 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFINEMATCH: Aspect-based Fine-grained Image and Text Mismatch Detection and Correction
Apr 23, 2024



Recent progress in large-scale pre-training has led to the development of advanced vision-language models (VLMs) with remarkable proficiency in comprehending and generating multimodal content. Despite the impressive ability to perform complex reasoning for VLMs, current models often struggle to effectively and precisely capture the compositional information on both the image and text sides. To address this, we propose FineMatch, a new aspect-based fine-grained text and image matching benchmark, focusing on text and image mismatch detection and correction. This benchmark introduces a novel task for boosting and evaluating the VLMs' compositionality for aspect-based fine-grained text and image matching. In this task, models are required to identify mismatched aspect phrases within a caption, determine the aspect's class, and propose corrections for an image-text pair that may contain between 0 and 3 mismatches. To evaluate the models' performance on this new task, we propose a new evaluation metric named ITM-IoU for which our experiments show a high correlation to human evaluation. In addition, we also provide a comprehensive experimental analysis of existing mainstream VLMs, including fully supervised learning and in-context learning settings. We have found that models trained on FineMatch demonstrate enhanced proficiency in detecting fine-grained text and image mismatches. Moreover, models (e.g., GPT-4V, Gemini Pro Vision) with strong abilities to perform multimodal in-context learning are not as skilled at fine-grained compositional image and text matching analysis. With FineMatch, we are able to build a system for text-to-image generation hallucination detection and correction.
SCoRD: Subject-Conditional Relation Detection with Text-Augmented Data
Aug 24, 2023



We propose Subject-Conditional Relation Detection SCoRD, where conditioned on an input subject, the goal is to predict all its relations to other objects in a scene along with their locations. Based on the Open Images dataset, we propose a challenging OIv6-SCoRD benchmark such that the training and testing splits have a distribution shift in terms of the occurrence statistics of $\langle$subject, relation, object$\rangle$ triplets. To solve this problem, we propose an auto-regressive model that given a subject, it predicts its relations, objects, and object locations by casting this output as a sequence of tokens. First, we show that previous scene-graph prediction methods fail to produce as exhaustive an enumeration of relation-object pairs when conditioned on a subject on this benchmark. Particularly, we obtain a recall@3 of 83.8% for our relation-object predictions compared to the 49.75% obtained by a recent scene graph detector. Then, we show improved generalization on both relation-object and object-box predictions by leveraging during training relation-object pairs obtained automatically from textual captions and for which no object-box annotations are available. Particularly, for $\langle$subject, relation, object$\rangle$ triplets for which no object locations are available during training, we are able to obtain a recall@3 of 42.59% for relation-object pairs and 32.27% for their box locations.
Improving Visual Grounding by Encouraging Consistent Gradient-based Explanations
Jul 05, 2022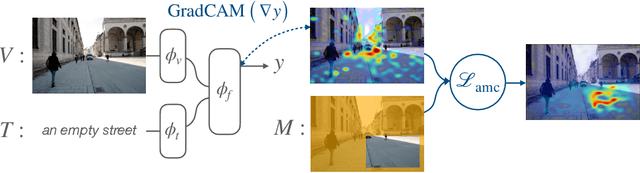
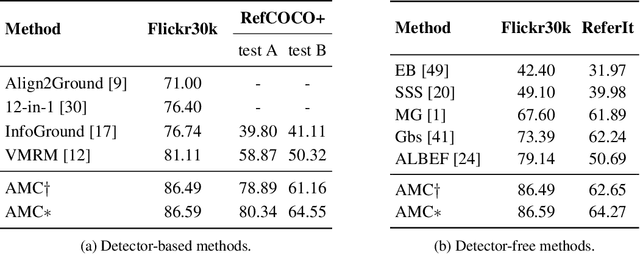
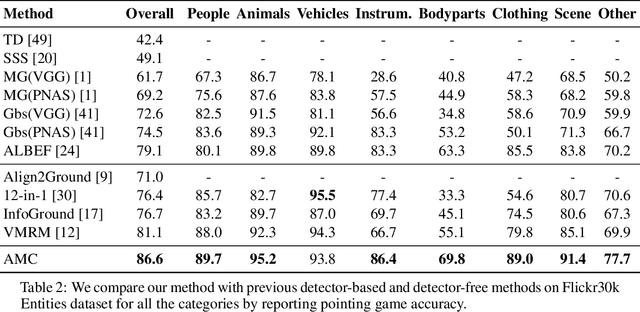

We propose a margin-based loss for vision-language model pretraining that encourages gradient-based explanations that are consistent with region-level annotations. We refer to this objective as Attention Mask Consistency (AMC) and demonstrate that it produces superior visual grounding performance compared to models that rely instead on region-level annotations for explicitly training an object detector such as Faster R-CNN. AMC works by encouraging gradient-based explanation masks that focus their attention scores mostly within annotated regions of interest for images that contain such annotations. Particularly, a model trained with AMC on top of standard vision-language modeling objectives obtains a state-of-the-art accuracy of 86.59% in the Flickr30k visual grounding benchmark, an absolute improvement of 5.48% when compared to the best previous model. Our approach also performs exceedingly well on established benchmarks for referring expression comprehension and offers the added benefit by design of gradient-based explanations that better align with human annotations.
