 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion^2: Turning 3D Environments into Radio Frequency Heatmaps
Oct 02, 2025Modeling radio frequency (RF) signal propagation is essential for understanding the environment, as RF signals offer valuable insights beyond the capabilities of RGB cameras, which are limited by the visible-light spectrum, lens coverage, and occlusions. It is also useful for supporting wireless diagnosis, deployment, and optimization. However, accurately predicting RF signals in complex environments remains a challenge due to interactions with obstacles such as absorption and reflection. We introduce Diffusion^2, a diffusion-based approach that uses 3D point clouds to model the propagation of RF signals across a wide range of frequencies, from Wi-Fi to millimeter waves. To effectively capture RF-related features from 3D data, we present the RF-3D Encoder, which encapsulates the complexities of 3D geometry along with signal-specific details. These features undergo multi-scale embedding to simulate the actual RF signal dissemination process. Our evaluation, based on synthetic and real-world measurements, demonstrates that Diffusion^2 accurately estimates the behavior of RF signals in various frequency bands and environmental conditions, with an error margin of just 1.9 dB and 27x faster than existing methods, marking a significant advancement in the field. Refer to https://rfvision-project.github.io/ for more information.
VidGuard-R1: AI-Generated Video Detection and Explanation via Reasoning MLLMs and RL
Oct 02, 2025With the rapid advancement of AI-generated videos, there is an urgent need for effective detection tools to mitigate societal risks such as misinformation and reputational harm. In addition to accurate classification, it is essential that detection models provide interpretable explanations to ensure transparency for regulators and end users. To address these challenges, we introduce VidGuard-R1, the first video authenticity detector that fine-tunes a multi-modal large language model (MLLM) using group relative policy optimization (GRPO). Our model delivers both highly accurate judgments and insightful reasoning. We curate a challenging dataset of 140k real and AI-generated videos produced by state-of-the-art generation models, carefully designing the generation process to maximize discrimination difficulty. We then fine-tune Qwen-VL using GRPO with two specialized reward models that target temporal artifacts and generation complexity. Extensive experiments demonstrate that VidGuard-R1 achieves state-of-the-art zero-shot performance on existing benchmarks, with additional training pushing accuracy above 95%. Case studies further show that VidGuard-R1 produces precise and interpretable rationales behind its predictions. The code is publicly available at https://VidGuard-R1.github.io.
Real-Time Neural Video Recovery and Enhancement on Mobile Devices
Jul 22, 2023



As mobile devices become increasingly popular for video streaming, it's crucial to optimize the streaming experience for these devices. Although deep learning-based video enhancement techniques are gaining attention, most of them cannot support real-time enhancement on mobile devices. Additionally, many of these techniques are focused solely on super-resolution and cannot handle partial or complete loss or corruption of video frames, which is common on the Internet and wireless networks. To overcome these challenges, we present a novel approach in this paper. Our approach consists of (i) a novel video frame recovery scheme, (ii) a new super-resolution algorithm, and (iii) a receiver enhancement-aware video bit rate adaptation algorithm. We have implemented our approach on an iPhone 12, and it can support 30 frames per second (FPS). We have evaluated our approach in various networks such as WiFi, 3G, 4G, and 5G networks. Our evaluation shows that our approach enables real-time enhancement and results in a significant increase in video QoE (Quality of Experience) of 24\% - 82\% in our video streaming system.
NeuSaver: Neural Adaptive Power Consumption Optimization for Mobile Video Streaming
Jul 15, 2021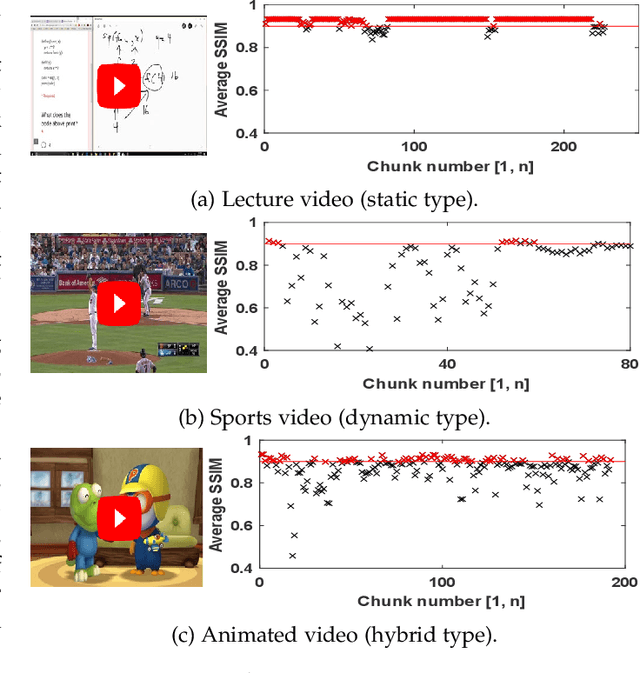
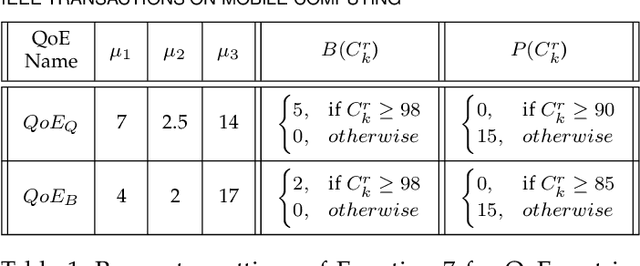
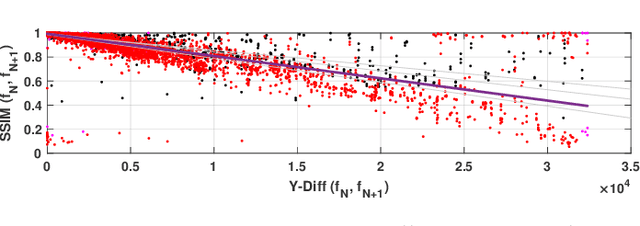

Video streaming services strive to support high-quality videos at higher resolutions and frame rates to improve the quality of experience (QoE). However, high-quality videos consume considerable amounts of energy on mobile devices. This paper proposes NeuSaver, which reduces the power consumption of mobile devices when streaming videos by applying an adaptive frame rate to each video chunk without compromising user experience. NeuSaver generates an optimal policy that determines the appropriate frame rate for each video chunk using reinforcement learning (RL). The RL model automatically learns the policy that maximizes the QoE goals based on previous observations. NeuSaver also uses an asynchronous advantage actor-critic algorithm to reinforce the RL model quickly and robustly. Streaming servers that support NeuSaver preprocesses videos into segments with various frame rates, which is similar to the process of creating videos with multiple bit rates in dynamic adaptive streaming over HTTP. NeuSaver utilizes the commonly used H.264 video codec. We evaluated NeuSaver in various experiments and a user study through four video categories along with the state-of-the-art model. Our experiments showed that NeuSaver effectively reduces the power consumption of mobile devices when streaming video by an average of 16.14% and up to 23.12% while achieving high QoE.