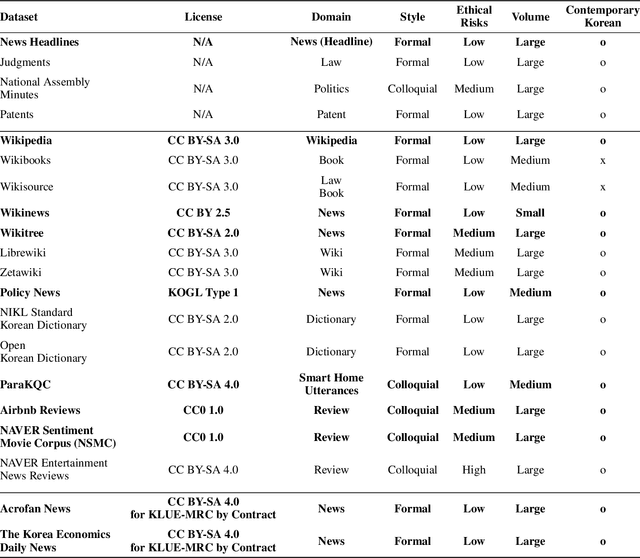
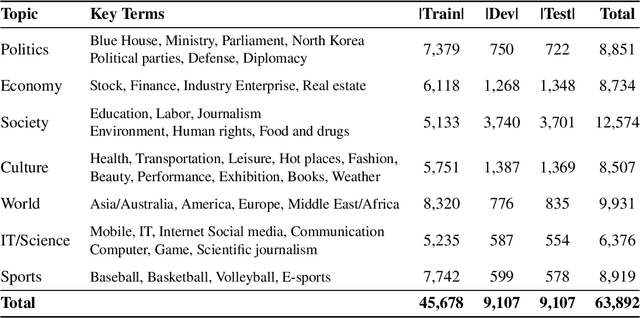
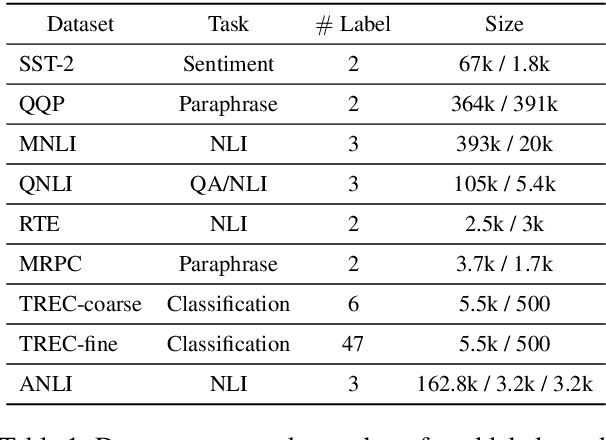
We introduce Korean Language Understanding Evaluation (KLUE) benchmark. KLUE is a collection of 8 Korean natural language understanding (NLU) tasks, including Topic Classification, SemanticTextual Similarity, Natural Language Inference, Named Entity Recognition, Relation Extraction, Dependency Parsing, Machine Reading Comprehension, and Dialogue State Tracking. We build all of the tasks from scratch from diverse source corpora while respecting copyrights, to ensure accessibility for anyone without any restrictions. With ethical considerations in mind, we carefully design annotation protocols. Along with the benchmark tasks and data, we provide suitable evaluation metrics and fine-tuning recipes for pretrained language models for each task. We furthermore release the pretrained language models (PLM), KLUE-BERT and KLUE-RoBERTa, to help reproducing baseline models on KLUE and thereby facilitate future research. We make a few interesting observations from the preliminary experiments using the proposed KLUE benchmark suite, already demonstrating the usefulness of this new benchmark suite. First, we find KLUE-RoBERTa-large outperforms other baselines, including multilingual PLMs and existing open-source Korean PLMs. Second, we see minimal degradation in performance even when we replace personally identifiable information from the pretraining corpus, suggesting that privacy and NLU capability are not at odds with each other. Lastly, we find that using BPE tokenization in combination with morpheme-level pre-tokenization is effective in tasks involving morpheme-level tagging, detection and generation. In addition to accelerating Korean NLP research, our comprehensive documentation on creating KLUE will facilitate creating similar resources for other languages in the future. KLUE is available at https://klue-benchmark.com.