OccamNets: Mitigating Dataset Bias by Favoring Simpler Hypotheses
Apr 11, 2022
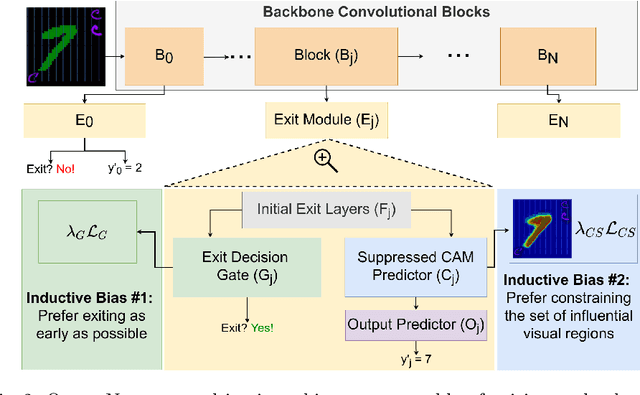


Dataset bias and spurious correlations can significantly impair generalization in deep neural networks. Many prior efforts have addressed this problem using either alternative loss functions or sampling strategies that focus on rare patterns. We propose a new direction: modifying the network architecture to impose inductive biases that make the network robust to dataset bias. Specifically, we propose OccamNets, which are biased to favor simpler solutions by design. OccamNets have two inductive biases. First, they are biased to use as little network depth as needed for an individual example. Second, they are biased toward using fewer image locations for prediction. While OccamNets are biased toward simpler hypotheses, they can learn more complex hypotheses if necessary. In experiments, OccamNets outperform or rival state-of-the-art methods run on architectures that do not incorporate these inductive biases. Furthermore, we demonstrate that when the state-of-the-art debiasing methods are combined with OccamNets results further improve.
Learning to Predict Visual Attributes in the Wild
Jun 17, 2021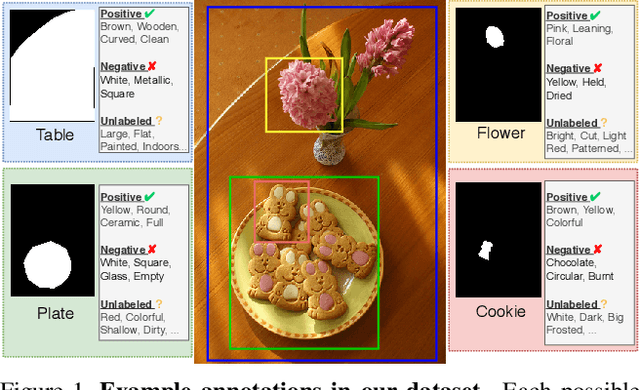

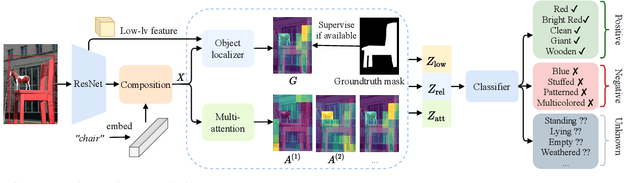
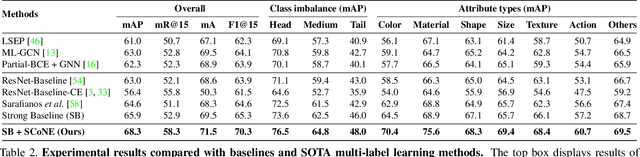
Visual attributes constitute a large portion of information contained in a scene. Objects can be described using a wide variety of attributes which portray their visual appearance (color, texture), geometry (shape, size, posture), and other intrinsic properties (state, action). Existing work is mostly limited to study of attribute prediction in specific domains. In this paper, we introduce a large-scale in-the-wild visual attribute prediction dataset consisting of over 927K attribute annotations for over 260K object instances. Formally, object attribute prediction is a multi-label classification problem where all attributes that apply to an object must be predicted. Our dataset poses significant challenges to existing methods due to large number of attributes, label sparsity, data imbalance, and object occlusion. To this end, we propose several techniques that systematically tackle these challenges, including a base model that utilizes both low- and high-level CNN features with multi-hop attention, reweighting and resampling techniques, a novel negative label expansion scheme, and a novel supervised attribute-aware contrastive learning algorithm. Using these techniques, we achieve near 3.7 mAP and 5.7 overall F1 points improvement over the current state of the art. Further details about the VAW dataset can be found at http://vawdataset.com/.
An Investigation of Critical Issues in Bias Mitigation Techniques
Apr 01, 2021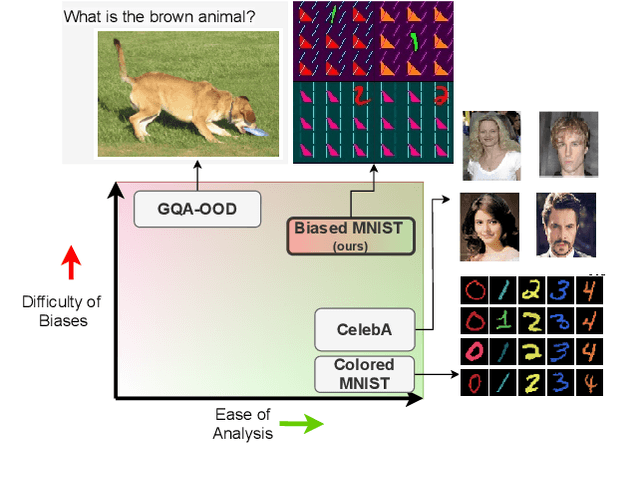
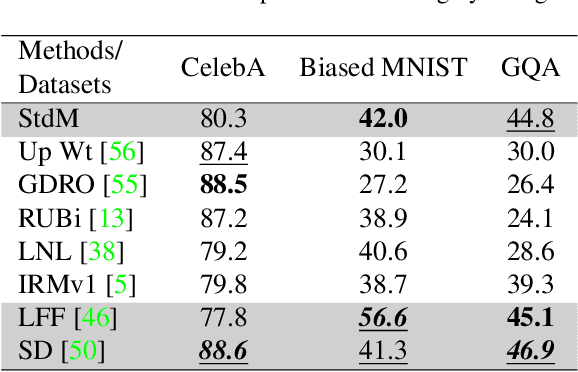
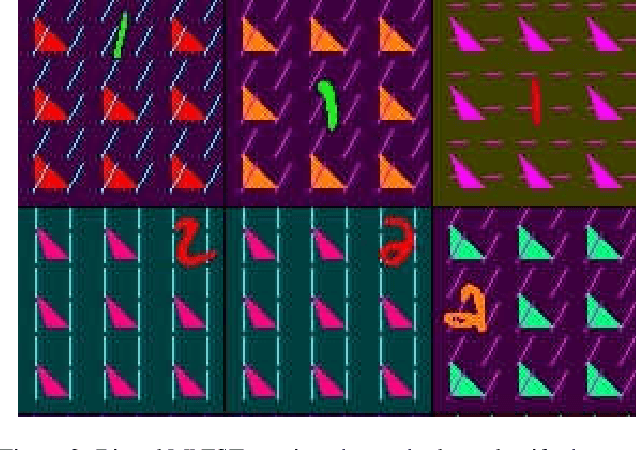
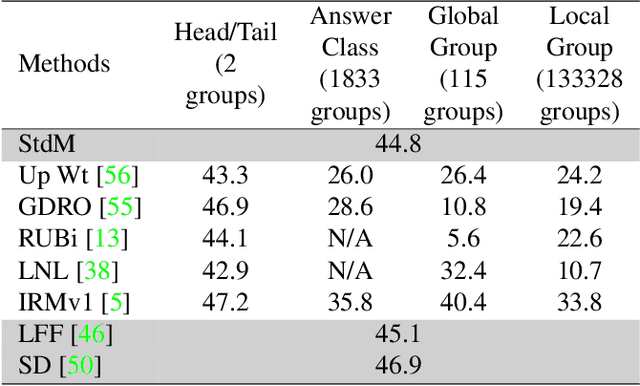
A critical problem in deep learning is that systems learn inappropriate biases, resulting in their inability to perform well on minority groups. This has led to the creation of multiple algorithms that endeavor to mitigate bias. However, it is not clear how effective these methods are. This is because study protocols differ among papers, systems are tested on datasets that fail to test many forms of bias, and systems have access to hidden knowledge or are tuned specifically to the test set. To address this, we introduce an improved evaluation protocol, sensible metrics, and a new dataset, which enables us to ask and answer critical questions about bias mitigation algorithms. We evaluate seven state-of-the-art algorithms using the same network architecture and hyperparameter selection policy across three benchmark datasets. We introduce a new dataset called Biased MNIST that enables assessment of robustness to multiple bias sources. We use Biased MNIST and a visual question answering (VQA) benchmark to assess robustness to hidden biases. Rather than only tuning to the test set distribution, we study robustness across different tuning distributions, which is critical because for many applications the test distribution may not be known during development. We find that algorithms exploit hidden biases, are unable to scale to multiple forms of bias, and are highly sensitive to the choice of tuning set. Based on our findings, we implore the community to adopt more rigorous assessment of future bias mitigation methods. All data, code, and results are publicly available at: https://github.com/erobic/bias-mitigators.