STYLER: Style Factor Modeling with Rapidity and Robustness via Speech Decomposition for Expressive and Controllable Neural Text to Speech
Apr 04, 2021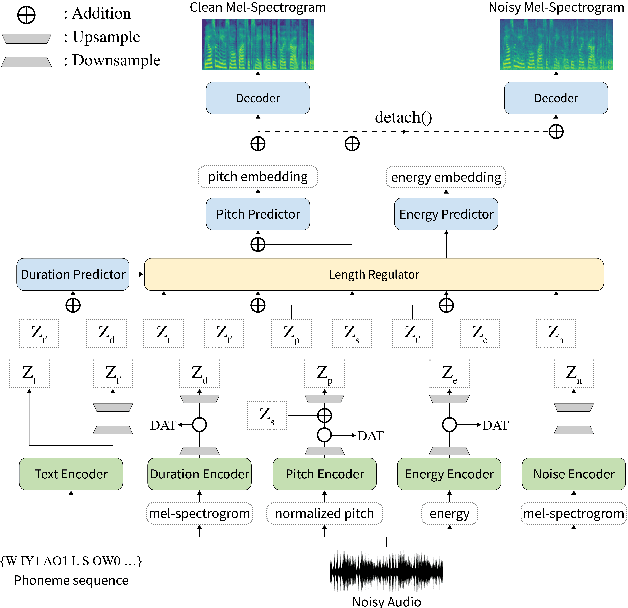
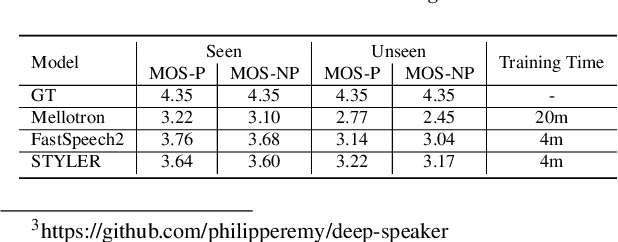
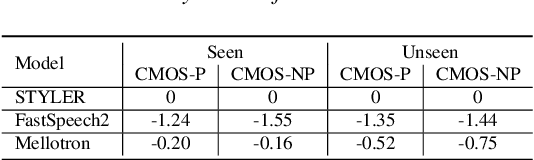
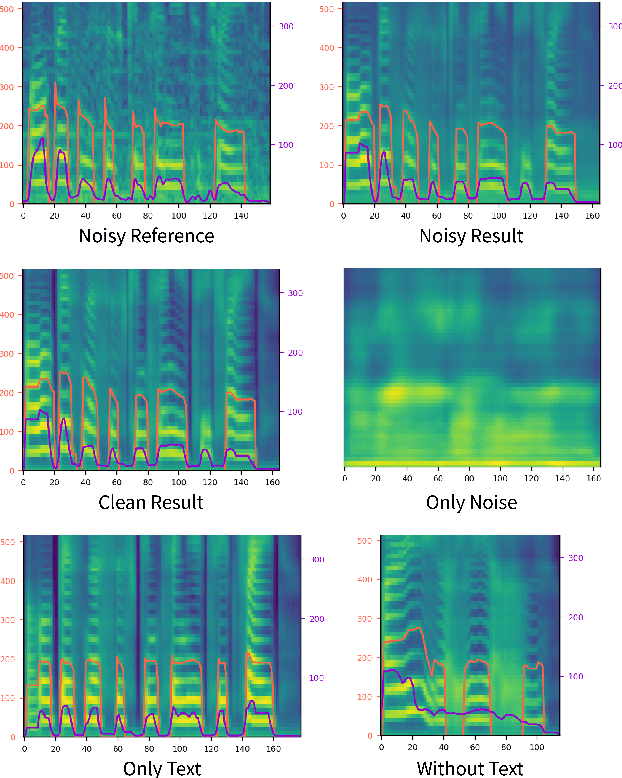
Previous works on neural text-to-speech (TTS) have been addressed on limited speed in training and inference time, robustness for difficult synthesis conditions, expressiveness, and controllability. Although several approaches resolve some limitations, there has been no attempt to solve all weaknesses at once. In this paper, we propose STYLER, an expressive and controllable TTS framework with high-speed and robust synthesis. Our novel audio-text aligning method called Mel Calibrator and excluding autoregressive decoding enable rapid training and inference and robust synthesis on unseen data. Also, disentangled style factor modeling under supervision enlarges the controllability in synthesizing process leading to expressive TTS. On top of it, a novel noise modeling pipeline using domain adversarial training and Residual Decoding empowers noise-robust style transfer, decomposing the noise without any additional label. Various experiments demonstrate that STYLER is more effective in speed and robustness than expressive TTS with autoregressive decoding and more expressive and controllable than reading style non-autoregressive TTS. Synthesis samples and experiment results are provided via our demo page, and code is available publicly.