On the Value of Out-of-Distribution Testing: An Example of Goodhart's Law
May 19, 2020Out-of-distribution (OOD) testing is increasingly popular for evaluating a machine learning system's ability to generalize beyond the biases of a training set. OOD benchmarks are designed to present a different joint distribution of data and labels between training and test time. VQA-CP has become the standard OOD benchmark for visual question answering, but we discovered three troubling practices in its current use. First, most published methods rely on explicit knowledge of the construction of the OOD splits. They often rely on ``inverting'' the distribution of labels, e.g. answering mostly 'yes' when the common training answer is 'no'. Second, the OOD test set is used for model selection. Third, a model's in-domain performance is assessed after retraining it on in-domain splits (VQA v2) that exhibit a more balanced distribution of labels. These three practices defeat the objective of evaluating generalization, and put into question the value of methods specifically designed for this dataset. We show that embarrassingly-simple methods, including one that generates answers at random, surpass the state of the art on some question types. We provide short- and long-term solutions to avoid these pitfalls and realize the benefits of OOD evaluation.
Do We Need Fully Connected Output Layers in Convolutional Networks?
Apr 29, 2020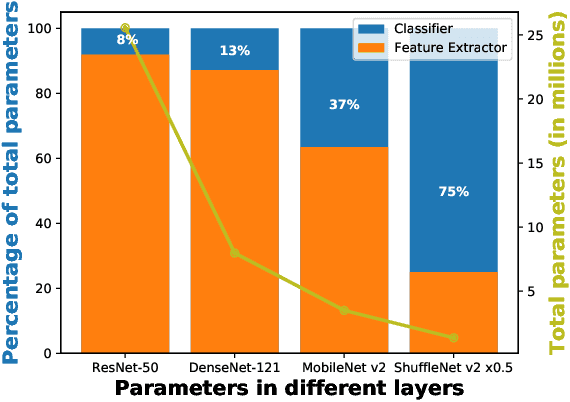
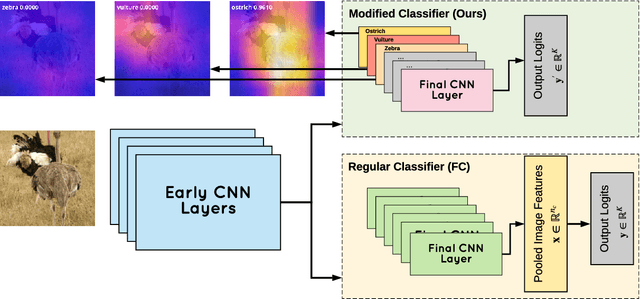
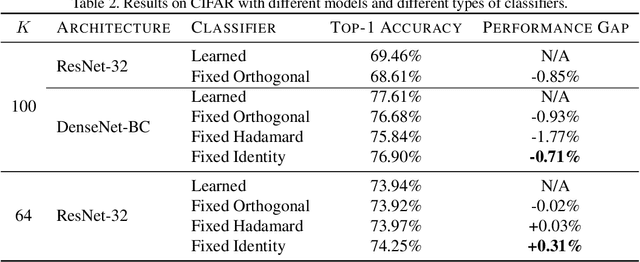
Traditionally, deep convolutional neural networks consist of a series of convolutional and pooling layers followed by one or more fully connected (FC) layers to perform the final classification. While this design has been successful, for datasets with a large number of categories, the fully connected layers often account for a large percentage of the network's parameters. For applications with memory constraints, such as mobile devices and embedded platforms, this is not ideal. Recently, a family of architectures that involve replacing the learned fully connected output layer with a fixed layer has been proposed as a way to achieve better efficiency. In this paper we examine this idea further and demonstrate that fixed classifiers offer no additional benefit compared to simply removing the output layer along with its parameters. We further demonstrate that the typical approach of having a fully connected final output layer is inefficient in terms of parameter count. We are able to achieve comparable performance to a traditionally learned fully connected classification output layer on the ImageNet-1K, CIFAR-100, Stanford Cars-196, and Oxford Flowers-102 datasets, while not having a fully connected output layer at all.
A negative case analysis of visual grounding methods for VQA
Apr 15, 2020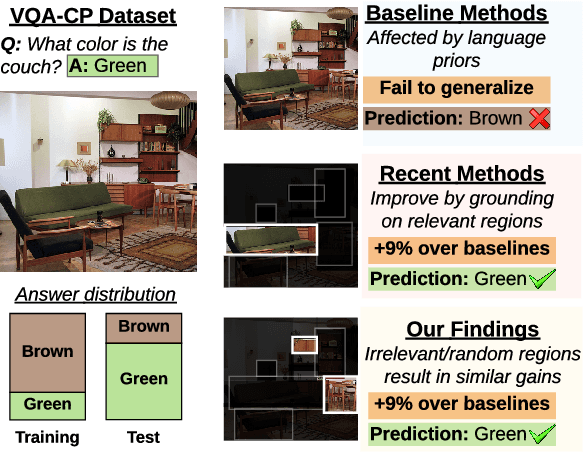
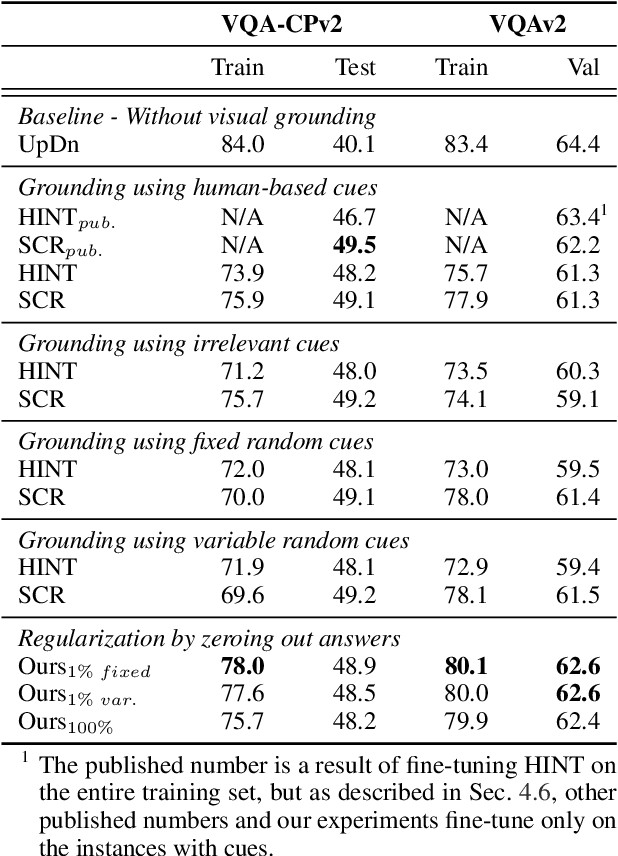
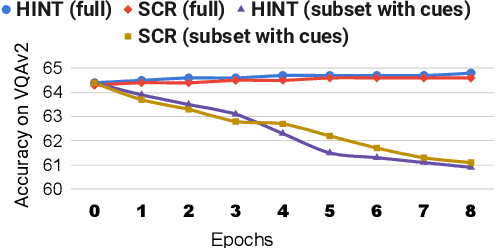

Existing Visual Question Answering (VQA) methods tend to exploit dataset biases and spurious statistical correlations, instead of producing right answers for the right reasons. To address this issue, recent bias mitigation methods for VQA propose to incorporate visual cues (e.g., human attention maps) to better ground the VQA models, showcasing impressive gains. However, we show that the performance improvements are not a result of improved visual grounding, but a regularization effect which prevents over-fitting to linguistic priors. For instance, we find that it is not actually necessary to provide proper, human-based cues; random, insensible cues also result in similar improvements. Based on this observation, we propose a simpler regularization scheme that does not require any external annotations and yet achieves near state-of-the-art performance on VQA-CPv2.
REMIND Your Neural Network to Prevent Catastrophic Forgetting
Oct 06, 2019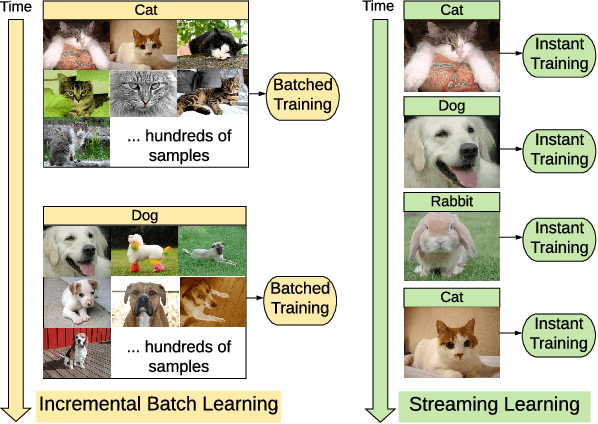
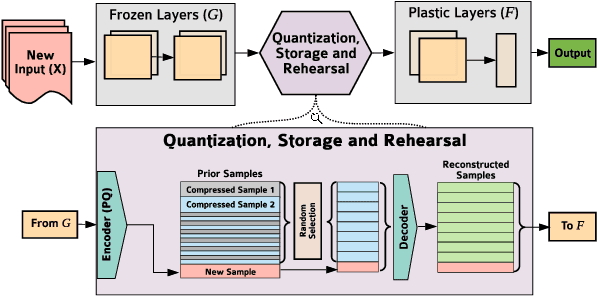
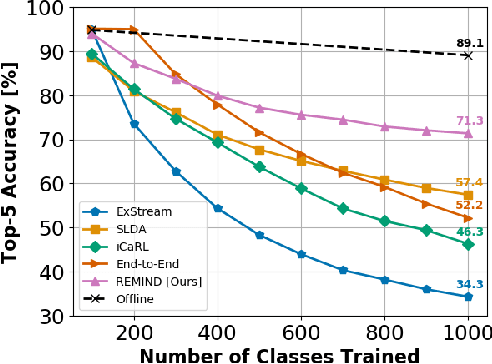
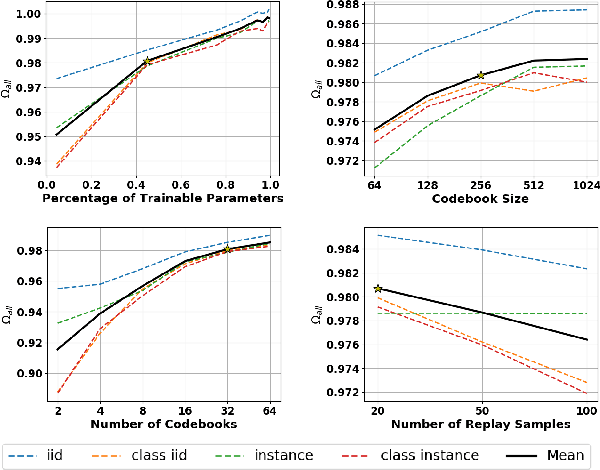
In lifelong machine learning, a robotic agent must be incrementally updated with new knowledge, instead of having distinct train and deployment phases. Conventional neural networks are often used for interpreting sensor data, however, if they are updated on non-stationary data streams, they suffer from catastrophic forgetting, with new learning overwriting past knowledge. A common remedy is replay, which involves mixing old examples with new ones. For incrementally training convolutional neural network models, prior work has enabled replay by storing raw images, but this is memory intensive and not ideal for embedded agents. Here, we propose REMIND, a tensor quantization approach that enables efficient replay with tensors. Unlike other methods, REMIND is trained in a streaming manner, meaning it learns one example at a time rather than in large batches containing multiple classes. Our approach achieves state-of-the-art results for incremental class learning on the ImageNet-1K dataset. We also probe REMIND's robustness to different data ordering schemes using the CORe50 streaming dataset. We demonstrate REMIND's generality by pioneering multi-modal incremental learning for visual question answering (VQA), which cannot be readily done with comparison models. We establish strong baselines on the CLEVR and TDIUC datasets for VQA. The generality of REMIND for multi-modal tasks can enable robotic agents to learn about their visual environment using natural language understanding in an interactive way.